nim anywhere
1.0.0

内部ユーザーの場合は #cdd-nim-anywhere のスラック チャネルに参加し、外部ユーザーの場合は問題を開いて質問やフィードバックを求めてください。
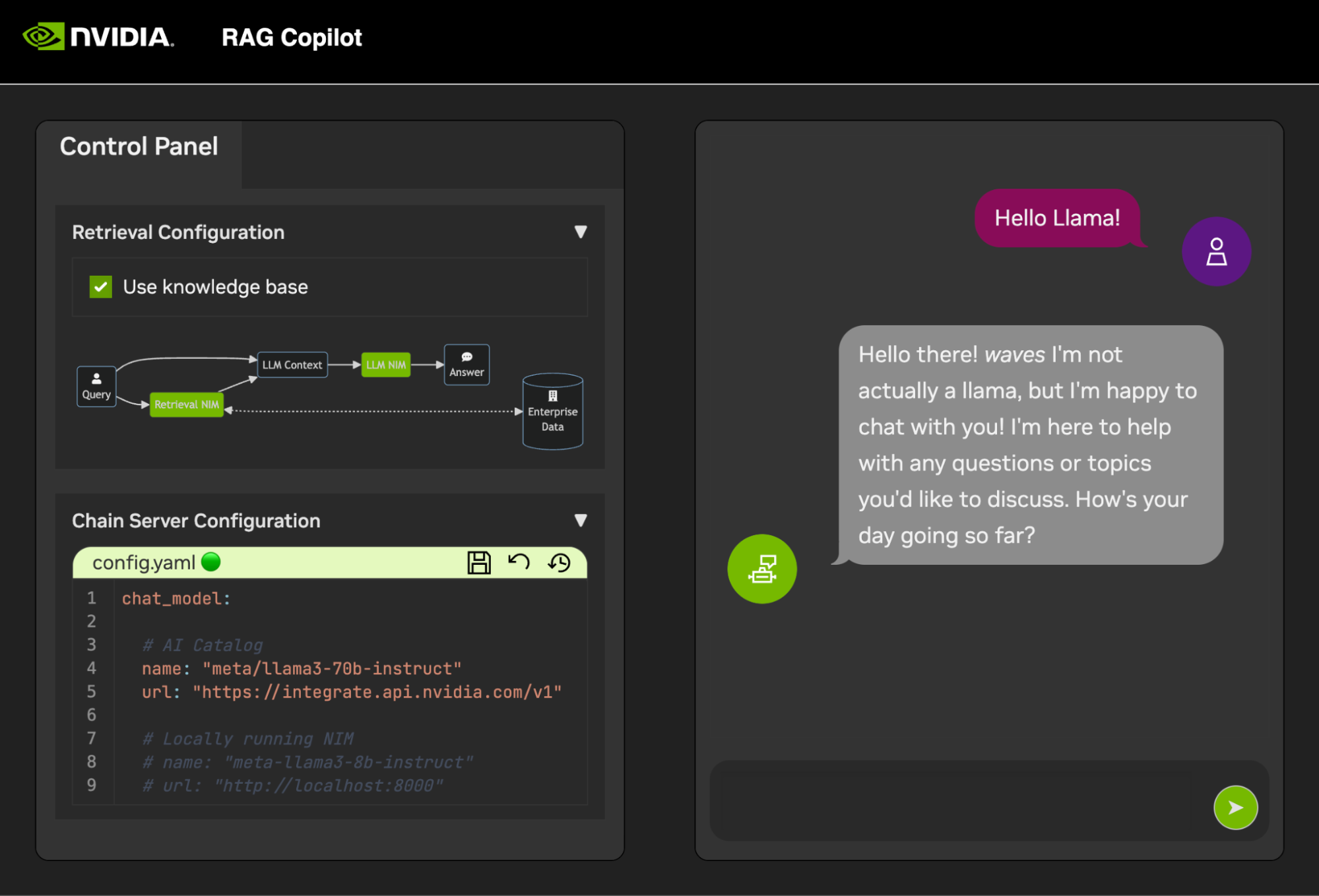
企業向け AI を使用する主な利点の 1 つは、内部データを操作し、内部データから学習できることです。検索拡張生成 (RAG) は、これを行うための最良の方法の 1 つです。 NVIDIA は、パートナーや顧客が効果的な RAG パイプラインを簡単に構築できるように、NIM マイクロサービスと呼ばれる一連のマイクロサービスを開発しました。
NIM Anywhere には、RAG 用の NIM の統合を開始するために必要なツールがすべて含まれています。フルサイズのラボから本番環境までネイティブにスケールアウトします。これは、RAG アーキテクチャを構築し、必要に応じて NIM を簡単に追加する場合に朗報です。 RAG に慣れていない方のために説明すると、RAG はモデル自体を変更することなく、推論中に関連する外部情報を動的に取得します。あなたが、機密の最新情報を含むローカル データベースを持つ会社の技術リーダーであると想像してください。 OpenAI がデータにアクセスすることは望ましくありませんが、質問に正確に答えるためにはモデルがデータを理解する必要があります。解決策は、言語モデルをデータベースに接続し、情報を提供することです。
RAG が生成 AI モデルの精度と信頼性を向上させる優れたソリューションである理由について詳しくは、このブログをご覧ください。
クイックスタート手順に従って、NIM Anywhere を今すぐ始めて、NIM を使用して最初の RAG アプリケーションを構築してください。
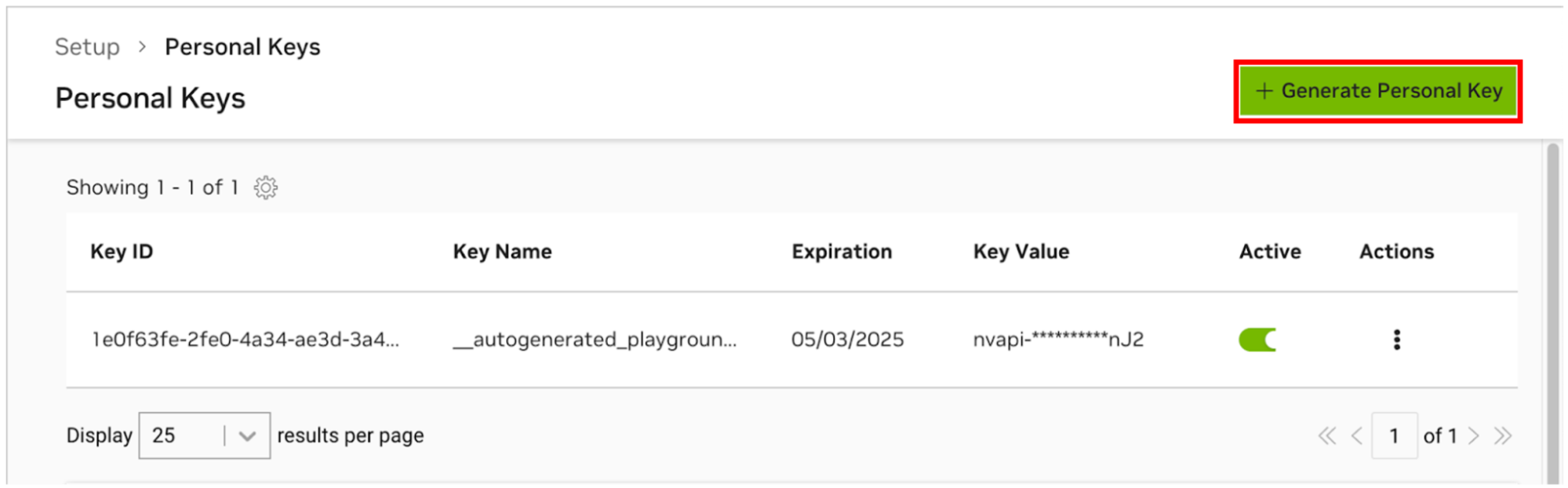
AI Workbench が NVIDIA のクラウド リソースにアクセスできるようにするには、AI Workbench に個人キーを提供する必要があります。これらのキーはnvapi-で始まります。
NGC パーソナル キー マネージャーに移動します。プロンプトが表示されたら、新しいアカウントを登録してサインインします。
ヒントこのツールを見つけるには、ngc.nvidia.com にログインし、右上のプロファイル メニューを展開し、 [セットアップ]を選択し、 [個人キーの生成]を選択します。
[個人キーの生成]を選択します。
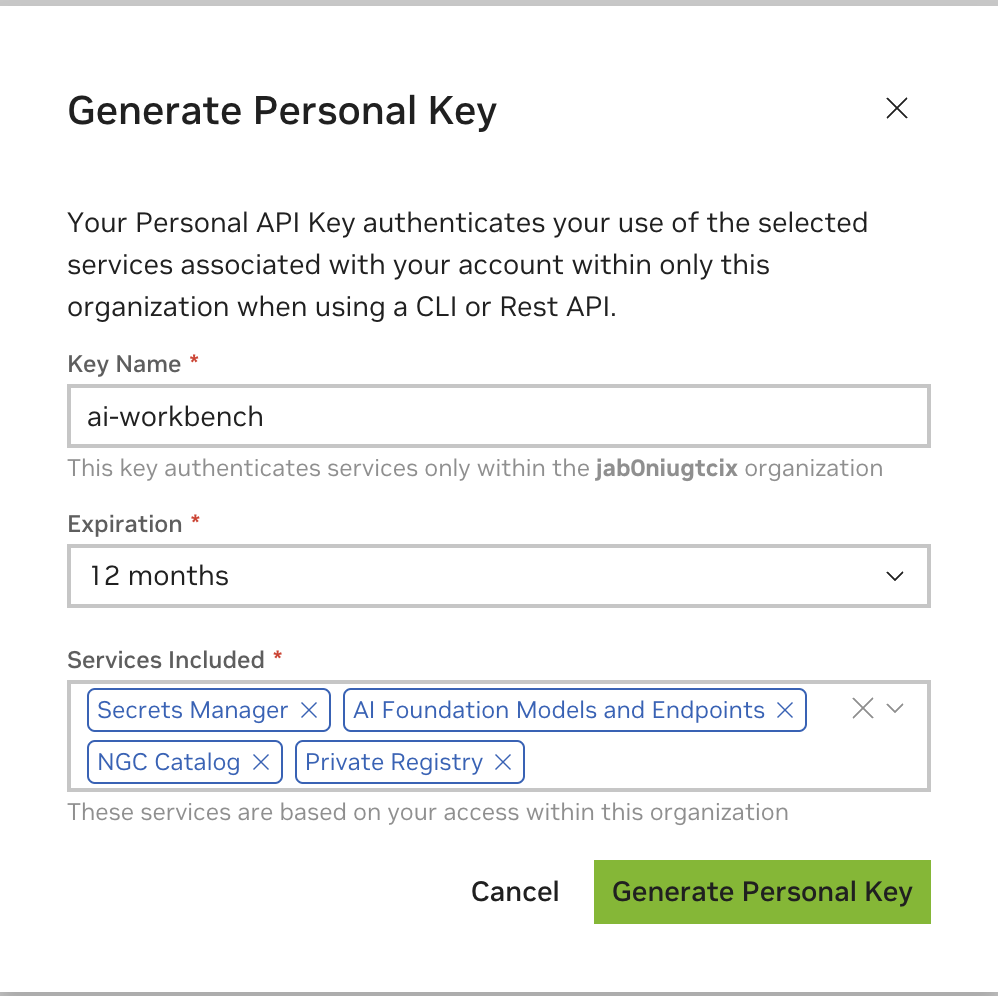
キー名として任意の値を入力し、有効期限は 12 か月で問題ありません。すべてのサービスを選択します。完了したら、 「個人キーの生成」を押します。
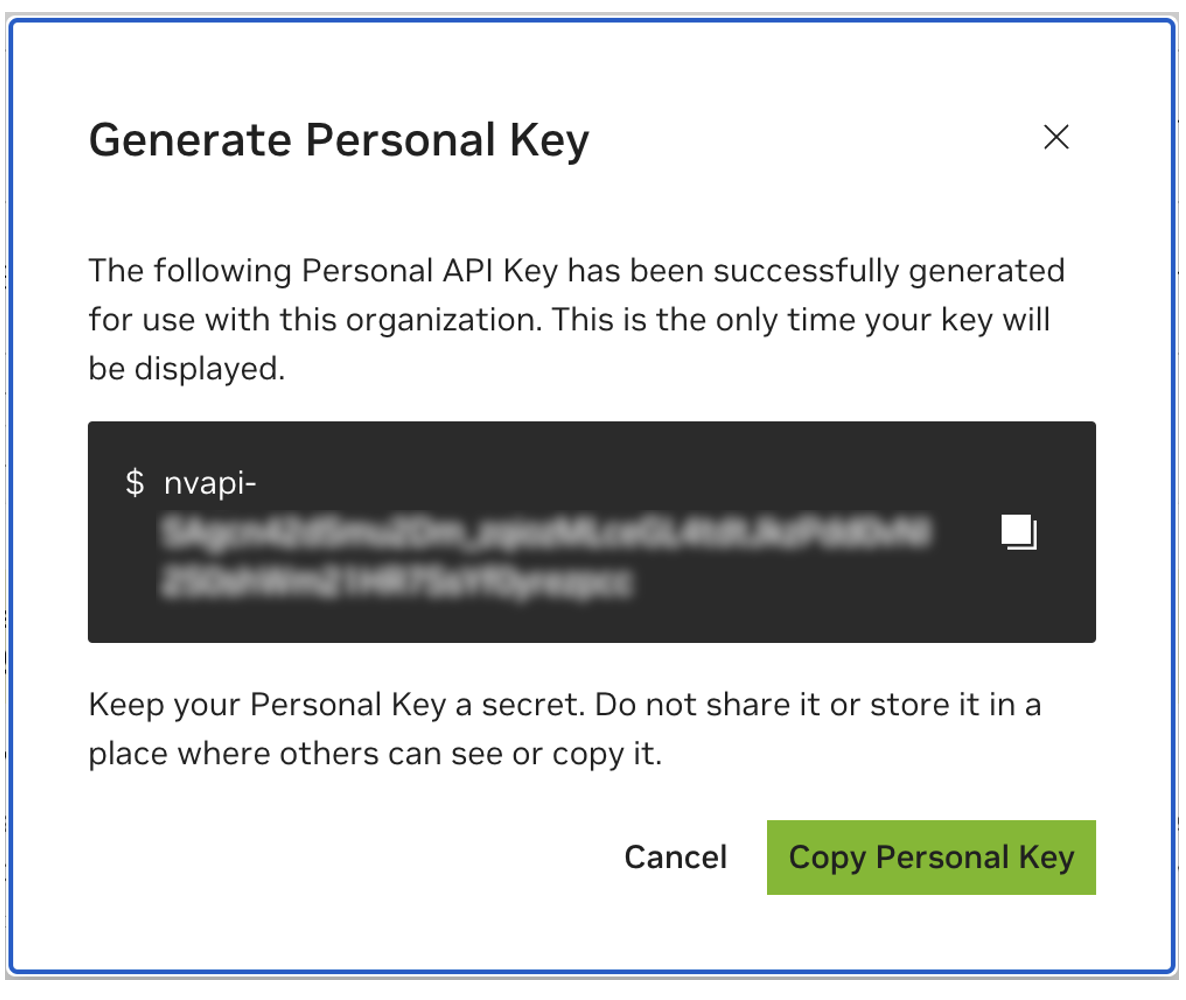
後で使用できるように個人キーを保存します。ワークベンチではこれが必要になりますが、後で取得する方法はありません。キーを紛失した場合は、新しいキーを作成する必要があります。このキーをパスワードのように保護します。
このプロジェクトは、NVIDIA AI Workbench で使用するように設計されています。これは必須ではありませんが、AI Workbench を使用せずにこのデモを実行すると、事前構成された自動化と統合が利用できない可能性があるため、手動作業が必要になります。
このクイック スタート ガイドでは、リモート ラボ マシンが開発に使用されており、ローカル マシンが開発マシンにリモートでアクセスするためのシンクライアントであることを前提としています。これにより、コンピューティング リソースが集中的に配置され、開発者は移植性が向上します。リモート ラボ マシンは Ubuntu を実行する必要がありますが、ローカル クライアントは Windows、MacOS、または Ubuntu を実行できることに注意してください。このプロジェクトをローカルのみにインストールするには、リモート インストールをスキップしてください。
