seq2seq chatbot
v0.2
TensorFlow を使用した sequence2sequence チャットボットの実装。
以下の開始手順を参照するか、チャット ログを確認してください。
(現時点では、バッチ ファイルは Windows でのみ利用可能です。Mac および Linux ユーザーの場合は、以下の Python コンソールの手順を参照してください。)
コンソールチャットの場合:
chat_console_best_weights_training.batまたはchat_console_best_weights_validation.batを実行します。Web チャットの場合:
モデル ディレクトリから、 chat_web_best_weights_training.batまたはchat_web_best_weights_validation.batを実行します。
ブラウザを開いて、サーバー コンソールで示された URL にアクセスし、その後に/chat_ui.htmlが続きます。通常、これは http://localhost:8080/chat_ui.html です。
コンソールの作業ディレクトリをseq2seq-chatbotディレクトリに設定します。このディレクトリには、モデルとデータセットのディレクトリが直接含まれている必要があります。
モデル チェックポイント パスを指定して chat.py を実行します。
run chat.py models d ataset_name m odel_name c heckpoint.ckptたとえば、トレーニングされたコーネル ムービー ダイアログ モデルtrain_model_v2とチャットするには、次のようにします。
train_model_v2 を seq2seq-chatbot/models/cornell_movie_dialog フォルダーにダウンロードして解凍します。
コンソールの作業ディレクトリをseq2seq-chatbotディレクトリに設定します
走る:
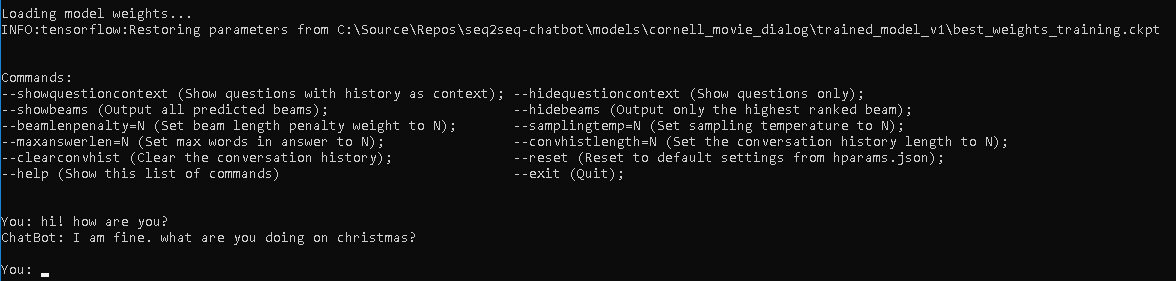
run chat.py models c ornell_movie_dialog t rained_model_v2 b est_weights_training.ckpt結果は次のようになります。

Python コンソールからモデルをトレーニングするには:
hparams.json ファイルを目的のトレーニング ハイパーパラメータに設定します。
コンソールの作業ディレクトリをseq2seq-chatbotディレクトリに設定します。このディレクトリには、モデルとデータセットのディレクトリが直接含まれている必要があります。
新しいモデルをトレーニングするには、データセット パスを指定して train.py を実行します。
run train.py --datasetdir=datasets d ataset_nameまたは、既存のモデルのトレーニングを再開するには、モデル チェックポイント パスを指定して train.py を実行します。
run train.py --checkpointfile=models d ataset_name m odel_name c heckpoint.ckptたとえば、デフォルトのハイパーパラメータを使用してコーネル ムービー ダイアログ データセットで新しいモデルをトレーニングするには、次のようにします。
コンソールの作業ディレクトリをseq2seq-chatbotディレクトリに設定します
走る:
run train.py --datasetdir=datasets c ornell_movie_dialog結果は次のようになります。

ドキュメントは近日公開予定です...
TensorBoard は、TensorFlow モデルのトレーニング中に内部で何が起こっているかを視覚化するための優れたツールです。
ターミナルから TensorBoard を起動するには:
tensorboard --logdir=model_dirここで、model_dir は、モデル チェックポイント ファイルが存在するディレクトリへのパスです。たとえば、トレーニングされたコーネル ムービー ダイアログ モデルtrain_model_v2を表示するには、次のようにします。
tensorboard --logdir=models c ornell_movie_dialog t rained_model_v2ドキュメントは近日公開予定です...
ドキュメントは近日公開予定です...
TensorBoard は、PCA や T-SNE などの次元削減手法を実行することで単語の埋め込みを 3D 空間に投影でき、任意の単語の埋め込み空間で最も近い単語を表示することで、モデルが語彙内の単語をどのようにグループ化したかを調査できます。 。 TensorFlow と TensorBoard プロジェクターの単語埋め込みの詳細については、ここを参照してください。
モデル ディレクトリに対して TensorBoard を起動し、[プロジェクター] タブを選択すると、次のようになります。 
説明書は近日公開予定です...
次の Python パッケージが seq2seq-chatbot で使用されます: (Anaconda に付属するパッケージを除く)
TensorFlow *注意 - TF 2.x はまだサポートされていません。最新の TF 1.x バージョンを使用してください。
pip install --upgrade tensorflow==1. *GPU サポートについて: (CUDA や cuDNN を含む完全な GPU インストール手順については、こちらを参照してください)
pip install --upgrade tensorflow-gpu==1. *jsonpickle
pip install --upgrade jsonpickleclick 6.7、flask 0.12.4、および flask-restful (Web インターフェイスの実行に必要)
pip install click==6.7
pip install flask==0.12.4
pip install --upgrade flask-restfulロードマップページを参照
この実装は以下からインスピレーションを受けました。
ニューラルネットワークによるシーケンスツーシーケンス学習
神経会話モデル
整列と翻訳を共同学習することによるニューラル機械翻訳 (バダナウ注意メカニズム)
注意ベースのニューラル機械翻訳への効果的なアプローチ (Luong Notice メカニズム)