RLAIF V
1.0.0

スーパー GPT-4V の信頼性を実現するオープンソース AI フィードバックによる MLLM の調整
中国語 |英語
[2024.11.26] LoRAトレーニングをサポートするようになりました!
[2024.05.28] arXiv で論文が閲覧できるようになりました!
[2024.05.20] 当社の RLAIF-V-Dataset は、最初のエンドサイド GPT-4V レベル MLLM を表す MiniCPM-Llama3-V 2.5 のトレーニングに使用されます。
[2024.05.20] RLAIF-Vのコード、重み(7B、12B)、データをオープンソース化しました!
スーパー GPT-4V の信頼性を実現するために、MLLM を完全なオープンソース パラダイムに調整する新しいフレームワークである RLAIF-V を紹介します。 RLAIF-V は、高品質のフィードバック データとオンライン フィードバック学習アルゴリズムを含む 2 つの重要な観点からオープンソースのフィードバックを最大限に活用します。 RLAIF-V の注目すべき機能は次のとおりです。
オープンソースのフィードバックによるスーパー GPT-4V の信頼性。オープンソース AI フィードバックから学習することで、RLAIF-V 12B は生成タスクと識別タスクの両方でスーパー GPT-4V の信頼性を実現します。
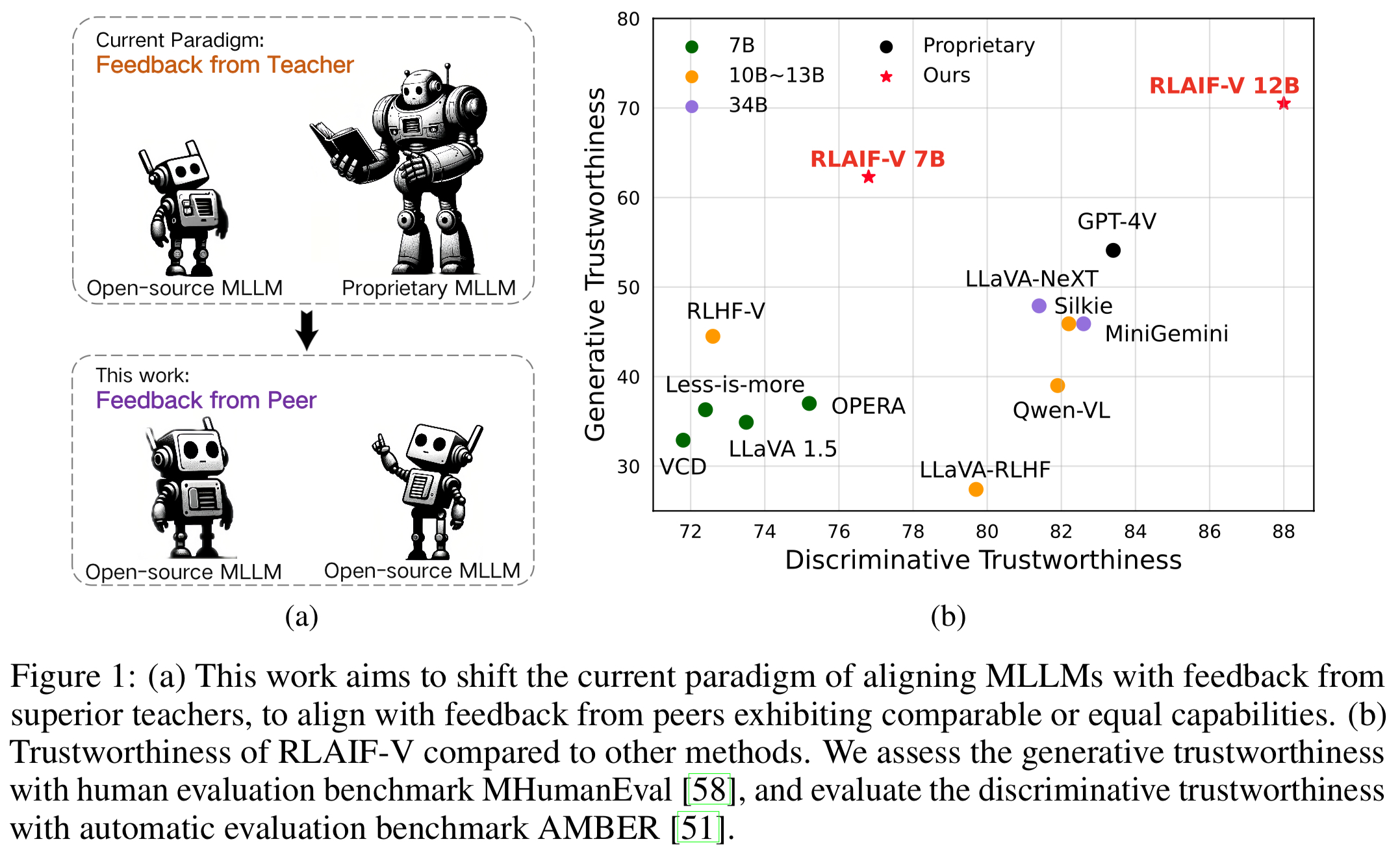
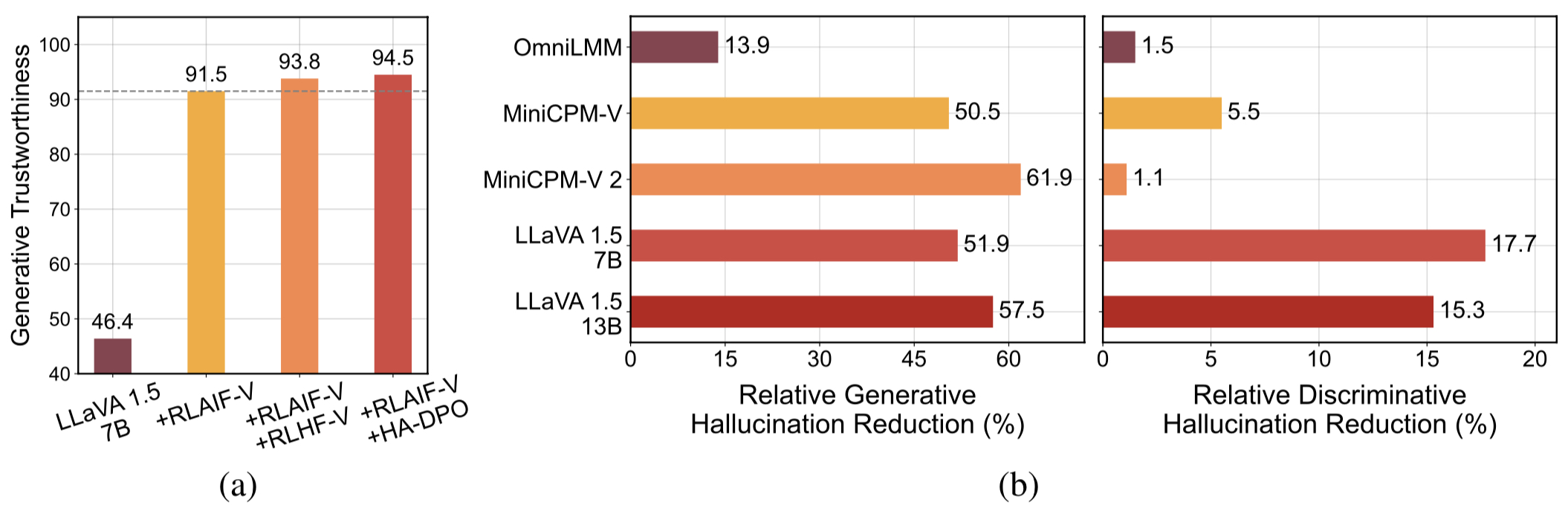
高品質の一般化可能なフィードバック データ。 RLAIF-V によって使用されるフィードバック データは、さまざまな MLLM の幻覚を効果的に軽減します。
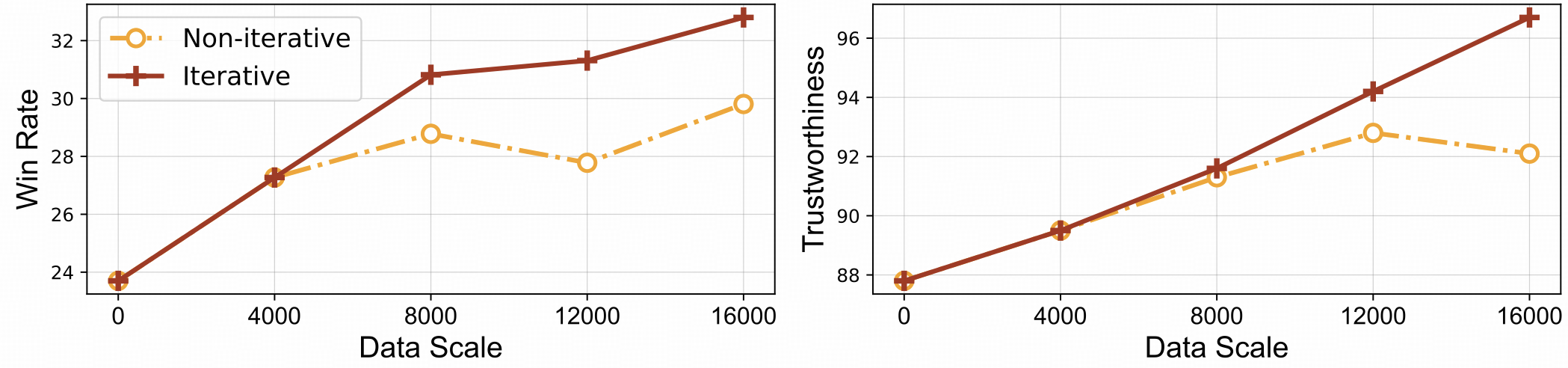
⚡️反復調整による効率的なフィードバック学習。 RLAIF-V は、非反復アプローチと比較して、優れた学習効率と高いパフォーマンスの両方を示します。
データセット
インストール
モデルの重み
推論
データ生成
電車
評価
オブジェクト ハルベンチ
MMHalベンチ
リフォMB
引用
私たちは、さまざまな範囲のタスクとドメインをカバーする AI 生成の嗜好データセットである RLAIF-V データセットを紹介します。このオープンソースのマルチモーダル嗜好データセットには、83,132 個の高品質の比較ペアが含まれています。データセットには、LLaVA 1.5 7B、OmniLMM 12B、MiniCPM-V などのさまざまなモデルのトレーニング反復ごとに生成されたプリファレンス ペアが含まれています。
このリポジトリのクローンを作成し、RLAIF-V フォルダに移動します。
git clone https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
パッケージをインストールする
conda create -n rlaifv python=3.10 -y conda は rlaifv をアクティブ化します pip install -e 。
必要なspaCyモデルをインストールする
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip インストール en_core_web_trf-3.7.3.tar.gz