フローチャート LR
地元
サブグラフのラボ環境
リモートラボマシン
終わり
ローカル <-.ssh.-> リモートラボマシン
ローカル クライアントを開発にも使用する場合は、Ubuntu が必要です。リモート ラボ マシンを使用する場合は、Windows、MacOS、または Ubuntu を使用できます。
完全な手順については、NVIDIA AI Workbench ユーザー ガイドを参照してください。
前提条件のソフトウェアをインストールする
NVIDIA AI Workbench インストーラーをダウンロードして実行します。インストーラーが変更を行えるように Windows を承認します。
インストール ウィザードの指示に従います。 WSL2 をインストールする必要がある場合は、Windows に変更を許可し、要求に応じてローカル マシンを再起動します。システムが再起動すると、NVIDIA AI Workbench インストーラーが自動的に再開されます。
コンテナー ランタイムとして Docker を選択します。
「GitHub.com 経由でサインイン」オプションを使用して、GitHub アカウントにログインします。
要求された場合は、Git 作成者情報を入力します。
完全な手順については、NVIDIA AI Workbench ユーザー ガイドを参照してください。
前提条件のソフトウェアをインストールする
NVIDIA AI Workbench ディスク イメージ ( .dmgファイル) をダウンロードして開きます。
AI Workbench をアプリケーション フォルダーにドラッグし、アプリケーション ランチャーからNVIDIA AI Workbenchを実行します。 
コンテナー ランタイムとして Docker を選択します。
「GitHub.com 経由でサインイン」オプションを使用して、GitHub アカウントにログインします。
要求された場合は、Git 作成者情報を入力します。
完全な手順については、NVIDIA AI Workbench ユーザー ガイドを参照してください。このインストールは、ユーザー Workbench となるユーザーとして実行します。これらの手順をrootとして実行しないでください。
前提条件のソフトウェアをインストールする
NVIDIA AI Workbench インストーラーをダウンロードし、実行可能にしてから実行します。次のコマンドを使用してファイルを実行可能にできます。
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench は、(必要に応じて) NVIDIA ドライバーをインストールします。ドライバーのインストール後にローカル マシンを再起動し、デスクトップ上の NVIDIA AI Workbench アイコンをダブルクリックして AI Workbench のインストールを再開する必要があります。
コンテナー ランタイムとして Docker を選択します。
「GitHub.com 経由でサインイン」オプションを使用して、GitHub アカウントにログインします。
要求された場合は、Git 作成者情報を入力します。
リモート マシンでは Ubuntu のみがサポートされます。
完全な手順については、NVIDIA AI Workbench ユーザー ガイドを参照してください。 Workbench を使用するユーザーとしてこのインストールを実行します。これらの手順をrootとして実行しないでください。
