ChatLM mini Chinese
1.0.0
中国語 | 英語
今日の大規模な言語モデルには大きなパラメータが含まれる傾向があり、消費者向けコンピューターは、モデルを最初からトレーニングすることはおろか、単純な推論を行うにも時間がかかります。このプロジェクトの目標は、データ クリーニング、トークナイザー トレーニング、モデルの事前トレーニング、SFT 命令の微調整、RLHF 最適化などを含む生成言語モデルを最初からトレーニングすることです。
ChatLM-mini- Chinese は、わずか 0.2B のモデル パラメーター (共有重みを含めて約 2 億 1000 万) を持つ小規模な中国語対話モデルです。最小 4 GB のビデオ メモリ ( batch_size=1 、 fp16またはbf16を備えたマシンで事前トレーニングできます。 )、 float16ロードと推論には少なくとも 512MB のビデオ メモリが必要です。
transformers 、 accelerate 、 trl 、 peftなどを含む、 Huggingface NLP フレームワークを使用します。trainer単一カードを備えた単一マシン上、または単一マシン上の複数のカードを備えた事前トレーニングと SFT 微調整をサポートします。トレーニング中の任意の位置での停止と、任意の位置でのトレーニングの継続をサポートします。Text-to-Text事前トレーニングと非mask予測事前トレーニングに統合されています。sentencepieceおよびhuggingface tokenizersのトークナイザートレーニングをサポートします。batch_size=1, max_len=320を構成する場合、事前トレーニングは少なくとも 16GB メモリ + 4GB ビデオ メモリを搭載したマシンでサポートされます。trainerコマンドの迅速な微調整をサポートし、トレーニングを継続するためのブレークポイントをサポートします。Huggingface trainerのsequence to sequence微調整をサポートします。peft loraの使用をサポートします。Lora adapter元のモデルに結合できます。小規模モデルに基づいて検索拡張生成 (RAG) を実行する必要がある場合は、私の他のプロジェクト Phi2-mini- Chinese を参照してください。コードについては、rag_with_langchain.ipynb を参照してください。
最新情報
すべてのデータ セットは、インターネット上で公開されている単一ラウンドの会話データ セットから取得され、データのクリーニングとフォーマットの後、寄せ木細工のファイルとして保存されます。データ処理プロセスについては、 utils/raw_data_process.pyを参照してください。主なデータセットには以下が含まれます。
Belle_open_source_1M 、 train_2M_CN 、およびtrain_3.5M_CNから、短い回答があり、複雑なテーブル構造が含まれていない一部のデータのみを選択し、翻訳タスク (英語の語彙リストなし)、合計 370 万行、クリーニング後には 338 万行が残ります。N単語が回答になります。202309 202309百科事典データを使用すると、クリーニング後に 119 万のエントリ プロンプトと回答が残ります。 Wiki のダウンロード: zhwiki、ダウンロードした bz2 ファイルを wiki.txt に変換します。参照: WikiExtractor。データセットの総数は 1,023 万、Text-to-Text 事前トレーニング セット: 930 万、評価セット: 25,000 (デコードが遅いため、評価セットはあまり大きく設定しません) です。テストセット: 900,000。 SFT 微調整および DPO 最適化データセットを以下に示します。
T5 モデル (Text-to-Text Transfer Transformer)、詳細については、論文「Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer」を参照してください。
モデルのソース コードは、huggingface から取得しています。T5ForConditionalGeneration を参照してください。
モデルの構成については、model_config.json を参照してください。公式のT5-base : encoder layerとdecoder layer両方とも 12 層ですが、このプロジェクトでは、これら 2 つのパラメーターが 10 層に変更されます。
モデルパラメータ: 0.2B。単語リストのサイズ: 29298、中国語と少量の英語のみを含む。
ハードウェア:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1トークナイザー トレーニング: 既存のtokenizerトレーニング ライブラリには、大規模なコーパスに遭遇した場合に OOM の問題があります。そのため、 BPEと同様の方法に従って、単語頻度に基づいて完全なコーパスがマージされ、構築されます。実行には半日かかります。
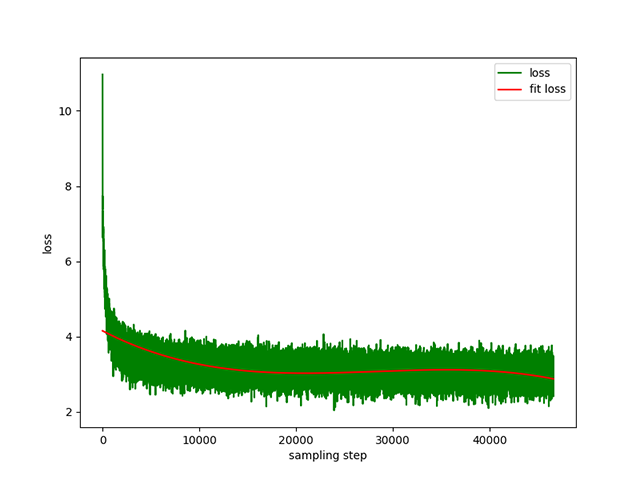
