snips nlu
0.20.2
Snips NLU (Natural Language Understanding) は、自然言語で書かれた文から構造化情報を抽出できる Python ライブラリです。
すべてのチャットボットと音声アシスタントの背後には、自然言語理解 (NLU) という共通のテクノロジーが存在します。ユーザーが自然言語を使用して AI と対話するときは常に、ユーザーの言葉を、その意味を機械が読み取り可能な説明に翻訳する必要があります。
NLU エンジンは、まずユーザーの意図 (別名インテント) を検出し、次にクエリのパラメーター (スロットと呼ばれます) を抽出します。開発者はこれを使用して、適切なアクションまたは応答を決定できます。
これを説明するために例を挙げて、次の文を考えてみましょう。
「午後9時のパリの天気はどうなりますか?」
適切にトレーニングされた Snips NLU エンジンは、次のような構造化データを抽出できるようになります。
{
"intent" : {
"intentName" : " searchWeatherForecast " ,
"probability" : 0.95
},
"slots" : [
{
"value" : " paris " ,
"entity" : " locality " ,
"slotName" : " forecast_locality "
},
{
"value" : {
"kind" : " InstantTime " ,
"value" : " 2018-02-08 20:00:00 +00:00 "
},
"entity" : " snips/datetime " ,
"slotName" : " forecast_start_datetime "
}
]
}この場合、識別された意図はsearchWeatherForecastであり、地域と日時の 2 つのスロットが抽出されました。ご覧のとおり、Snips NLU はエンティティの抽出に加えて追加の手順を実行し、エンティティを解決します。抽出された日時値は、実際に便利な ISO 形式に変換されています。
Snips NLU を構築した理由と内部でどのように機能するかについて詳しくは、ブログ投稿をご覧ください。また、Snips Voice プラットフォームの機械学習アーキテクチャを紹介する論文を arxiv に公開しました。
pip install snips - nlu現在、MacOS (10.11 以降)、Linux x86_64、および Windows 用のsnips-nluとその依存関係用のビルド済みバイナリ (ホイール) があります。
他のアーキテクチャ/OS の場合は、ソース ディストリビューションから snips-nlu をインストールできます。これを行うには、 pip install snips-nluコマンドを実行する前に、Rust と setuptools_rust をインストールする必要があります。
Snips NLU は、ライブラリを使用する前にダウンロードする必要がある外部言語リソースに依存しています。次のコマンドを実行すると、特定の言語のリソースを取得できます。
python -m snips_nlu download enまたは単に:
snips-nlu download enサポートされている言語のリストは、このアドレスから入手できます。
このライブラリの機能をテストする最も簡単な方法は、コマンド ライン インターフェイスを使用することです。
まず、サンプル データセットの 1 つを使用して NLU をトレーニングすることから始めます。
snips-nlu train path/to/dataset.json path/to/output_trained_engineここで、 path/to/dataset.jsonトレーニング中に使用されるデータセットへのパスであり、 path/to/output_trained_engineはトレーニング完了後にトレーニングされたエンジンを保持する場所です。
その後、以下を実行して対話的に文の解析を開始できます。
snips-nlu parse path/to/trained_engineここで、 path/to/trained_engineは、前のステップでトレーニングされたエンジンを保存した場所に対応します。