| モデル | 説明 | ダウンロード |
|---|---|---|
| RLAIF-V 7B | LLaVA 1.5 で最も信頼できるバリアント | ? |
| RLAIF-V 12B | OmniLMM-12BをベースにスーパーGPT-4Vの信頼性を実現。 | ? |
RLAIF-V の使用方法を示す簡単な例を提供します。
from チャット import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "の人々を詳しく説明してください画像。"inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(入力)print(回答)次のスクリプトを実行して、この例を実行することもできます。
Pythonチャット.py

質問:
写真の車はなぜ止まったのですか?
期待される出力:
写真では、車道に羊がいたため、車が路上で停止しました。車はおそらく羊が安全に邪魔にならないところに移動できるようにするため、または羊との潜在的な事故を避けるために停止したと考えられます。この状況は、特に動物が道路近くを徘徊する可能性がある場所では、運転中に用心深く注意を払うことの重要性を浮き彫りにしています。
環境設定
フィードバック生成用に、OmniLMM 12B モデルと MiniCPM-Llama3-V 2.5 モデルを提供します。フィードバックを提供するために MiniCPM-Llama3-V 2.5 を使用したい場合は、MiniCPM-V GitHub リポジトリの指示に従って推論環境を構成してください。
微調整された Llama3 8B モデル: 分割モデルと質問変換モデルをダウンロードし、それぞれ./models/llama3_splitフォルダーと./models/llama3_changeqフォルダーに保存してください。
OmniLMM 12B モデルのフィードバック
次のスクリプトは、LLaVA-v1.5-7b モデルを使用して回答候補を生成し、OmniLMM 12B モデルを使用してフィードバックを提供する方法を示しています。
mkdir ./結果 bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 モデルのフィードバック
次のスクリプトは、LLaVA-v1.5-7b モデルを使用して回答候補を生成し、MiniCPM-Llama3-V 2.5 モデルを使用してフィードバックを提供する方法を示しています。まず、 ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh run_data_pipeline_llava15_minicpmv.sh のminicpmv_pythonを、作成した MiniCPM-V 環境の Python パスに置き換えます。
mkdir ./結果 bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
データの準備(オプション)
ハグフェイス データセットにアクセスできる場合は、この手順をスキップできます。RLAIF-V データセットが自動的にダウンロードされます。
データセットを既にダウンロードしている場合は、38 行目で「openbmb/RLAIF-V-Dataset」をデータセット パスに置き換えることができます。
