featuretools
v1.31.0
「機械学習の聖杯の 1 つは、特徴エンジニアリング プロセスをますます自動化することです。」 ― ペドロ ドミンゴス、機械学習について知っておくと役立ついくつかのこと

Featuretools は、自動特徴量エンジニアリング用の Python ライブラリです。詳細については、ドキュメントを参照してください。
pipでインストール
python -m pip install featuretools
または、conda の Conda-forge チャネルから:
conda install -c conda-forge featuretools
以下を実行して、アドオンを個別にインストールすることも、一度にすべてをインストールすることもできます。
python -m pip install "featuretools[complete]"
プレミアム プリミティブ- プレミアム プリミティブ リポジトリからプレミアム プリミティブを使用します。
python -m pip install "featuretools[premium]"
NLP プリミティブ- nlp-primitives リポジトリの自然言語プリミティブを使用します。
python -m pip install "featuretools[nlp]"
Dask サポート- Dask を使用して、njobs > 1 で DFS を実行します
python -m pip install "featuretools[dask]"
以下は、深部特徴合成 (DFS) を使用して自動特徴エンジニアリングを実行する例です。この例では、タイムスタンプ付きの顧客トランザクションで構成される複数テーブルのデータセットに DFS を適用します。
>> import featuretools as ft
>> es = ft . demo . load_mock_customer ( return_entityset = True )
>> es . plot ()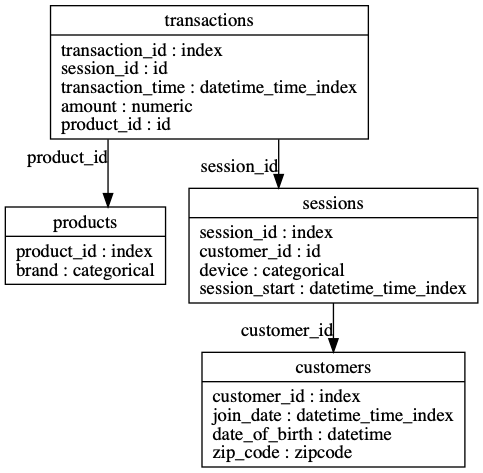
Featuretools は、任意の「ターゲット データフレーム」に対して単一の特徴テーブルを自動的に作成できます。
>> feature_matrix , features_defs = ft . dfs ( entityset = es , target_dataframe_name = "customers" )
>> feature_matrix . head ( 5 ) zip_code COUNT(transactions) COUNT(sessions) SUM(transactions.amount) MODE(sessions.device) MIN(transactions.amount) MAX(transactions.amount) YEAR(join_date) SKEW(transactions.amount) DAY(join_date) ... SUM(sessions.MIN(transactions.amount)) MAX(sessions.SKEW(transactions.amount)) MAX(sessions.MIN(transactions.amount)) SUM(sessions.MEAN(transactions.amount)) STD(sessions.SUM(transactions.amount)) STD(sessions.MEAN(transactions.amount)) SKEW(sessions.MEAN(transactions.amount)) STD(sessions.MAX(transactions.amount)) NUM_UNIQUE(sessions.DAY(session_start)) MIN(sessions.SKEW(transactions.amount))
customer_id ...
1 60091 131 10 10236.77 desktop 5.60 149.95 2008 0.070041 1 ... 169.77 0.610052 41.95 791.976505 175.939423 9.299023 -0.377150 5.857976 1 -0.395358
2 02139 122 8 9118.81 mobile 5.81 149.15 2008 0.028647 20 ... 114.85 0.492531 42.96 596.243506 230.333502 10.925037 0.962350 7.420480 1 -0.470007
3 02139 78 5 5758.24 desktop 6.78 147.73 2008 0.070814 10 ... 64.98 0.645728 21.77 369.770121 471.048551 9.819148 -0.244976 12.537259 1 -0.630425
4 60091 111 8 8205.28 desktop 5.73 149.56 2008 0.087986 30 ... 83.53 0.516262 17.27 584.673126 322.883448 13.065436 -0.548969 12.738488 1 -0.497169
5 02139 58 4 4571.37 tablet 5.91 148.17 2008 0.085883 19 ... 73.09 0.830112 27.46 313.448942 198.522508 8.950528 0.098885 5.599228 1 -0.396571
[5 rows x 69 columns]
これで、機械学習に使用できる各顧客の特徴ベクトルが得られました。その他の例については、深部特徴合成に関するドキュメントを参照してください。
Featuretools には、フィーチャーを作成するためのさまざまなタイプの組み込みプリミティブが含まれています。必要なプリミティブが含まれていない場合、Featuretools を使用して独自のカスタム プリミティブを定義することもできます。
次の購入を予測する
リポジトリ |ノート
このデモンストレーションでは、Instacart からの 300 万件のオンライン食料品注文のマルチテーブル データセットを使用して、顧客が次に何を買うかを予測します。自動化された特徴量エンジニアリングで特徴量を生成し、複数の予測問題に再利用できる Featuretools を使用して正確な機械学習パイプラインを構築する方法を示します。より上級のユーザー向けに、Dask を使用してそのパイプラインを大規模なデータセットに拡張する方法を示します。
Featuretools の使用方法のその他の例については、デモ ページをご覧ください。
Featuretools コミュニティはプル リクエストを歓迎します。テストと開発の手順はここから入手できます。
Featuretools コミュニティは、Featuretools のユーザーに喜んでサポートを提供します。プロジェクト サポートは、質問の種類に応じて 4 つの場所で見つけることができます。
featuretoolsタグを付けて Stack Overflow を使用してください。Featuretools を使用する場合は、次の論文を引用することを検討してください。
ジェームズ・マックス・カンター、カリヤン・ヴィーラマチャネニ。深層特徴合成: データ サイエンスの取り組みの自動化に向けて。 IEEE DSAA 2015 。
BibTeX エントリ:
@inproceedings { kanter2015deep ,
author = { James Max Kanter and Kalyan Veeramachaneni } ,
title = { Deep feature synthesis: Towards automating data science endeavors } ,
booktitle = { 2015 {IEEE} International Conference on Data Science and Advanced Analytics, DSAA 2015, Paris, France, October 19-21, 2015 } ,
pages = { 1--10 } ,
year = { 2015 } ,
organization = { IEEE }
}Featuretools は、 Alteryx によって管理されているオープン ソース プロジェクトです。私たちが取り組んでいる他のオープンソース プロジェクトを確認するには、Alteryx Open Source にアクセスしてください。影響力のあるデータ サイエンス パイプラインの構築がお客様またはお客様のビジネスにとって重要である場合は、ご連絡ください。


