msg_reply
1.0.0
Google スマート リプライを見たり使ったりしたことがありますか?ユーザーのメッセージに対する自動返信候補を提供するサービスです。以下を参照してください。
これは、検索ベースのチャットボットの便利なアプリケーションです。考えてみてください。 「thx 」 「hey 」 「また会いましょう」などのメッセージを何回テキストメッセージで送ったでしょうか?このプロジェクトでは、簡単なメッセージ返信提案システムを構築します。
キュビョンパーク
Yj Choe によるコードレビュー
表示する提案のリストを設定する必要があります。当然のことながら、頻度が最初に考慮されます。しかし、意味が似ているこれらのフレーズはどうでしょうか?たとえば、とても感謝していますが、 thx は独立して扱われる必要がありますか?私たちはそうは思いません。それらをグループ化してスロットを保存したいと思います。どうやって?対訳コーパスを利用します。 thank you so muchとthx はどちらも同じテキストに翻訳される可能性があります。この仮定に基づいて、同じ翻訳を共有する英語の同義語グループを構築します。
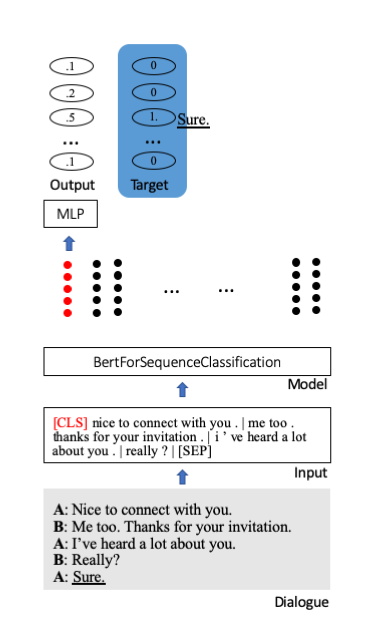
シーケンス分類のために、Huggingface の Bert 事前トレーニング済みモデルを微調整します。その中には、特別な開始トークン [CLS] が文の全情報を格納します。追加のレイヤーが追加され、凝縮された情報が分類単位 (ここでは 100) に投影されます。
OpenSubtitles 2018 スペイン語と英語の対訳コーパスを使用して、同義語グループを構築します。 OpenSubtitles は、翻訳された映画字幕の大規模なコレクションです。 en-es データは 6,100 万行以上の整列された行で構成されています。
理想的には、トレーニングには (非常に) 大規模な対話コーパスが必要ですが、私たちはそれを見つけることができませんでした。代わりに、Cornell Movie Dialogue Corpus を使用します。 83,097 の会話または 304,713 行で構成されています。