ローカル マシンからリモート マシンへの SSH キー ベースの認証が有効になっていることを確認します。これが現在有効になっていない場合は、次のコマンドを実行すると、ほとんどの状況で有効になります。 REMOTE_USERとREMOTE-MACHINE変更して、リモート アドレスを反映させます。
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINEリモート ホストに SSH で接続します。次に、次のコマンドを使用して、NVIDIA AI Workbench インストーラーをダウンロードして実行します。
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench は、(必要に応じて) NVIDIA ドライバーをインストールします。ドライバーのインストール後にリモート マシンを再起動し、前の手順のコマンドを再実行して AI Workbench のインストールを再開する必要があります。
コンテナー ランタイムとして Docker を選択します。
「GitHub.com 経由でサインイン」オプションを使用して、GitHub アカウントにログインします。
要求された場合は、Git 作成者情報を入力します。
リモート インストールが完了すると、リモート ロケーションをローカル AI Workbench インスタンスに追加できます。 AI Workbench アプリケーションを開き、 [リモート ロケーションの追加]をクリックして、必要な情報を入力します。完了したら、 「場所の追加」をクリックします。
REMOTE-MACHINEと同じになるはずです。REMOTE_USERと同じになるはずです。/home/USER/.ssh/id_rsaになるはずです。このプロジェクトをローカルで使用するためにダウンロードするには、クローン作成とフォークという 2 つの方法があります。
このリポジトリのクローンを作成することから始めることをお勧めします。これによりローカルでの変更はできませんが、最も早く開始できます。これにより、更新を取得する最も簡単な方法も可能になります。
変更を保存できるため、開発にはこのリポジトリをフォークすることをお勧めします。ただし、更新を取得するには、フォーク管理者は上流のリポジトリから定期的に取得する必要があります。フォークから作業するには、GitHub の手順に従い、このセクションの残りの部分で個人用フォークへの URL を参照します。
ローカルの NVIDIA AI ワークベンチ ウィンドウを開きます。表示された場所のリストから、セットアップしたばかりのリモートを選択するか、ローカルで作業する場合はローカルを選択します。
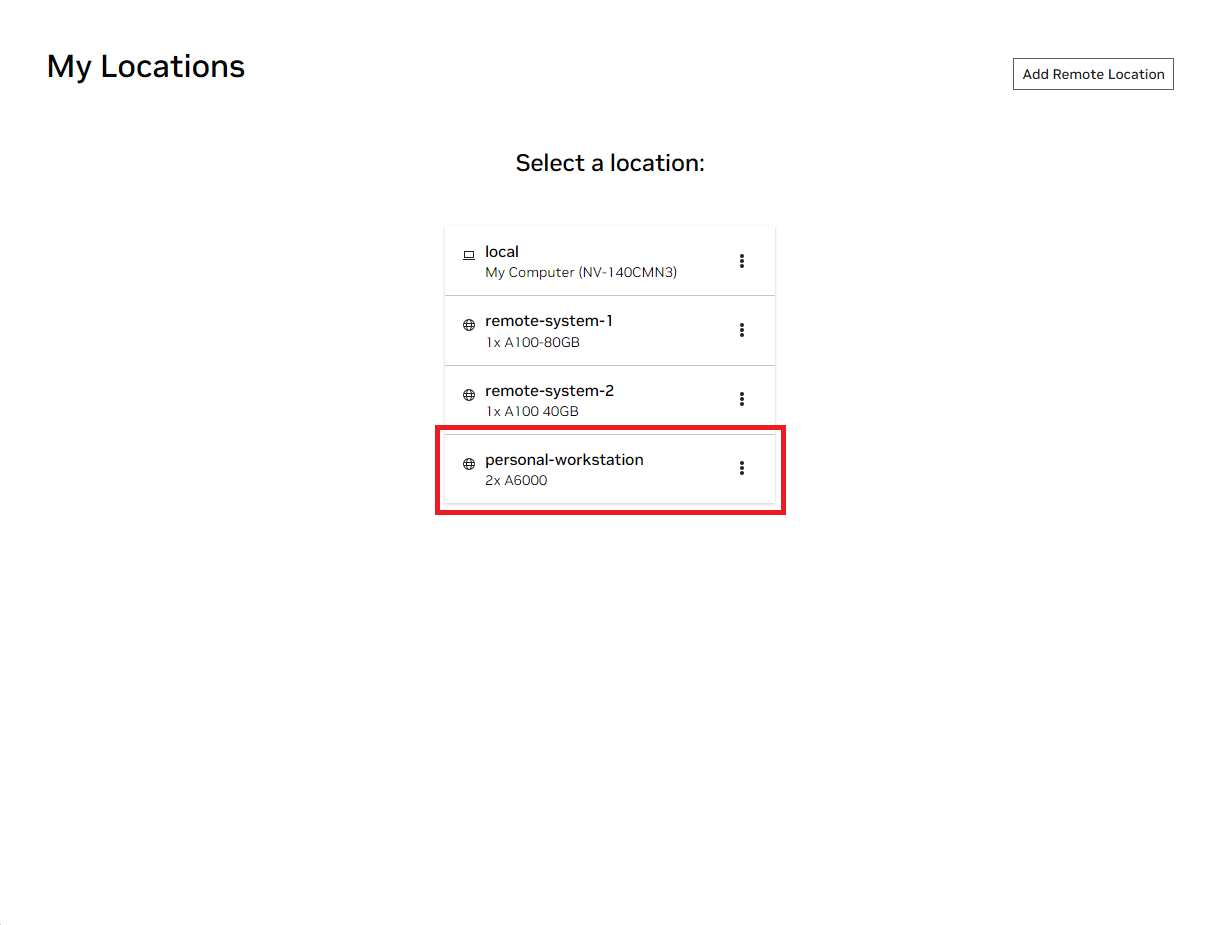
その場所に入ったら、 [Clone Project]を選択します。
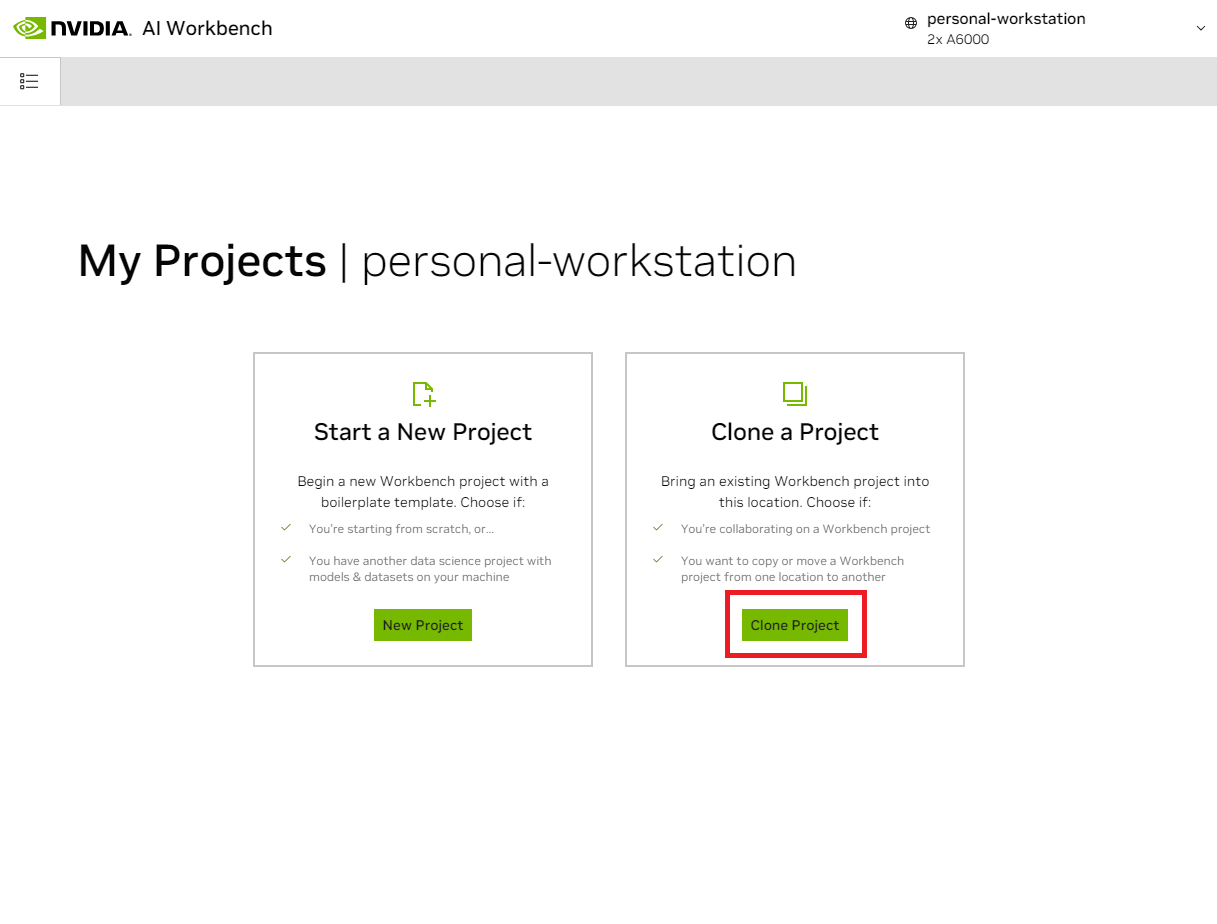
「Clone Project」ポップアップウィンドウで、リポジトリ URL をhttps://github.com/NVIDIA/nim-anywhere.gitに設定します。パスはデフォルトの/home/REMOTE_USER/nvidia-workbench/nim-anywhere.gitのままにすることができます。 「クローン」をクリックします。
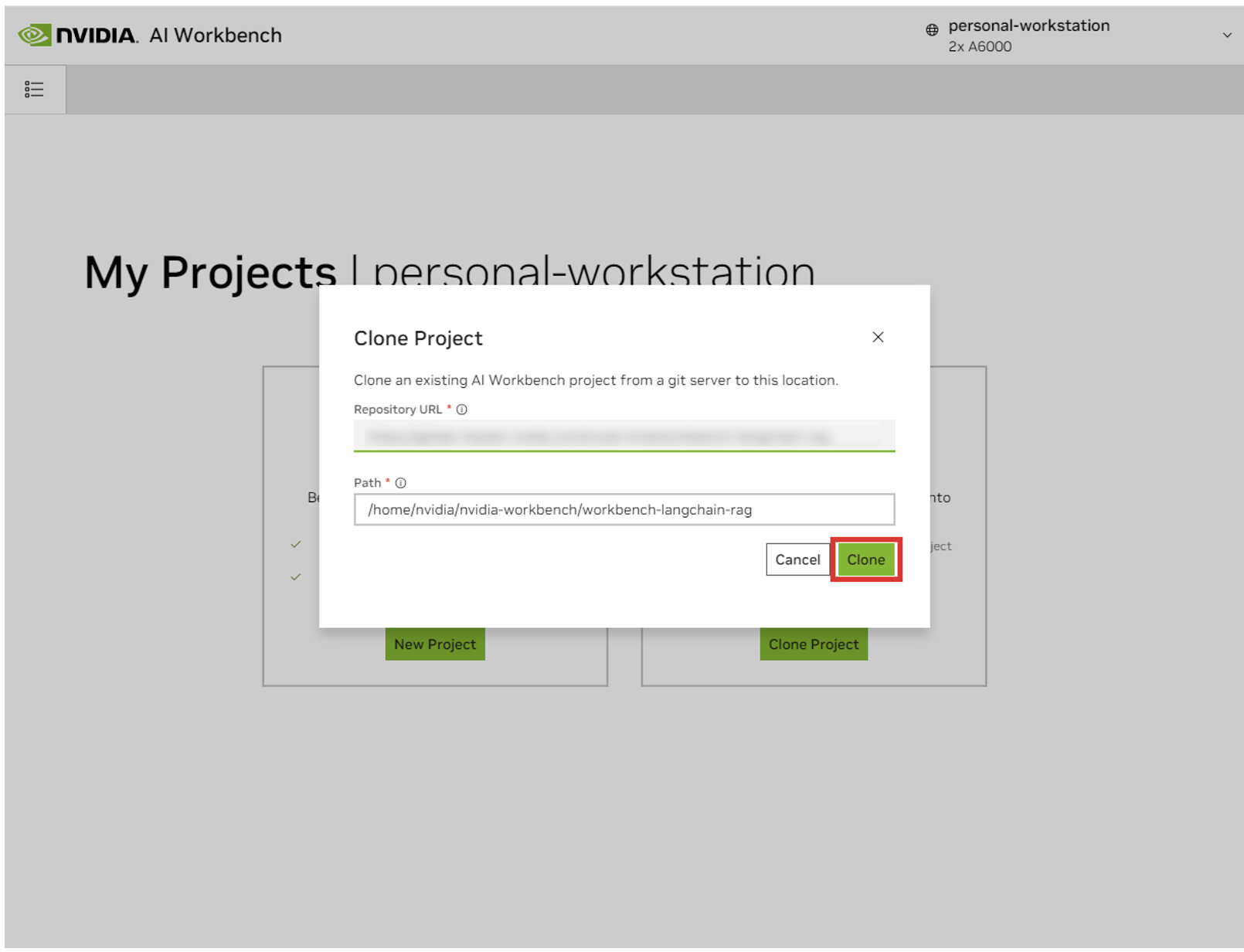
新しいプロジェクトのページにリダイレクトされます。ワークベンチは開発環境を自動的にブートストラップします。ウィンドウの下部から出力を展開すると、リアルタイムの進行状況を確認できます。
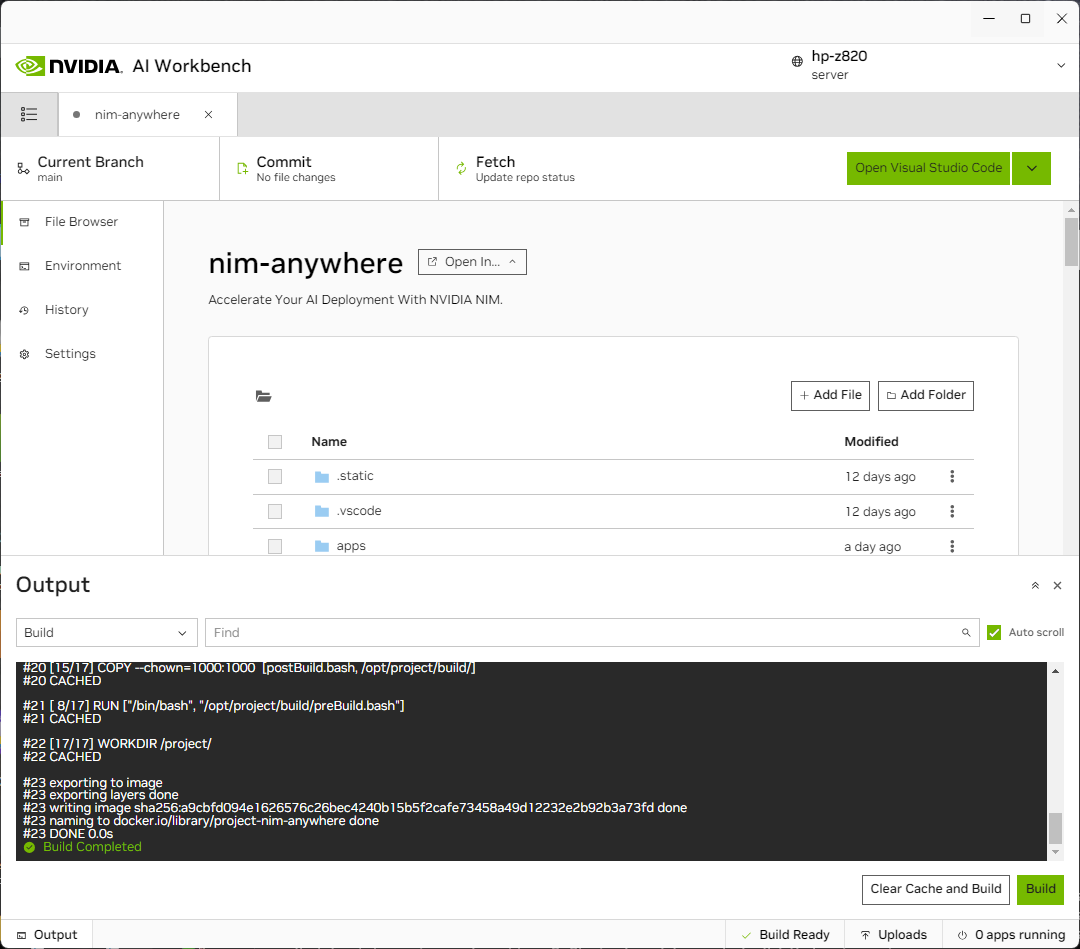
プロジェクトは、ローカル マシン リソースで動作するように構成する必要があります。