トレーニング
ここでは、モデルを1 回の反復でトレーニングするためのトレーニング スクリプトを提供します。 max_stepパラメーターは、データの量に応じて調整する必要があります。
完全な微調整
次のコマンドを実行して、完全な微調整を開始します。
bash ./script/train/llava15_train.sh
LoRA
次のコマンドを実行して lora トレーニングを開始します。
pip インストール peft bash ./script/train/llava15_train_lora.sh
反復的な位置合わせ
論文の反復トレーニング プロセスを再現するには、次の手順を 4 回実行する必要があります。
S1.データ生成。
データ生成の手順に従って、基本モデルのプリファレンス ペアを生成します。生成された jsonl ファイルを Huggingface parquet に変換します。
S2.トレーニング構成を変更します。
データセット コードで、ここの'openbmb/RLAIF-V-Dataset'をデータ パスに置き換えます。
トレーニング スクリプトで、 --data_dir新しいディレクトリに置き換え、 --model_name_or_pathベース モデル パスに置き換え、 --max_step 4 エポックのステップ数に設定し、 --save_steps 1/4 エポックのステップ数に設定します。 。
S3. DPO トレーニングを実施します。
トレーニング スクリプトを実行して、基本モデルをトレーニングします。
S4.次の反復の基本モデルを選択します。
Object HalBench および MMHal Bench で各チェックポイントを評価し、最もパフォーマンスの高いチェックポイントを次の反復のベース モデルとして選択します。
COCO2014アノテーションの準備
Object HalBench の評価は、COCO2014 データセットのキャプションとセグメンテーション アノテーションに依存します。まず、COCO データセットの公式 Web サイトから COCO2014 データセットをダウンロードしてください。
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip annotations_trainval2014.zip を解凍します
推論、評価、要約
{YOUR_OPENAI_API_KEY}を有効な OpenAI API キーに置き換えてください。
注: 評価はgpt-3.5-turbo-0613に基づいています。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}MMHalデータの準備
ここからMMHalの評価データをダウンロードし、 eval/dataにファイルを保存してください。
次のスクリプトを実行して、MMHal ベンチ用に生成します。
注: 評価はgpt-4-1106-previewに基づいています。
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}準備
GPT-4 評価を使用するには、まずpip install openai==0.28を実行して openai パッケージをインストールしてください。次に、 eval/gpt4.pyのopenai.baseとopenai.api_key独自の設定に変更します。