以下は、snips-nlu をインストールし、英語リソースを取得し、サンプル データセットの 1 つをダウンロードした後に、マシン上で実行できるサンプル コードです。
>> > from __future__ import unicode_literals , print_function
>> > import io
>> > import json
>> > from snips_nlu import SnipsNLUEngine
>> > from snips_nlu . default_configs import CONFIG_EN
>> > with io . open ( "sample_datasets/lights_dataset.json" ) as f :
... sample_dataset = json . load ( f )
>> > nlu_engine = SnipsNLUEngine ( config = CONFIG_EN )
>> > nlu_engine = nlu_engine . fit ( sample_dataset )
>> > text = "Please turn the light on in the kitchen"
>> > parsing = nlu_engine . parse ( text )
>> > parsing [ "intent" ][ "intentName" ]
'turnLightOn'これが行うことは、サンプル気象データセットで NLU エンジンをトレーニングし、気象クエリを解析することです。
Snips NLU エンジンのトレーニングに使用できるいくつかのデータセットのリストを次に示します。
2018 年 1 月に、2017 年の夏に公開された学術ベンチマークを再現しました。この記事では、著者は API.ai (現在の Dialogflow、Google)、Luis.ai (Microsoft)、IBM Watson、および Rasa NLU のパフォーマンスを評価しました。公平性を保つために、Rasa NLU の更新バージョンを使用し、それを Snips NLU の最新バージョン (どちらも濃い青色) と比較しました。
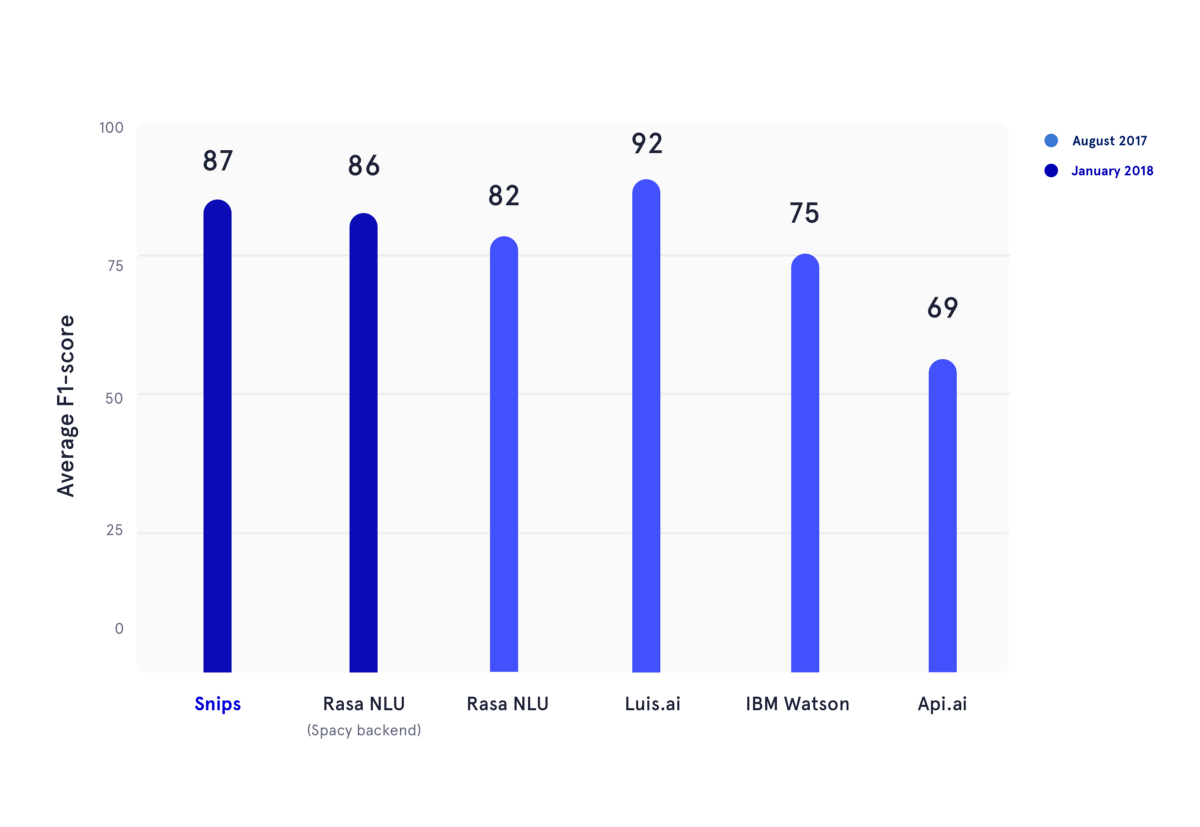
上の図では、意図分類とスロット充填の両方の F1 スコアが複数の NLU プロバイダーに対して計算され、前述の学術ベンチマークで使用された 3 つのデータセット全体で平均化されています。基本的な結果はすべてここで見つけることができます。
Snips NLU の使用方法については、パッケージのドキュメントを参照してください。このライブラリには、このライブラリのセットアップと使用方法に関するステップバイステップのガイドが記載されています。
Snips NLU を使用する場合は、次の論文を引用してください。
@article { coucke2018snips ,
title = { Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces } ,
author = { Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others } ,
journal = { arXiv preprint arXiv:1805.10190 } ,
pages = { 12--16 } ,
year = { 2018 }
}フォーラムに参加して質問し、コミュニティからフィードバックを得てください。
投稿ガイドラインをご覧ください。
このライブラリは、Snips によってオープン ソース ソフトウェアとして提供されています。詳細については、「ライセンス」を参照してください。
snips/city、snips/country、snips/region の組み込みエンティティは、Creative Commons Attribution 4.0 ライセンス インターナショナルに基づいて利用できる Geonames のソフトウェアに依存しています。 Geonames のライセンスと保証については、https://creativecommons.org/licenses/by/4.0/legalcode を参照してください。