Text-to-Text の事前トレーニング: 動的学習率は1e-4 ~ 5e-3 、事前トレーニング時間は 8 日間です。トレーニング損失:
belle命令トレーニング データ セットを使用します (命令と回答の長さの両方が 512 未満)。学習率は1e-7 ~ 5e-5の動的学習率で、微調整時間はは2日です。損失の微調整: 
chosenテキストとして使用されます。ステップ2では、SFT モデル バッチがデータ セット内にプロンプトgenerate 、 rejectedテキストを取得します。これには 1 日かかります。 dpo の完全な設定を最適化して学習するには、レートはle-5 、半精度fp16 、合計2 epochで、3 時間かかります。 dpo 損失: 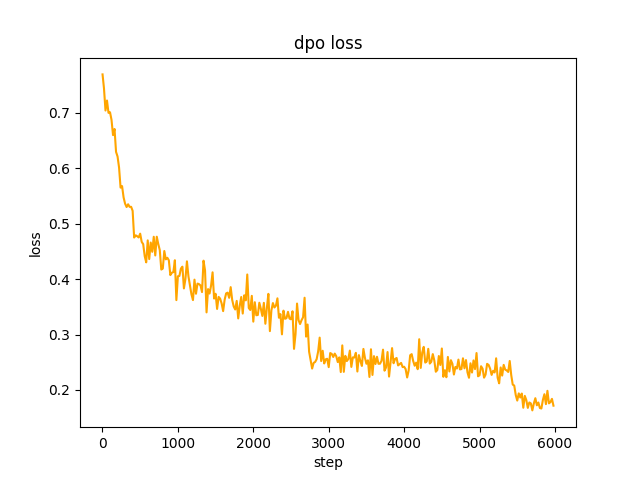
デフォルトでは、ストリーミング ダイアログの実装には、 huggingface transformersのTextIteratorStreamerが使用されます。これは、 greedy searchのみをサポートします。 beam sampleなどの他の生成メソッドが必要な場合は、 cli_demo.pyのstream_chatパラメーターをFalseに変更してください。 

問題があります。事前トレーニング データ セットには 900 万以上しかなく、モデル パラメーターはわずか 0.2B しかありません。すべての側面をカバーすることはできません。また、答えが間違っていて、ジェネレーターが無意味であるという状況も発生します。
ハグフェイスに接続できない場合は、 modelscope.snapshot_downloadを使用して、modelscope からモデル ファイルをダウンロードします。
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
注意
このプロジェクトのモデルはTextToTextモデルです。事前トレーニング、SFT、RLFH ステージのprompt 、 responseなどのフィールドには、必ず[EOS]シーケンスの終了マークを追加してください。
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chineseこのプロジェクトでは、 python 3.10の使用を推奨します。古いバージョンの Python は、依存するサードパーティのライブラリと互換性がない可能性があります。
pipのインストール:
pip install -r ./requirements.txtpip が CPU バージョンの pytorch をインストールした場合は、次のコマンドを使用して CUDA バージョンの pytorch をインストールできます。
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118condaのインストール:
conda install --yes --file ./requirements.txtgitコマンドを使用して、 Hugging Face Hubからモデルの重みと構成ファイルをダウンロードします。まず Git LFS をインストールしてから、以下を実行する必要があります。
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_saveまた、 Hugging Face Hubウェアハウス ChatLM- Chinese-0.2B から手動で直接ダウンロードし、ダウンロードしたファイルをmodel_saveディレクトリに移動することもできます。
コーパスの要件は、可能な限り完全である必要があります。百科事典、コード、論文、ブログ、会話など、複数のコーパスを追加することをお勧めします。
このプロジェクトは主にウィキ中国語百科事典に基づいています。中国語 Wiki コーパスの入手方法: 中国語 Wiki ダウンロード アドレス: zhwiki、 zhwiki-[存档日期]-pages-articles-multistream.xml.bz2ファイル (約 2.7GB) をダウンロード、ダウンロードした bz2 ファイルを wiki.txt に変換します 参考: WikiExtractor , 次にPythonのOpenCCライブラリを使って簡体字中国語に変換し、最後に取得したwiki.simple.txtプロジェクトルートディレクトリのdataディレクトリに置きます。複数のコーパスを 1 つのtxtファイルにマージしてください。
トレーニング トークナイザーは大量のメモリを消費するため、コーパスが非常に大きい場合 (マージされたtxtファイルが 2G を超える)、トレーニング時間とメモリ消費を削減するためにカテゴリと割合に従ってコーパスをサンプリングすることをお勧めします。 1.7 GB のtxtファイルをトレーニングするには、約 48 GB のメモリが必要です (推定、32 GB しかなく、スワップが頻繁にトリガーされ、コンピューターが長時間スタックします T_T)。13600k CPU では約 1 時間かかります。