初めて実行する前に、プロジェクト固有の構成を提供する必要があります。プロジェクトの設定は、左側のパネルの[環境]タブを使用して行います。
「変数」セクションまで下にスクロールし、 NGC_HOMEエントリーを見つけます。 ~/.cache/nvidia-nimsのようなものに設定する必要があります。ここの値はワークベンチによって使用されます。これと同じ場所が、このディレクトリをコンテナにマウントする「マウント」セクションにも表示されます。
「Secrets」セクションまで下にスクロールして、 NGC_API_KEYエントリーを見つけます。 [構成]を押して、前に生成した NGC の個人キーを入力します。
「マウント」セクションまで下にスクロールします。ここでは、構成するマウントが 2 つあります。
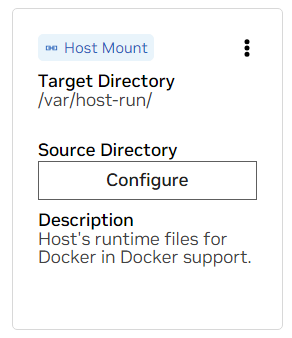
a. /var/host-run のマウントを見つけます。これは、開発環境が Docker から Docker と呼ばれるパターンでホストの Docker デーモンにアクセスできるようにするために使用されます。 「Configure」を押して、ディレクトリ/var/runを指定します。
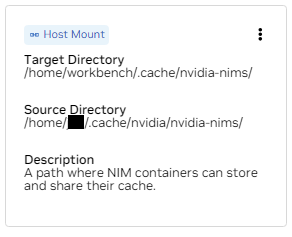
b. /home/workbench/.cache/nvidia-nims のマウントを見つけます。このマウントは、モデル ファイルをキャッシュできる NIM のランタイム キャッシュとして使用されます。このキャッシュをホストと共有すると、ディスクの使用量とネットワーク帯域幅が削減されます。
nim キャッシュがまだない場合、または不明な場合は、次のコマンドを使用して/home/USER/.cache/nvidia-nimsに作成します。
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsこれらの設定を変更した後、再構築が行われます。
ビルドが完了して「Build Ready 」メッセージが表示されると、すべてのアプリケーションが使用できるようになります。
最も基本的な LLM チェーンでさえ、いくつかの追加のマイクロサービスに依存します。これらは、メモリ内の代替手段の開発中に無視できますが、運用環境に移行するにはコードの変更が必要になります。ありがたいことに、Workbench は開発環境用の追加のマイクロサービスを管理します。
ヒント:各アプリケーションのデバッグ出力は、左下隅にある [出力] リンクをクリックし、ドロップダウン メニューを選択して、対象のアプリケーションを選択することで UI で監視できます。
このワークスペースにバンドルされているすべてのアプリケーションは、 [環境] > [アプリケーション]に移動して制御できます。
まず、 Milvus Vector DBとRedis をオンに切り替えます。 Milvus は非構造化ナレッジ ベースとして使用され、Redis は会話履歴の保存に使用されます。
これらのサービスが開始されると、 Chain Server を安全に開始できます。これには、推論チェーンを実行するためのカスタム LangChain コードが含まれています。デフォルトでは、ローカルの Milvus と Redis を使用しますが、LLM と埋め込みモデルの推論にはai.nvidia.com を使用します。
[オプション]:次に、 LLM NIM を開始します。 LLM NIM を初めて起動するときは、イメージと最適化されたモデルをダウンロードするのに時間がかかります。
a.長時間の起動中に、LLM NIM が開始していることを確認するには、UI の左下にある出力ペインを使用してログを表示し、進行状況を観察できます。
