qlib
v0.9.5 ?

最近リリースされた機能
 : 産業用データ駆動型研究開発向けの LLM ベースの自律進化エージェント
: 産業用データ駆動型研究開発向けの LLM ベースの自律進化エージェントクオンツ投資の研究開発における自動化されたファクターマイニングとモデルの最適化をサポートする強力なツールであるRD-Agent ? のリリースを発表できることを嬉しく思います。
RD-Agent は GitHub で利用できるようになりました。あなたのスターを歓迎します?!
詳細については、♾️デモページをご覧ください。ここには、RD-Agent のシナリオと使用法をより深く理解するのに役立つ、英語と中国語のデモ ビデオがあります。
いくつかのデモビデオを用意しました。
| シナリオ | デモビデオ(英語) | デモビデオ (中文) |
|---|---|---|
| クオンツファクターマイニング | リンク | リンク |
| レポートからの量的要素マイニング | リンク | リンク |
| 定量モデルの最適化 | リンク | リンク |
| 特徴 | 状態 |
|---|---|
| エンドツーエンド学習のための BPQP | ?近日公開予定(検討中) |
| LLM 主導の自動定量ファクトリー | 2024 年 8 月 8 日に ♾️RD-Agent でリリース |
| KRNN とサンドイッチ モデル | ? 2023年5月26日発売 |
| Qlib v0.9.0 をリリース | 2022 年 12 月 9 日発売 |
| RL 学習フレームワーク | ? ? 2022 年 11 月 10 日リリース。#1332、#1322、#1316、#1299、#1263、#1244、#1169、#1125、#1076 |
| HIST および IGMTF モデル | ? 2022 年 4 月 10 日発売 |
| Qlib ノートブックのチュートリアル | 2022 年 4 月 7 日発売 |
| Ibovespa指数データ | ? 2022 年 4 月 6 日発売 |
| ポイントインタイムデータベース | ? 2022 年 3 月 10 日発売 |
| Arctic プロバイダーのバックエンドとオーダーブックのデータの例 | ? 2022 年 1 月 17 日発売 |
| メタラーニングベースのフレームワークとDDG-DA | ? ? 2022 年 1 月 10 日発売 |
| 計画ベースのポートフォリオ最適化 | ? 2021年12月28日発売 |
| Qlib v0.8.0 をリリース | 2021年12月8日発売 |
| モデルの追加 | ? 2021年11月22日発売 |
| アダーンモデル | ? 2021年11月14日発売 |
| TCNモデル | ? 2021年11月4日発売 |
| ネストされた意思決定フレームワーク | ? 2021 年 10 月 1 日にリリースされました。例とドキュメント |
| テンポラル ルーティング アダプター (TRA) | ? 2021年7月30日発売 |
| トランスフォーマーとローカルフォーマー | ? 2021年7月22日発売 |
| Qlib v0.7.0 をリリース | 2021年7月12日発売 |
