Facebook Messenger Bot
1.0.0
私と同じように話せるようにトレーニングした FB メッセンジャー チャットボット。関連するブログ投稿。
このプロジェクトでは、さまざまなソーシャル メディア サイトの過去の会話ログに基づいて Sequence To Sequence モデルをトレーニングしたいと考えました。このアプローチの背後にある動機、ML モデルの詳細、各 Python スクリプトの目的については、ブログ投稿で詳しく読むことができますが、私はこの README を使用して、独自のチャットボットをトレーニングしてあなたのように話す方法を説明したいと思います。 。
これらのスクリプトを実行するには、次のライブラリが必要です。
対話的に、またはターミナルに次のように入力して、GitHub からこのリポジトリ全体をダウンロードして解凍します。
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitマシン上のリポジトリの最上位ディレクトリに移動します。
cd Facebook-Messenger-Bot私たちの最初の仕事は、さまざまなソーシャル メディア サイトからすべての会話データをダウンロードすることです。私の場合は、Facebook、Google Hangouts、LinkedInを使用しました。データを取得している他のサイトがある場合は、問題ありません。 createDataset.py で新しいメソッドを作成するだけです。
Facebook データ: ここからデータをダウンロードします。ダウンロードが完了すると、 messages.htmというかなり大きなファイルが作成されます。かなり大きなファイルになります (私の場合は 190 MB 以上)。この大きなファイルを解析し、すべての会話を抽出する必要があります。これを行うには、Dillon Dixon がオープンソース化してくださったこのツールを使用します。次のコマンドを実行してツールをインストールします。
pip install fbchat-archive-parserそして実行します:
fbcap ./messages.htm > fbMessages.txtこれにより、Facebook での会話がすべて、かなり統一されたテキスト ファイルで提供されます。ありがとうディロン!次に、そのファイルを Facebook-Messenger-Bot フォルダーに保存します。
LinkedIn データ: ここからデータをダウンロードします。ダウンロードが完了すると、 inbox.csvファイルが表示されるはずです。ここでは他の手順を行う必要はありません。フォルダーにコピーするだけです。
Google ハングアウト データ: ここからデータ フォームをダウンロードします。ダウンロードすると、解析する必要がある JSON ファイルが得られます。これを行うには、この驚異的なブログ投稿で見つかったこのパーサーを使用します。データをテキスト ファイルに保存し、そのフォルダーを自分のフォルダーにコピーします。