char levelとbyte levelの違いは次のとおりです (具体的な使用方法の違いについては、各自で情報を検索してください)。トークナイザーはデフォルトでchar levelをトレーニングします。 byte levelが必要な場合は、 train_tokenizer.pyでtoken_type='byte'を設定するだけです。
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']トレーニングを開始します:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab または jupyter ノートブック:
ファイルtrain.ipynbを参照してください。サーバーから切断した後に端末プロセスが強制終了される状況を考慮しないように、jupyter-lab を使用することをお勧めします。
コンソール:
コンソール トレーニングでは、接続が切断された後にプロセスが強制終了されることを考慮する必要があります。接続セッションを確立するには、プロセス デーモン ツールSupervisorまたはscreenを使用することをお勧めします。
まず、 accelerateを設定し、次のコマンドを実行し、プロンプトに従ってaccelerate.yamlを選択します。注: DeepSpeed を Windows にインストールするのはさらに面倒です。
accelerate configトレーニングを開始します。プロジェクトによって提供される構成を使用する場合は、次のaccelerate launchの後にパラメーター--config_file ./accelerate.yamlを追加してください。この構成は、単一マシンの 2xGPU 構成に基づいています。
事前トレーニング用のスクリプトは 2 つあり、このプロジェクトで実装されるトレーナーはtrain.pyに対応し、huggingface で実装されるトレーナーはpre_train.pyに対応します。どちらを使用しても効果は同じです。このプロジェクトに実装されたトレーナーは、より美しいトレーニング情報を表示し、トレーニングの詳細 (損失関数、ログ記録など) を簡単に変更できるようにします。 このプロジェクトに実装されたトレーナーは、トレーニングを継続するためのすべてのサポートをサポートします。任意の位置でブレークポイントctrl+cを押すと、スクリプトを終了するときにブレークポイント情報が保存されます。
単一のマシンと単一のカード:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py複数のカードを備えた単一マシン: 2グラフィックス カードの数です。実際の状況に応じて変更してください。
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyブレークポイントからトレーニングを続行します。
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pySFT データセットはすべて BELLE ボスの貢献によるものです、ありがとう。 SFT データ セットは、generated_chat_0.4M、train_0.5M_CN、train_2M_CN で、クリーニング後に約 137 万行が残ります。 sft コマンドを使用したデータセットの微調整の例:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} dataディレクトリ内のサンプルparquetファイルを参照して、独自のデータ セットを作成します。 データ セットの形式は次のとおりです。 parquetファイルは、プロンプトを表すpromptテキストの 1 列と、 responseテキストの 1 列の 2 つの列に分かれています。これは、予想されるモデル出力を表します。 微調整の詳細については、 model/trainer.pyのtrainメソッドを参照してください。 is_finetuneがTrueに設定されている場合、微調整はデフォルトで埋め込み層とエンコーダー層をフリーズし、デコーダーのみをトレーニングします。層。他のパラメータを固定する必要がある場合は、自分でコードを調整してください。
SFT 微調整を実行します。
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.py一般的に推奨される 2 つの方法は、PPO と DPO です。具体的な実装については、論文やブログを検索してください。
PPO手法(近似優先最適化、近接ポリシー最適化)
ステップ 1: 微調整データ セットを使用して、教師あり微調整 (SFT、教師付き微調整) を実行します。
ステップ 2: プリファレンス データ セット (プロンプトには少なくとも 2 つの応答が含まれます。1 つは必要な応答、1 つは不要な応答です。複数の応答はスコアによって並べ替えることができ、最も必要なものが最も高いスコアになります) を使用して、報酬モデル (RM) をトレーニングします。 、報酬モデル)。 peftライブラリを使用すると、Lora 報酬モデルをすばやく構築できます。
ステップ 3: RM を使用して SFT モデルに対して教師あり PPO トレーニングを実行し、モデルが設定を満たすようにします。