| TCTSモデル | ? 2021年7月1日発売 |
| オンライン サービングと自動モデル ローリング | ? 2021年5月17日発売 |
| ダブルアンサンブルモデル | ? 2021年3月2日発売 |
| 高周波データ処理例 | ? 2021年2月5日発売 |
| 高頻度取引の例 | ? 2021 年 1 月 28 日にリリースされたコードの一部 |
| 高周波データ(1分) | ? 2021年1月27日発売 |
| タブネットモデル | ? 2021年1月22日発売 |
2021 年より前にリリースされた機能はここにはリストされていません。

Qlib は、オープンソースの AI 指向の定量的投資プラットフォームであり、アイデアの探索から生産の実装に至るまで、定量的投資において AI テクノロジーを使用して可能性を実現し、研究を強化し、価値を創造することを目的としています。 Qlib は、教師あり学習、市場ダイナミクス モデリング、強化学習など、さまざまな機械学習モデリング パラダイムをサポートします。
クオンツ投資における重要な課題を共同で解決するために、多様なパラダイムにおける SOTA Quant の研究成果や論文が Qlib でリリースされることが増えています。たとえば、1) 教師あり学習を使用して豊富で異種の金融データから市場の複雑な非線形パターンをマイニングする、2) 適応概念ドリフト技術を使用して金融市場の動的な性質をモデル化する、3) 強化学習を使用して継続的投資をモデル化する、などです。意思決定を行い、投資家が取引戦略を最適化できるよう支援します。
これには、データ処理、モデルのトレーニング、バックテストの完全な ML パイプラインが含まれています。そして、アルファシーク、リスクモデリング、ポートフォリオの最適化、注文執行といったクオンツ投資のチェーン全体をカバーします。詳細については、論文「Qlib: AI 指向の定量的投資プラットフォーム」を参照してください。
| フレームワーク、チュートリアル、データ、DevOps | クオンツリサーチにおける主な課題と解決策 |
|---|---|
|
|
開発中の新機能 (リリース予定時間順)。機能に関するフィードバックは非常に重要です。

Qlib の高レベルのフレームワークは上記で見つけることができます (ユーザーは、核心に迫るときに Qlib の設計の詳細なフレームワークを見つけることができます)。これらのコンポーネントは疎結合モジュールとして設計されており、各コンポーネントはスタンドアロンで使用できます。
Qlib は、Quant 研究をサポートする強力なインフラストラクチャを提供します。データは常に重要な部分です。強力な学習フレームワークは、多様な学習パラダイム (強化学習、教師あり学習など) とさまざまなレベルのパターン (市場動的モデリングなど) をサポートするように設計されています。市場をモデル化することにより、取引戦略により実行される取引決定が生成されます。異なるレベルまたは粒度の複数の取引戦略とエグゼキュータをネストして最適化し、一緒に実行できます。最終的には、包括的な分析が提供され、モデルをオンラインで低コストで提供できるようになります。
このクイック スタート ガイドでは、次のことを説明します。