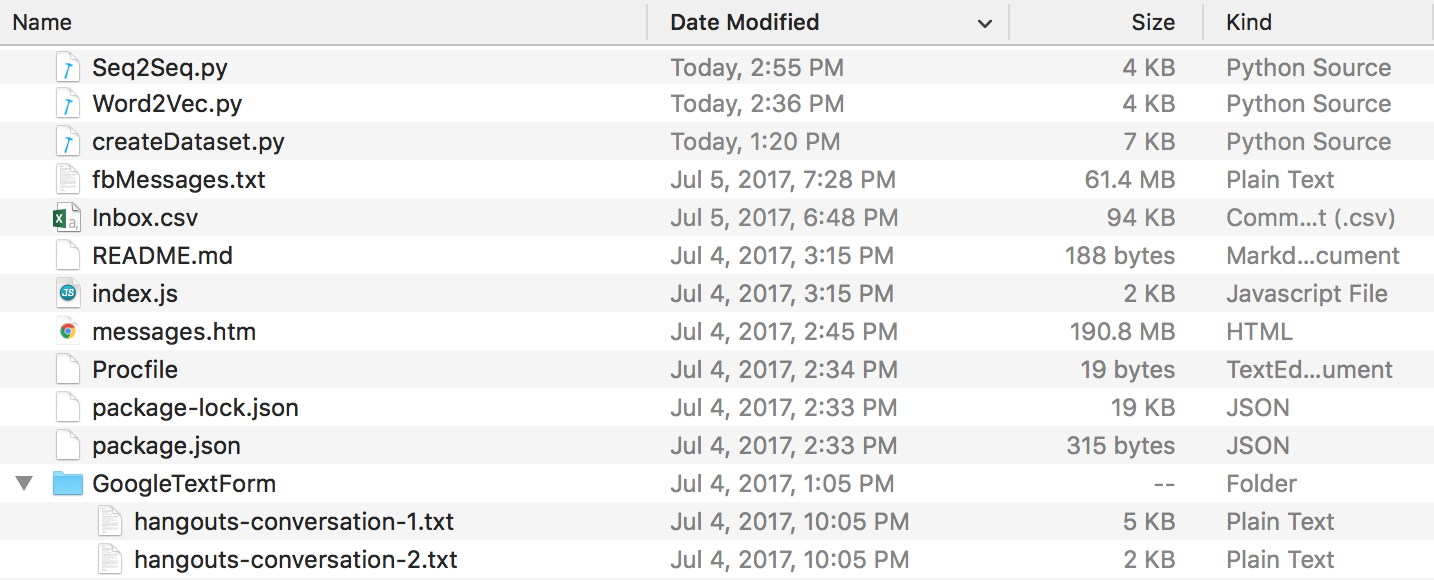
以上の作業をすべて終えると、次のようなディレクトリ構造になるはずです。フォルダー名とファイル名が異なる場合は、必ず名前を変更してください。
Discord データ: Tyrrrz が作成したこの素晴らしい DiscordChatExporter を使用して、Discord チャットログを抽出できます。ドキュメントに従って、必要な単一のチャット ログを.txt形式で抽出します (これは重要です)。その後、それらをすべてリポジトリ ディレクトリ内のDiscordChatLogsという名前のフォルダーに配置できます。
WhatsApp データ: 携帯電話を持っていることを確認し、まだ米国の日付形式に設定していない場合は、それを入力してください (これは、後でログ ファイルを .csv に解析するときに重要になります)。この目的で whatsApp Web を使用することはできません。送信したいチャットを開き、メニューボタンをタップし、その他をタップして、「電子メールチャット」をクリックします。電子メールを自分自身に送信し、コンピュータにダウンロードします。これにより .txt ファイルが得られます。これを解析するために、.csv に変換します。これを行うには、このリンクに移動し、ログ ファイルにすべてのテキストを入力します。 「エクスポート」をクリックし、csv ファイルをダウンロードし、「whatsapp_chats.csv」という名前で Facebook-Messenger-Bot フォルダーに保存します。
注: 上記のリンクで提供されているパーサーは削除されたようです。正しい形式の.csvファイルがまだある場合は、それを使用できます。それ以外の場合は、whatsapp チャット ログを.txtファイルとしてダウンロードし、それらをすべてリポジトリ ディレクトリ内のWhatsAppChatLogsという名前のフォルダーに置きます。 createDataset.py 、 whatsapp_chats.csvという名前の.csvファイルが見つからない場合に限り、代わりにこれらのファイルを処理します。
.txtチャット ログを使用する場合、予期される形式は次のとおりであることに注意してください。
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(または)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
すべての会話ログがクリーンな形式になったので、データセットの作成に進むことができます。ディレクトリで次を実行しましょう。