b.ログに認証エラーが示されている場合は、指定されたNGC_API_KEY がNIM にアクセスできないことを意味します。これが正しく生成され、NVIDIA AI Enterprise サポートまたはトライアルを提供する NGC 組織で生成されたことを確認してください。
c.ログが..........: Pull complete 。 ..........: Verifying complete 、または..........: Download complete 。これはすべて、コンテナー イメージのさまざまなレイヤーがダウンロードされたことを示す Docker からの通常の出力です。
d.ここで他の障害が発生した場合は、対処する必要があります。
チェーン サーバーが起動すると、チャット インターフェイスを開始できます。インターフェイスを開始すると、ブラウザ ウィンドウでインターフェイスが自動的に開きます。
デモの開発を始めるために、データがどのように Vector データベースに取り込まれるかを示すサンプル データセットが Jupyter Notebook とともに提供されます。
PDF ドキュメントを Vector データベースにインポートするには、AI Workbench のアプリ ランチャーを使用して Jupyter を開きます。
code/upload-pdfs.ipynbにある Jupyter Notebook を使用して、デフォルトのデータセットを取り込みます。デフォルトのデータセットを使用する場合は、変更する必要はありません。
カスタム データセットを使用する場合は、それを Jupyter のdata/ディレクトリにアップロードし、必要に応じて提供されたノートブックを変更します。
このプロジェクトには、いくつかのデモ サービス用のアプリケーションと外部サービスとの統合が含まれています。これらはすべて NVIDIA AI Workbench によって調整されます。
デモ サービスはすべてcodeフォルダーにあります。コード フォルダーのルート レベルには、技術的な詳細を目的とした対話型のノートブックがいくつかあります。 Chain Server は、LangChain で NIM を利用するサンプル アプリケーションです。 (ここでのチェーン サーバーでは、RAG を使用するか使用しないで実験するオプションが提供されることに注意してください)。 Chat Frontend フォルダーには、チェーン サーバーを実行するための対話型 UI サーバーが含まれています。最後に、取得スコアリングと検証を示すサンプル ノートブックが評価ディレクトリに提供されています。
マインドマップ
root((AI ワークベンチ))
デモサービス
チェーンサーバー<br />LangChain + NIM
フロントエンド<br />インタラクティブ デモ UI
評価<br />結果を検証する
ノートブック<br />高度な使い方
統合
Redis<br>会話履歴
ミルバス<br>ベクター データベース
LLM NIM<br>最適化された LLM
Chain Server は、構成ファイルまたは環境変数を使用して構成できます。
デフォルトでは、アプリケーションは次のすべての場所で構成ファイルを検索します。複数の構成ファイルが見つかった場合は、リストの下位のファイルの値が優先されます。
追加の構成ファイルのパスは、 APP_CONFIGという名前の環境変数を通じて指定できます。このファイルの値は、すべてのデフォルトのファイルの場所よりも優先されます。
export APP_CONFIG=/etc/my_config.yaml環境変数を使用して構成を設定することもできます。変数名の形式は次のとおりです。 APP_FIELD__SUB_FIELD環境変数として指定された値は、ファイルのすべての値より優先されます。
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