ここでは、 Qlibをインストールし、 qrunで LightGBM を実行する方法を示す簡単なデモを示します。ただし、指示に従ってデータがすでに準備されていることを確認してください。
この表は、サポートされているQlibの Python バージョンを示しています。
| pipでインストール | ソースからインストールする | プロット | |
|---|---|---|---|
| Python 3.7 | ✔️ | ✔️ | ✔️ |
| Python 3.8 | ✔️ | ✔️ | ✔️ |
| Python 3.9 | ✔️ |
注記:
conda環境の外で Python を使用するとヘッダー ファイルが欠落し、特定のパッケージのインストールが失敗することがあります。Qlibインストールするときにエラーが発生することに注意してください。ユーザーがマシンで Python 3.6 を使用している場合は、Python をバージョン 3.7 にアップグレードするか、 condaの Python を使用してソースからQlibインストールすることをお勧めします。Qlibモデルのトレーニング、バックテストの実行、関連する図 (ノートブックに含まれる図) のほとんどのプロットなどのワークフローの実行をサポートします。ただし、モデルのパフォーマンスのプロットは現時点ではサポートされていないため、将来依存パッケージがアップグレードされたときにこれを修正する予定です。Qlibはtablesパッケージが必要です。テーブルのhdf5 python3.9 をサポートしていません。ユーザーは、次のコマンドに従って pip でQlib簡単にインストールできます。
pip install pyqlib注: pip は最新の安定した qlib をインストールします。ただし、qlib のメイン ブランチは活発に開発中です。最新のスクリプトまたは関数をメイン ブランチでテストしたい場合。以下の方法でqlibをインストールしてください。
また、ユーザーは次の手順に従って、ソース コードから最新の開発バージョンQlibインストールできます。
ソースからQlibインストールする前に、ユーザーはいくつかの依存関係をインストールする必要があります。
pip install numpy
pip install --upgrade cython次のようにリポジトリのクローンを作成し、 Qlibをインストールします。
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst注: python setup.py installを使用して Qlib をインストールすることもできます。しかし、それは推奨されるアプローチではありません。 pipスキップし、わかりにくい問題を引き起こします。たとえば、コマンド pip installのみですpip install . pip install pyqlibによってインストールされた安定バージョンを上書きできますが、コマンドpython setup.py install上書きできません。
ヒント: Qlibのインストールに失敗した場合、または環境でのサンプルの実行に失敗した場合は、手順と CI ワークフローを比較すると、問題の発見に役立つ場合があります。