開発セットの評価データはeval/data/RefoMB_dev.jsonlにあります。各行のimage_urlキーから各画像をダウンロードする必要があります。
総合点の評価
模範解答を入力データ ファイルeval/data/RefoMB_dev.jsonlのanswerキーに保存します。例:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}次のスクリプトを実行して、モデルの結果を評価します。
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
幻覚スコアの評価
総合スコアの評価後、 A-GPT-4V_B-${model_name}.jsonという名前の評価結果ファイルが作成されます。この評価結果ファイルを使用して幻覚スコアを次のように計算します。
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_result注:安定性を高めるために、 3 回以上評価し、平均スコアを最終モデル スコアとして使用することをお勧めします。
使用法とライセンスに関する通知: データ、コード、およびチェックポイントは、研究用途のみを目的としており、ライセンスが付与されています。また、LLaMA、Vicuna、Chat GPT のライセンス契約に従った使用に制限されます。データセットは CC BY NC 4.0 (非営利使用のみ許可) であり、データセットを使用してトレーニングされたモデルは研究目的以外に使用しないでください。
RLHF-V: 私たちが構築したコードベース。
LLaVA:RLAIF-V-7Bのインストラクションモデルおよびラベラーモデル。
MiniCPM-V: RLAIF-V-12Bのインストラクションモデルおよびラベラーモデル。
私たちのモデル/コード/データ/論文が役立つと思われる場合は、論文を引用してスターを付けてください ️!
@article{yu2023rlhf, title={Rlhf-v: きめ細かな人間による矯正フィードバックによる行動調整を介して信頼できる MLMS に向けて}, author={Yu、Tianyu と Yao、Yuan と Zhang、Haoye と He、Taiwen と Han、Yifeng、 Cui、Ganqu と Hu、Jinyi と Liu、Zhiyuan と Zheng、Hai-Tao と Sun、Maosong など}、 Journal={arXiv preprint arXiv:2312.00849}、year={2023}}@article{yu2024rlaifv、title={RLAIF-V: スーパー GPT-4V の信頼性を実現するためのオープンソース AI フィードバックによる MLLM の調整}、著者={Yu, Tianyuそしてチャン、ハオイェとヤオ、ユアンとダン、ユンカイとChen、Da と Lu、Xiaoman と Cui、Ganqu と He、Taiwen と Liu、Zhiyuan と Chua、Tat-Seng と Sun、Maosong}、journal={arXiv preprint arXiv:2405.17220}、year={2024}、
} 