python createDataset.py次に、自分の名前 (誰を検索すればよいかをスクリプトが認識できるように) と、どのソーシャル メディア サイトのデータを持っているかを入力するよう求められます。このスクリプトは、 conversationDictionary.npyという名前のファイルを作成します。これは、(FRIENDS_MESSAGE, YOUR RESPONSE) の形式のペアを含む Numpy オブジェクトです。また、 conversationData.txtという名前のファイルも作成されます。これは、辞書データを統一した大きなテキスト ファイルです。
これら 2 つのファイルができたので、Word2Vec モデルを通じてワード ベクトルの作成を開始できます。このステップは他のステップとは少し異なります。後で説明する Tensorflow 関数 (seq2seq.py 内) は、実際には埋め込み部分も処理します。したがって、独自のベクトルをトレーニングするか、seq2seq 関数で共同でトレーニングするかを決定できます。最終的にはこれを実行しました。 Word2Vec を使用して独自の単語ベクトルを作成したい場合は、プロンプトで (次のコマンドを実行した後) y と言います。そうでない場合は、問題ありません。n と応答すると、この関数は wordList.txt のみを作成します。
python Word2Vec.pyword2vec.py 全体を実行すると、4 つの異なるファイルが作成されます。 Word2VecXTrain.npyとWord2VecYTrain.npyは、Word2Vec が使用するトレーニング行列です。別のハイパーパラメータを使用して Word2Vec モデルを再度トレーニングする必要がある場合に備えて、これらをフォルダーに保存します。また、 wordList.txtも保存します。これには、コーパス内のすべての一意の単語が含まれています。最後に保存されたファイルは、 embeddingMatrix.npyです。これは、生成されたすべての単語ベクトルを含む Numpy 行列です。
これで、Seq2Seq モデルを作成してトレーニングできるようになりました。
python Seq2Seq.pyこれにより、3 つ以上の異なるファイルが作成されます。 Seq2SeqXTrain.npyおよびSeq2SeqYTrain.npy は、 Seq2Seq が使用するトレーニング行列です。繰り返しますが、モデル アーキテクチャに変更を加え、トレーニング セットを再計算したくない場合に備えて、これらを保存します。最後のファイルは、保存された Seq2Seq モデルを保持する .ckpt ファイルになります。モデルはトレーニング ループ内のさまざまな期間で保存されます。これらは、チャットボットの作成後に使用およびデプロイされます。