Mac に関するヒント: M1 で Mac を使用している場合、LightGBM のホイールを構築する際に問題が発生する可能性があります。これは、OpenMP からの依存関係が欠落していることが原因です。この問題を解決するには、まずbrew install libompを使用して openmp をインストールし、次にpip install .正常に構築するために。
❗ データセキュリティポリシーがより制限されているため。公式データセットは一時的に無効になっています。コミュニティによって提供されたこのデータ ソースを試すことができます。ここでは20240809に更新されたデータをダウンロードする例です。
wget https://github.com/chenditc/investment_data/releases/download/2024-08-09/qlib_bin.tar.gz
mkdir -p ~ /.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~ /.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gz以下の公式データセットは近いうちに再開される予定です。
次のコードを実行して、データをロードして準備します。
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
このデータセットは、同じリポジトリでリリースされたクローラー スクリプトによって収集された公開データによって作成されます。ユーザーはそれを使用して同じデータセットを作成できます。データセットの説明
データは Yahoo Finance から収集されており、データが完全ではない可能性があることに注意してください。高品質のデータセットをお持ちの場合は、独自のデータを準備することをお勧めします。詳細については、関連ドキュメントを参照してください。
ユーザーが履歴データに対してモデルと戦略のみを試したい場合、このステップはオプションです。
ユーザーは一度データを手動で更新し (--trading_date 2021-05-25)、自動的に更新されるように設定することをお勧めします。
注: ユーザーは、Qlib が提供するオフライン データに基づいてデータを増分更新することはできません (データ サイズを削減するために一部のフィールドが削除されています)。ユーザーは、yahoo コレクターを使用して Yahoo データを最初からダウンロードし、段階的に更新する必要があります。
詳細については、yahoo コレクターを参照してください。
取引日ごとに「qlib」ディレクトリへのデータの自動更新(Linux)
crontabを使用します: crontab -e
時間制限のあるタスクを設定します。
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
データの手動更新
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