チャット フロントエンドにもいくつかの構成オプションがあります。チェーンサーバーと同様に設定できます。
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
このプロジェクトに対するすべてのフィードバックと貢献を歓迎します。個人使用または貢献のためにこのプロジェクトに変更を加える場合は、このプロジェクトでフォークに取り組むことをお勧めします。フォークでの変更が完了したら、マージ リクエストを開く必要があります。
このプロジェクトは、過度に負担にならずにコードの一貫性を維持できるように調整されたリンターで構成されています。次のリンターを使用します。
組み込み VSCode 環境は、リンティングとチェックをリアルタイムで実行するように構成されています。
CI パイプラインによって行われる lint チェックを手動で実行するには、 /project/code/tools/lint.shを実行します。個々のテストは/project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix]のように名前で指定して実行できます。 lint ツールを修正モードで実行すると、Black を実行し、README を更新し、すべての Jupyter Notebook のセル出力をクリアすることで修正できる内容が自動的に修正されます。
フロントエンドは、必要な HTML および Javascript の開発を最小限に抑えるように設計されています。バニラ HTML、JavaScript、および CSS で作成された、ブランド化およびスタイル化されたアプリケーション シェルが提供されます。簡単にカスタマイズできるように設計されていますが、必須にする必要はありません。フロントエンドの対話型コンポーネントはすべて Gradio で作成され、iframe を使用してアプリ シェルにマウントされます。
アプリ シェルの上部には、利用可能なビューがリストされたメニューがあります。各ビューには、1 つまたはいくつかのページで構成される独自のレイアウトがある場合があります。
ページには、デモ用のインタラクティブなコンポーネントが含まれています。ページのコードはcode/frontend/pagesディレクトリにあります。新しいページを作成するには:
__init__.pyファイルを新しいディレクトリに作成します。 Gradio Blocks レイアウトは、 pageという変数で定義する必要があります。chatページを参照してください。code/frontend/pages/__init__.pyファイルを開き、新しいページをインポートし、新しいページを__all__リストに追加します。注:新しいページを作成しても、フロントエンドには追加されません。フロントエンドに表示するには、ビューに追加する必要があります。
ビューは 1 つまたはいくつかのページで構成されており、それぞれが独立して機能する必要があります。ビューはすべてcode/frontend/server.pyモジュールで定義されます。宣言されたすべてのビューは、フロントエンドのメニュー バーに自動的に追加され、UI で使用できるようになります。
新しいビューを定義するには、 viewsという名前のリストを変更します。これはViewオブジェクトのリストです。オブジェクトの順序によって、フロントエンド メニューでの順序が定義されます。最初に定義されたビューがデフォルトになります。
ビュー オブジェクトはビューの名前とレイアウトを記述します。それらは次のように宣言できます。
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
)すべてのページ宣言View.leftまたはView.right ) はオプションです。これらが宣言されていない場合、Web レイアウト内の関連する iframe は非表示になります。他の iframe はギャップを埋めるために展開されます。次の図は、さまざまなレイアウトを示しています。