モデルを保存したので、Facebook チャットボットを作成しましょう。そのためには、このチュートリアルに従うことをお勧めします。 「ボットの発言をカスタマイズする」セクションの下には何も読む必要はありません。私たちの Seq2Seq モデルがその部分を処理します。重要 - チュートリアルでは、Node プロジェクトを配置する新しいフォルダーを作成するように指示されます。このフォルダーは私たちのフォルダーとは異なることに注意してください。このフォルダーはデータの前処理とモデルのトレーニングが行われる場所であると考えることができ、他のフォルダーは Express アプリ用に厳密に予約されています (編集: フォルダー内のチュートリアルの手順に従って、Node プロジェクトを作成するだけでよいと思います。必要に応じて、Procfile およびindex.js ファイルをここに含めます)。チュートリアル自体で十分ですが、手順の概要を以下に示します。
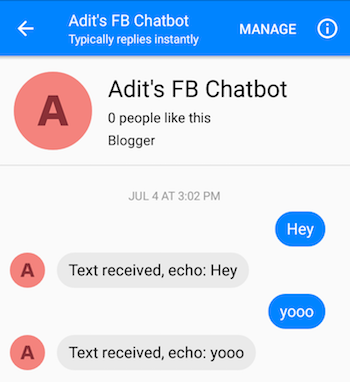
手順を正しく実行すると、チャットボットにメッセージを送信し、応答を受け取ることができるようになります。
ああ、もうすぐ終わりです!次に、保存した Seq2Seq モデルをデプロイできる Flask サーバーを作成する必要があります。そのサーバーのコードはここにあります。一般的な構造について話しましょう。 Flask サーバーには通常、すべてのエンドポイントを定義するメインの .py ファイルが 1 つあります。この場合、これは app.py になります。ここにモデルをロードします。 「models」という名前のフォルダーを作成し、そこに 4 つのファイル (チェックポイント ファイル、データ ファイル、インデックス ファイル、メタ ファイル) を入れる必要があります。これらは、Tensorflow モデルを保存するときに作成されるファイルです。

この app.py ファイルでは、ルートへの入力が保存されたモデルに供給されるルート (私の場合は /prediction) を作成する必要があり、デコーダーの出力は返される文字列です。まだ少しわかりにくい場合は、app.py を詳しく見てください。 app.py とモデル (必要に応じてその他のヘルパー ファイル) が完成したので、サーバーをデプロイできます。もう一度 Heroku を使用します。 Flask サーバーを Heroku にデプロイするためのさまざまなチュートリアルがたくさんありますが、私は特にこれが好きです (Foreman セクションと Logging セクションは必要ありません)。
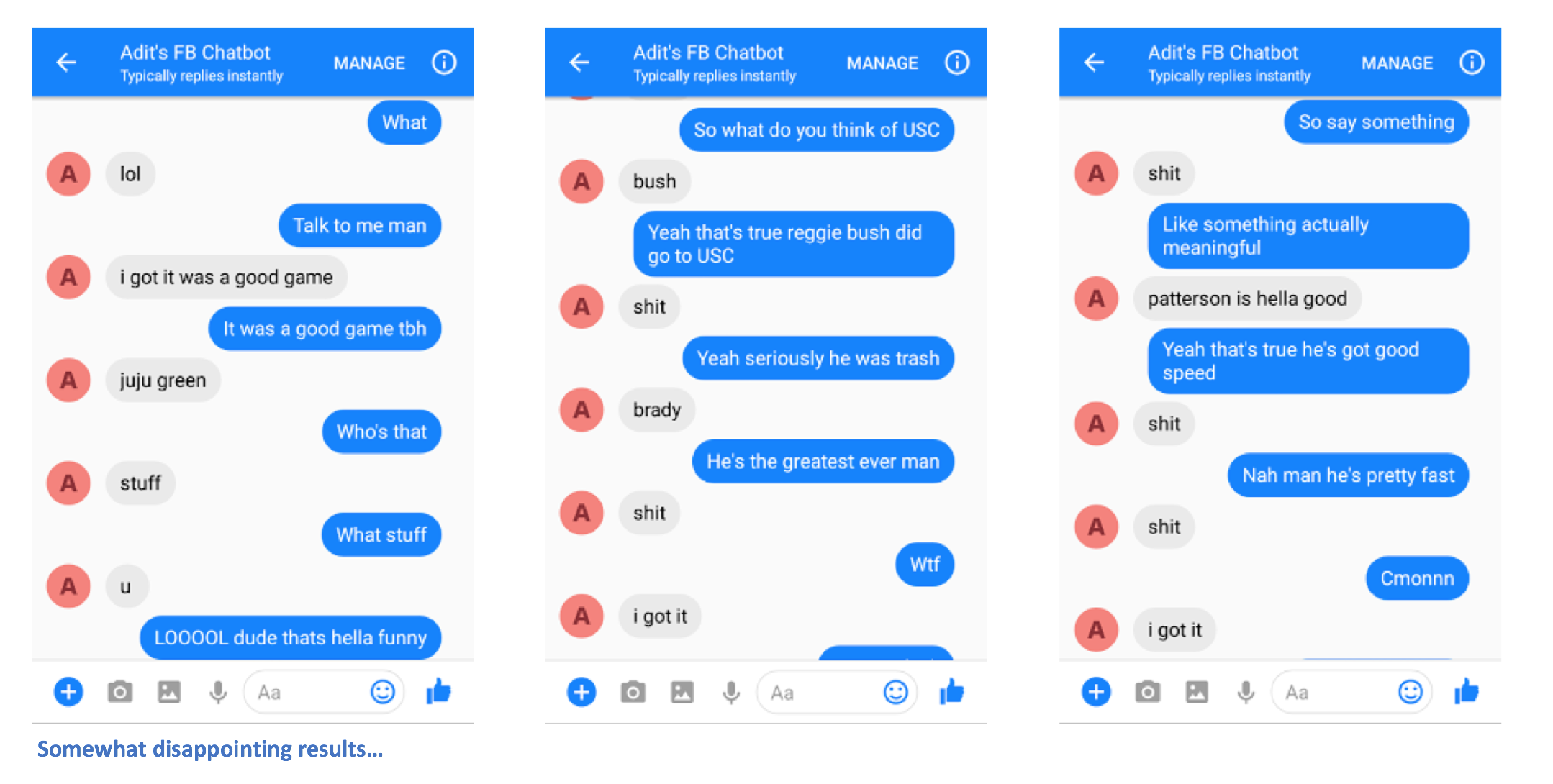
さあ行きましょう。チャットボットにメッセージを送信すると、(うまくいけば) 何らかの形で自分に似た興味深い応答が表示されるはずです。
何か問題がある場合、またはこの README をより良くするための提案がある場合はお知らせください。特定の手順が不明瞭であると思われる場合は、お知らせください。README を編集して明確にするよう最善を尽くします。


