lance
v0.20.0

ML 用の最新の列指向データ形式。 2 行のコードで Parquet から変換し、100 倍高速なランダム アクセス、ベクトル インデックス、データのバージョン管理などを実現します。
pandas、DuckDB、Polars、pyarrow と互換性があり、今後さらに多くの統合が予定されています。
ドキュメント • ブログ • Discord • Twitter
Lance は、ML ワークフローとデータセット用に最適化された最新の列指向データ形式です。ランスは以下のような方に最適です。
ランスの主な機能は次のとおりです。
高性能ランダム アクセス:スキャン パフォーマンスを犠牲にすることなく、Parquet よりも 100 倍高速です。
ベクトル検索:最近傍をミリ秒単位で検索し、OLAP クエリとベクトル検索を組み合わせます。
ゼロコピー、自動バージョン管理:追加のインフラストラクチャを必要とせずにデータのバージョンを管理します。
エコシステムの統合: Apache Arrow、Pandas、Polars、DuckDB などが計画中です。
ヒント
Lance は積極的に開発中であり、貢献を歓迎します。詳細については、貢献ガイドをご覧ください。
インストール
pip install pylanceプレビュー リリースをインストールするには:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceヒント
プレビュー リリースは完全リリースよりも頻繁にリリースされ、最新の機能とバグ修正が含まれています。完全リリースと同じレベルのテストを受けます。少なくとも 6 か月間は公開され、ダウンロードできる状態が維持されることを保証します。特定のバージョンに固定したい場合は、安定したリリースを優先してください。
ランスへの転向
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )ランスデータの読み込み
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )パンダ
df = dataset . to_table (). to_pandas ()
dfアヒルDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()ベクトル検索
sift1m サブセットをダウンロードする
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzランスに変換する
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )インデックスを構築する
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQデータセットを検索する
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| ディレクトリ | 説明 |
|---|---|
| さび | コアRustの実装 |
| パイソン | Python バインディング (pyo3) |
| ドキュメント | ドキュメントのソース |
ここでは、Lance のデザインのいくつかの側面に焦点を当てます。詳細については、Lance 設計ドキュメント全体を参照してください。
ベクトルインデックス: 埋め込み空間上の類似性検索のためのベクトルインデックス。 CPU ( x86_64およびarm ) と GPU ( Nvidia (cuda)およびApple Silicon (mps) ) の両方をサポートします。
エンコーディング: 高速列指向スキャンとサブリニア ポイント クエリの両方を実現するために、Lance はカスタム エンコーディングとレイアウトを使用します。
ネストされたフィールド: Lance は、「検出されたオブジェクトに猫が含まれる画像を検索する」などの効率的なフィルターをサポートするために、各サブフィールドを個別の列として保存します。
バージョン管理: マニフェストを使用してスナップショットを記録できます。現在、追加、上書き、インデックス作成による新しいバージョンの自動作成をサポートしています。
高速アップデート(ROADMAP): アップデートは、先行書き込みログを介してサポートされます。
豊富なセカンダリインデックス(ロードマップ):
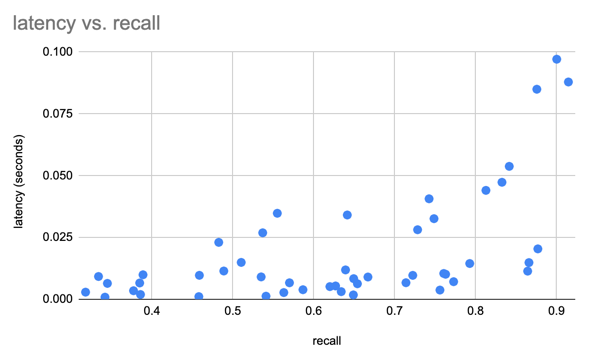
SIFT データセットを使用して、128D の 1M ベクトルで結果をベンチマークしました。
Oxford Pet データセットを使用して Lance データセットを作成し、Parquet および生の画像/XML と比較した Lance の予備パフォーマンス テストを行います。分析クエリの場合、Lance は生のメタデータを読み取るよりも 50 ~ 100 倍優れています。バッチランダムアクセスの場合、Lance は寄木細工のファイルと生のファイルの両方よりも 100 倍優れています。

機械学習の開発サイクルには次のステップが含まれます。
グラフLR
A[コレクション] --> B[探索];
B --> C[分析];
C --> D[機能エンジニア];
D --> E[トレーニング];
E --> F[評価];
F --> C;
E --> G[展開];
G --> H[監視];
H --> A;
人々はパフォーマンスのさまざまな段階に応じて異なるデータ表現を使用したり、利用可能なツールによって制限されたりしています。学術界は主に注釈に XML / JSON を使用し、深層学習には圧縮された画像/センサー データを使用しますが、データ インフラストラクチャに統合するのが難しく、クラウド ストレージでのトレーニングには時間がかかります。業界ではデータレイク (Parquet ベースの技術、つまり Delta Lake、Iceberg) またはデータ ウェアハウス (AWS Redshift または Google BigQuery) を使用してデータを収集および分析していますが、データを Rikai/ペタストームまたはTFRecord。複数の単一目的のデータ変換や、クラウド ストレージとローカル トレーニング インスタンス間のコピーの同期が一般的になってきました。
既存のデータ形式はいずれも、当初の目的で設計されたワークロードでは優れていますが、データ サイロを削減するには、多段階の ML 開発サイクルに合わせて調整された新しいデータ形式が必要です。
ML 開発サイクルの各段階におけるさまざまなデータ形式の比較。
| ランス | 寄木細工とORC | JSON と XML | TFレコード | データベース | 倉庫 | |
|---|---|---|---|---|---|---|
| 分析 | 速い | 速い | 遅い | 遅い | ちゃんとした | 速い |
| 特徴量エンジニアリング | 速い | 速い | ちゃんとした | 遅い | ちゃんとした | 良い |
| トレーニング | 速い | ちゃんとした | 遅い | 速い | 該当なし | 該当なし |
| 探検 | 速い | 遅い | 速い | 遅い | 速い | ちゃんとした |
| インフラサポート | リッチ | リッチ | ちゃんとした | 限定 | リッチ | リッチ |
Lance は現在、実稼働環境で次のように使用されています。