ブロックベータ
列1
メニュー[「メニューバー」]
ブロック
列2
左右
終わり
ブロックベータ
列1
メニュー[「メニューバー」]
ブロック
列1
左:1
終わり
フロントエンドには、さまざまなユースケースに合わせてカスタマイズできるいくつかのブランド資産が含まれています。
フロントエンドには、ページの左上にロゴが含まれています。ロゴを変更するには、目的のロゴの SVG が必要です。 code/frontend/_assets/index.htmlファイルを変更することで、新しい SVG を使用するようにアプリ シェルを簡単に変更できます。 ID がlogoのdiv 1 つあります。このボックスには 1 つの SVG が含まれています。これを目的の SVG 定義に更新します。
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > App Shell のスタイルはcode/frontend/_static/css/style.cssで定義されます。このファイルの色は安全に変更できます。
さまざまなページのスタイルはcode/frontend/pages/*/*.cssで定義されます。これらのファイルは、カスタム カラー スキームの変更が必要になる場合もあります。
Gradio テーマは、ファイルcode/frontend/_assets/theme.jsonで定義されます。このファイル内の色は、目的のブランドに安全に変更できます。このファイル内の他のスタイルも変更される可能性がありますが、フロントエンドに重大な変更が生じる可能性があります。 Gradio のドキュメントには、Gradio テーマに関する詳細情報が含まれています。
注:これは、ほとんどの開発者が決して必要としない高度なトピックです。
場合によっては、ビュー内に相互に通信する複数のページが必要になることがあります。この目的のために、JavaScript のpostMessageメッセージング フレームワークが使用されます。アプリケーション シェルに投稿された信頼できるメッセージはすべて、ページが必要に応じてメッセージを処理できる各 iframe に転送されます。 controlページはこの機能を使用してchatページの構成を変更します。
以下は、アプリ シェル ( window.top ) にメッセージを投稿します。メッセージには、キーuse_kbと値 true を持つ辞書が含まれます。 Gradio を使用すると、この Javascript は任意の Gradio イベントによって実行できます。
window . top . postMessage ( { "use_kb" : true } , '*' ) ;このメッセージは、アプリ シェルによってすべてのページに自動的に送信されます。次のサンプル コードは、別のページでメッセージを消費します。このコードは、 messageイベントを受信すると非同期で実行されます。メッセージが信頼できる場合、 use_kbのelem_idを持つ Gradio コンポーネントは、メッセージで指定された値に更新されます。このようにして、Gradio コンポーネントの値をページ間で複製できます。
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; README は自動的に表示されます。直接編集した内容は上書きされます。 README を変更するには、各セクションのファイルを個別に編集する必要があります。これらのファイルはすべて結合され、README が自動的に生成されます。すべての関連ファイルはdocsフォルダーにあります。