DPO (直接優先最適化) 微調整を使用します (このプロジェクトでは、ビデオ メモリを節約する DPO 微調整方法を使用します)。SFT モデルの取得に基づいて、肯定的な答えを得るために報酬モデルをトレーニングする必要はありません ()。選択済み) と否定的な回答 (拒否済み) ) を選択して、微調整を開始します。微調整されたchosenテキストは元のデータ セット alpaca-gpt4-data-zh から取得され、 rejectedテキストは 1 エポックの SFT 微調整後のモデル出力から取得されます (他の 2 つのデータ セット: huozi_rlhf_data_json および rlhf-reward-)。 single-round-trans_chinese、マージ後 合計 80,000 dpo データ。
dpo データセットの処理プロセスについては、 utils/dpo_data_process.pyを参照してください。
DPO 設定最適化データセットの例:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}設定の最適化を実行します。
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.pymodel_saveディレクトリに次のファイルがあることを確認してください。これらのファイルはHugging Face Hubウェアハウス ChatLM- Chinese-0.2B にあります。
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
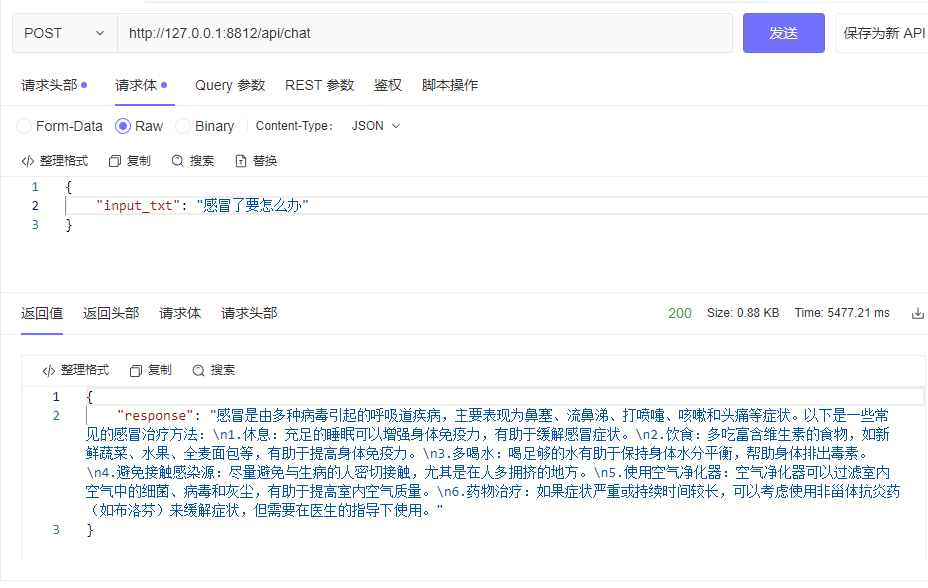
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyAPI呼び出しの例:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
ここでは、ダウンストリームの微調整を行うための例として、テキスト内のトリプレット情報を取り上げます。このタスクの従来の深層学習抽出方法については、ウェアハウス pytorch_IE_model を参照してください。テキスト内のすべてのトリプルを抽出します。たとえば、 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮トリプル (スケッチ エッセイ、著者、張 来良) と(写生随笔,出版社,冶金工业) (写生随笔,作者,张来亮)を抽出します。 (写生随笔,出版社,冶金工业) 。
元のデータ セットは、Baidu トリプル抽出データ セットです。処理された微調整されたデータセット形式の例:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
}微調整にはsft_train.pyスクリプトを直接使用できます。finetune_IE_task.ipynb スクリプトには、詳細なデコード プロセスが含まれています。トレーニング データ セットには約17000項目があり、学習率5e-5 、トレーニング エポック5 。他のタスクの対話機能は、微調整後も消えていません。

効果の微調整:百度三元组抽取数据集公開されたdevデータ セットを、従来の方法 pytorch_IE_model と比較するためのテスト セットとして使用します。
| モデル | F1スコア | 精密P | リコールR |
|---|---|---|---|
| ChatLM-中国語-0.2B 微調整 | 0.74 | 0.75 | 0.73 |
| ChatLM- Chinese-0.2B 事前トレーニングなし | 0.51 | 0.53 | 0.49 |
| 従来の深層学習手法 | 0.80 | 0.79 | 80.1 |
注: ChatLM-Chinese-0.2B无预训练ランダム パラメーターを直接初期化し、 1e-4の学習率でトレーニングを開始することを意味します。他のパラメーターは微調整と一致します。
モデル自体は、大規模なデータセットを使用してトレーニングされておらず、多肢選択式の質問に答えるための指示に合わせて微調整されていません。C-Eval スコアは基本的にベースライン レベルであり、必要に応じて参照として使用できます。 C-Eval 評価コードを参照: eval/c_eavl.ipynb
| カテゴリ | 正しい | 質問数 | 正確さ |
|---|---|---|---|
| 人文科学 | 63 | 257 | 24.51% |
| 他の | 89 | 384 | 23.18% |
| 幹 | 89 | 430 | 20.70% |
| 社会科学 | 72 | 275 | 26.18% |
このプロジェクトが役立つと思われる場合は、引用してください。
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
このプロジェクトは、オープンソースのモデルやコード、またはモデルが誤解されたり、悪用されたり、広められたり、不適切に利用されたりすることによって引き起こされるデータ セキュリティと世論のリスクから生じるリスクと責任を負いません。