Python>=3.6
tqdm>=4.30.0
pytorch>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
ステップ 0. OpenSubtitles 2018 スペイン語-英語対訳データをダウンロードします。
bash download.sh
ステップ 1. コーパスから同義語グループを構築します。
python construct_sg.py
ステップ 2. phr2sg_id および sg_id2phr 辞書を作成します。
python make_phr2sg_id.py
ステップ 3. 単一言語の英語テキストを ID に変換します。
python encode.py
ステップ 4. トレーニング データを作成し、pickle として保存します。
python prepro.py
ステップ5.トレーニングします。
python train.py
事前トレーニングされたモデルをダウンロードして抽出し、次のコマンドを実行します。
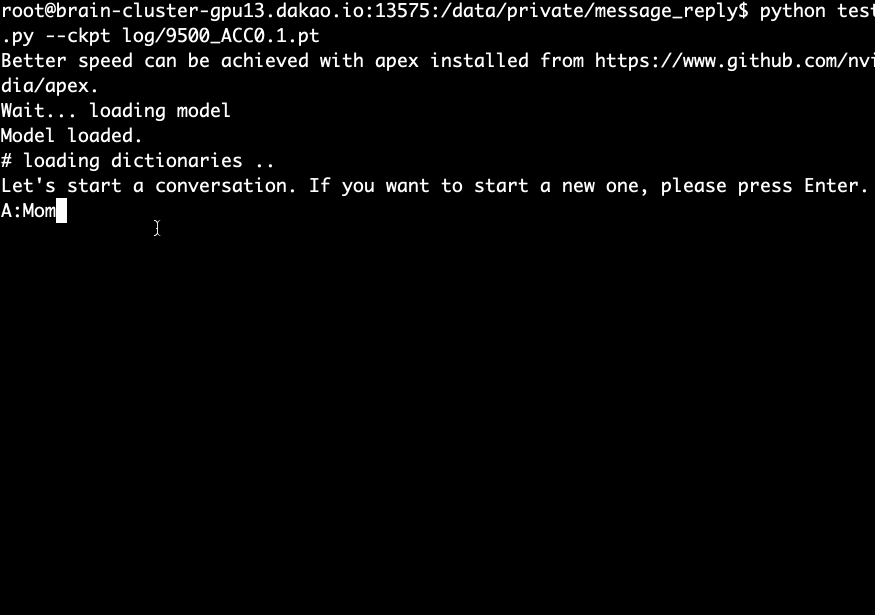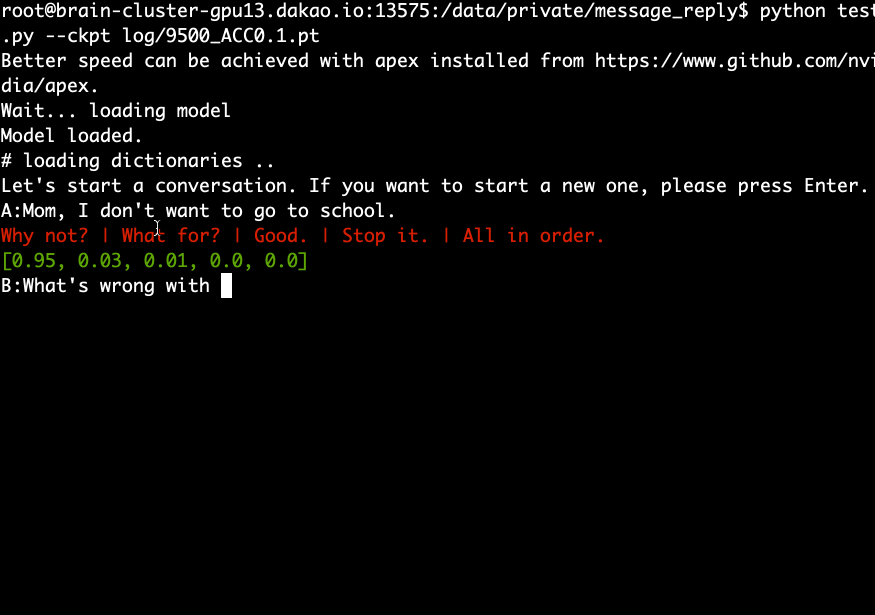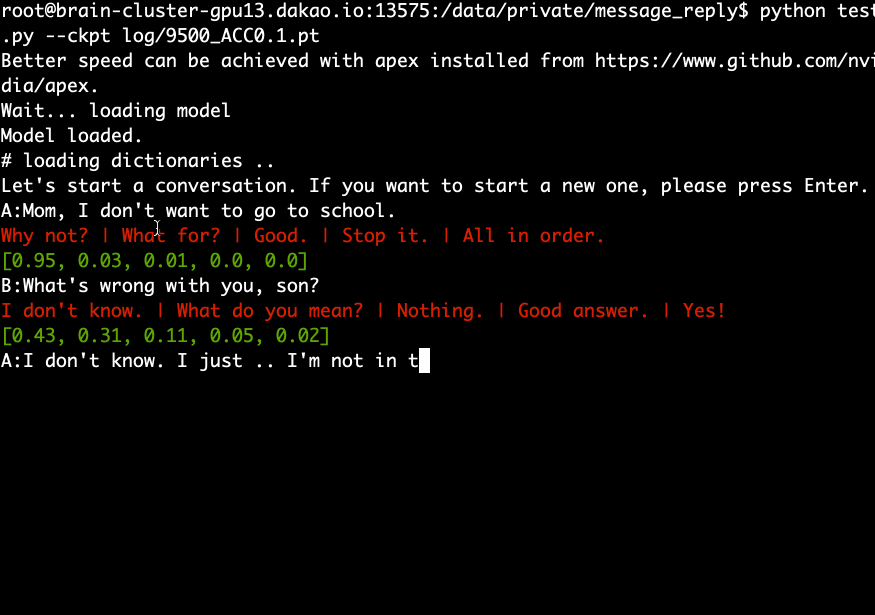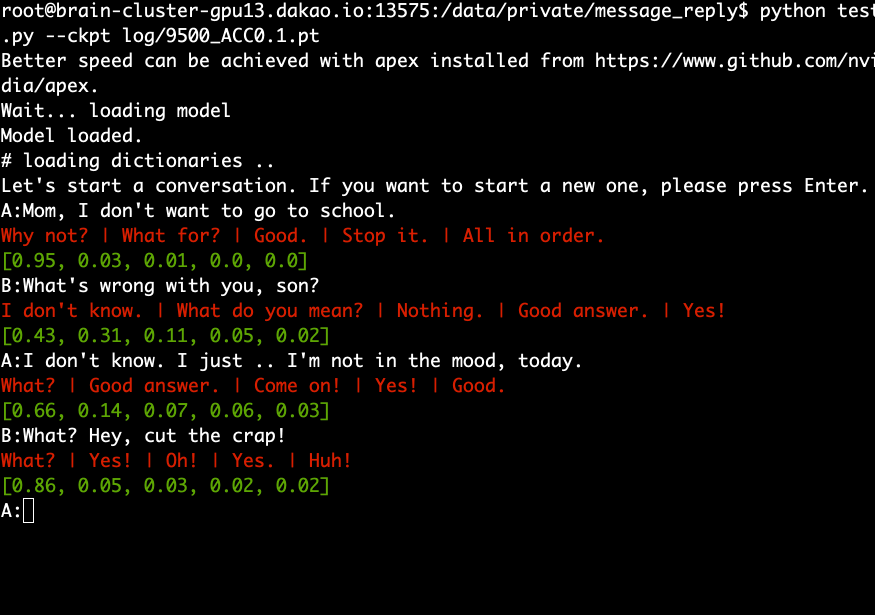
python test.py --ckpt log/9500_ACC0.1.pt
トレーニングの損失はゆっくりと、しかし確実に減少します。
評価データの精度@5は 10 ~ 20% です。
実際のアプリケーションには、はるかに大規模なコーパスが必要です。
映画の脚本がメッセージダイアログにどの程度似ているかはわかりません。
同義語グループを構築するためのより良い戦略が必要です。
検索ベースのチャットボットは、生成ベースのチャットボットよりも安全で簡単なため、現実的なアプリケーションです。