ドキュメントは Github Flavored Markdown で書かれ、Pandoc によって最終的な Markdown ファイルにレンダリングされます。このプロセスの詳細は Makefile で定義されます。生成されるファイルの順序はdocs/_TOC.mdで定義されます。ドキュメントは、Workbench ファイル ブラウザ ウィンドウでプレビューできます。
ヘッダー ファイルは、ドキュメントをコンパイルするために使用される最初のファイルです。このファイルはdocs/_HEADER.mdにあります。このファイルの内容は、何も操作せずにそのまま README に書き込まれます。
概要ファイルには、このプロジェクトを説明する簡単な説明と図が含まれています。このファイルの内容は、README のヘッダーの直後、目次の直前に追加されます。このファイルは、README に書き込む前に画像を埋め込むために Pandoc によって処理されます。
ドキュメントの最も重要なファイルは、 docs/_TOC.mdにある目次ファイルです。このファイルは、最終的な README マニュアルを生成するために連結する必要があるファイルのリストを定義します。ファイルを含めるには、このリストにファイルが含まれている必要があります。
画像を含むすべての静的コンテンツを_staticフォルダーに保存します。これは組織化に役立ちます。
ドキュメント自体が更新され、記述されると便利な場合があります。動的ドキュメントを作成するには、Markdown 形式のドキュメントを stdout に書き込む実行可能ファイルを作成するだけです。ビルド時に、目次ファイル内のエントリが実行可能であれば、それが実行され、その stdout が代わりに使用されます。
ドキュメント関連のコミットがプッシュされると、GitHub アクションによってドキュメントがレンダリングされます。 README への変更はすべて自動的にコミットされます。
開発環境の設定のほとんどは、環境変数を使用して行われます。環境変数に永続的な変更を加えるには、 variables.env変更するか、ワークベンチ UI を使用します。
このプロジェクトでは/usr/bin/python3にある 1 つの Python 環境を使用し、依存関係はpipで管理されます。すべての開発はコンテナ内で行われるため、Python 環境への変更は一時的なものになります。 Python パッケージを永続的にインストールするには、それをrequirements.txtファイルに追加するか、ワークベンチ UI を使用します。
開発環境はUbuntu 22.04をベースとしています。プライマリ ユーザーにはパスワードなしの sudo アクセス権がありますが、システムへのすべての変更は一時的なものになります。インストールされているパッケージに永続的な変更を加えるには、それらを [ apt.txt ] ファイルに追加します。ファイルの操作、環境変数の追加など、オペレーティング システムにその他の変更を加える。 postBuild.bashファイルとpreBuild.bashファイルを使用します。
通常、依存関係を毎月更新して、誤用された依存関係によって CVE が漏洩しないようにすることをお勧めします。このプロジェクトにパッチを適用するには、次のプロセスを使用できます。アップデートで何も壊れていないことを確認するために、パッチの後に回帰テストを実行することをお勧めします。
/project/code/tools/bump.shスクリプトを実行することで自動的に更新できます。/project/code/tools/audit.shを実行します。このスクリプトは、警告状態のすべての Python パッケージとエラー状態のすべてのパッケージのレポートを出力します。エラー状態にあるものにはアクティブな CVE と既知の脆弱性があるため、解決する必要があります。