docker pull pyqlib/qlib_image_stable:stabledocker run -it --name < container name > -v < Mounted local directory > :/app qlib_image_stable>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~ /.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml>>> exitdocker start -i -a < container name >docker stop < container name >docker rm < container name >Qlib は、ワークフロー全体 (データセットの構築、モデルのトレーニング、バックテスト、評価を含む) を自動的に実行するqrunという名前のツールを提供します。次の手順に従って、自動定量調査ワークフローを開始し、グラフィカルなレポート分析を行うことができます。
Quant Research ワークフロー: 次のように、lightgbm ワークフロー構成 (workflow_config_lightgbm_Alpha158.yaml) を使用してqrunを実行します。
cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yamlユーザーがデバッグ モードでqrun使用したい場合は、次のコマンドを使用してください。
python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml qrunの結果は以下の通りです。結果の詳細については日中取引を参照してください。
' The following are analysis results of the excess return without cost. '
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
' The following are analysis results of the excess return with cost. '
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078 qrunとワークフローの詳細なドキュメントは次のとおりです。
グラフィカル レポート分析: jupyter notebookでexamples/workflow_by_code.ipynb実行してグラフィカル レポートを取得します。
予測信号(モデル予測)解析
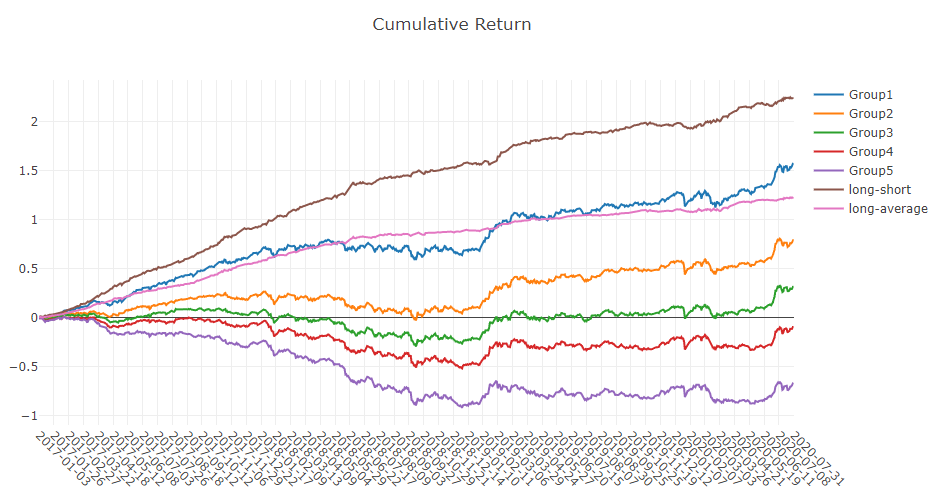
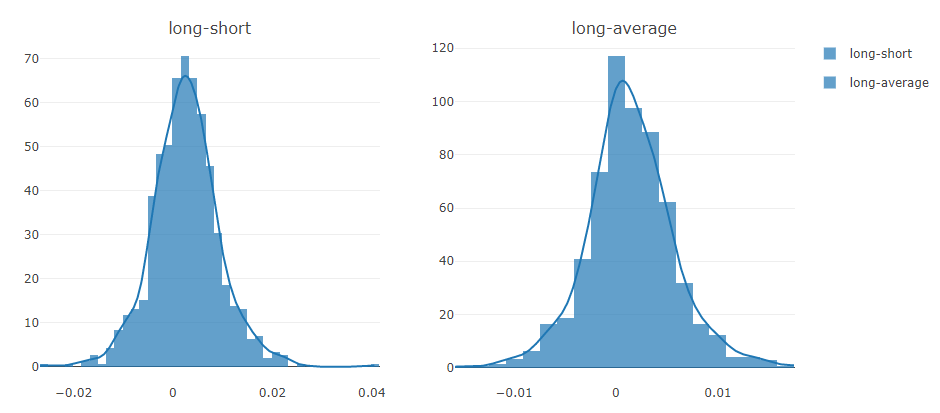
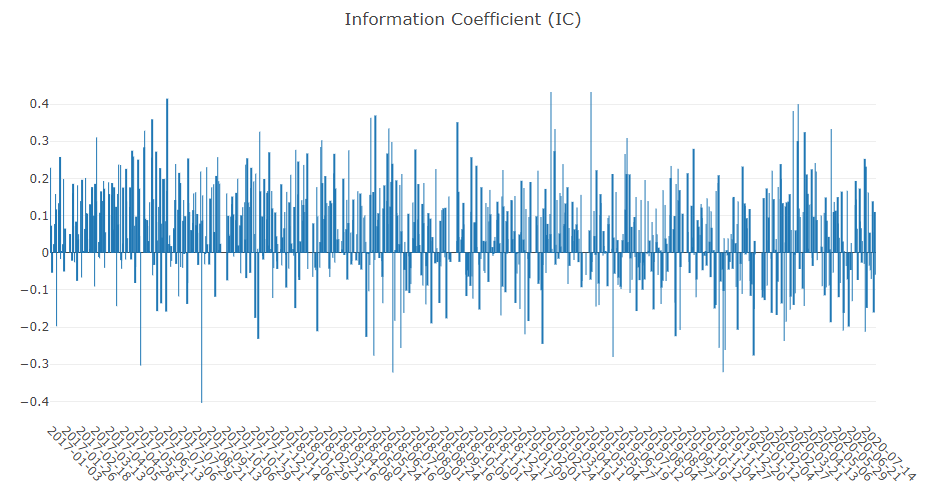
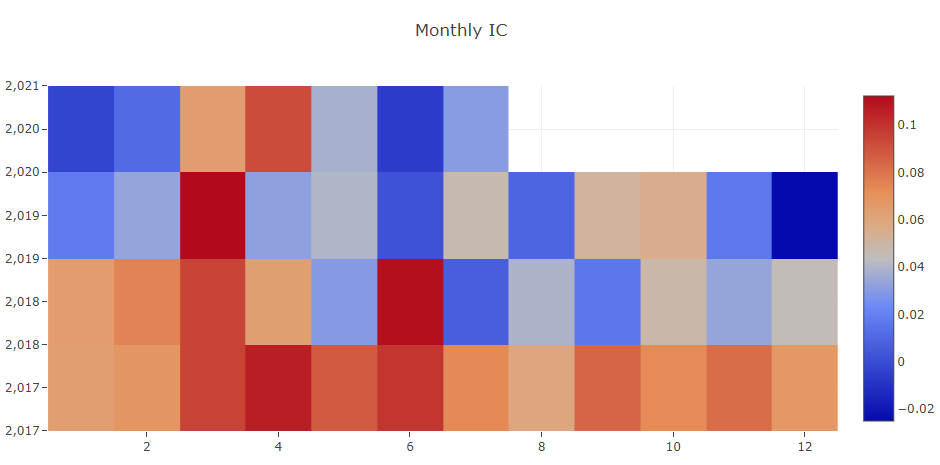
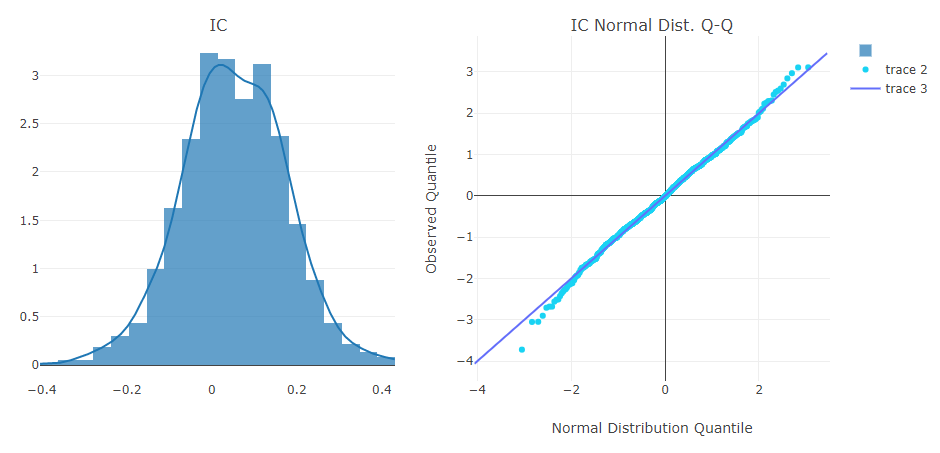
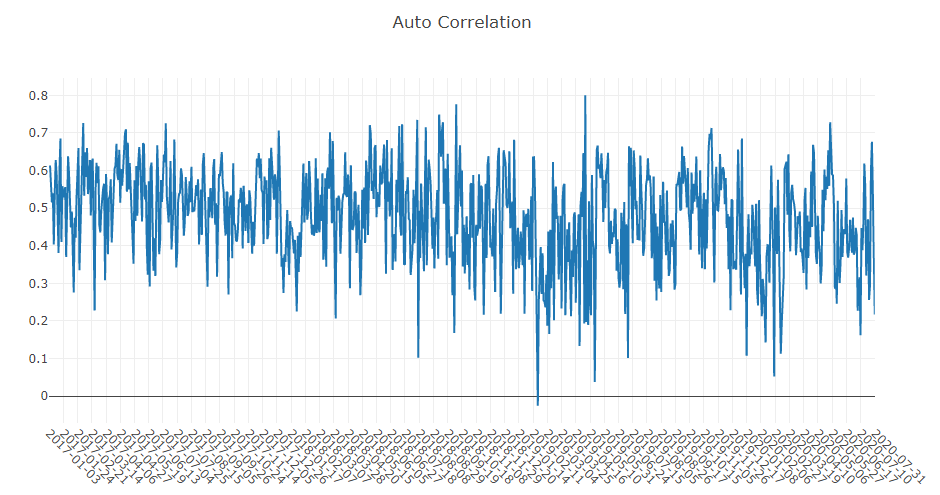
ポートフォリオ分析
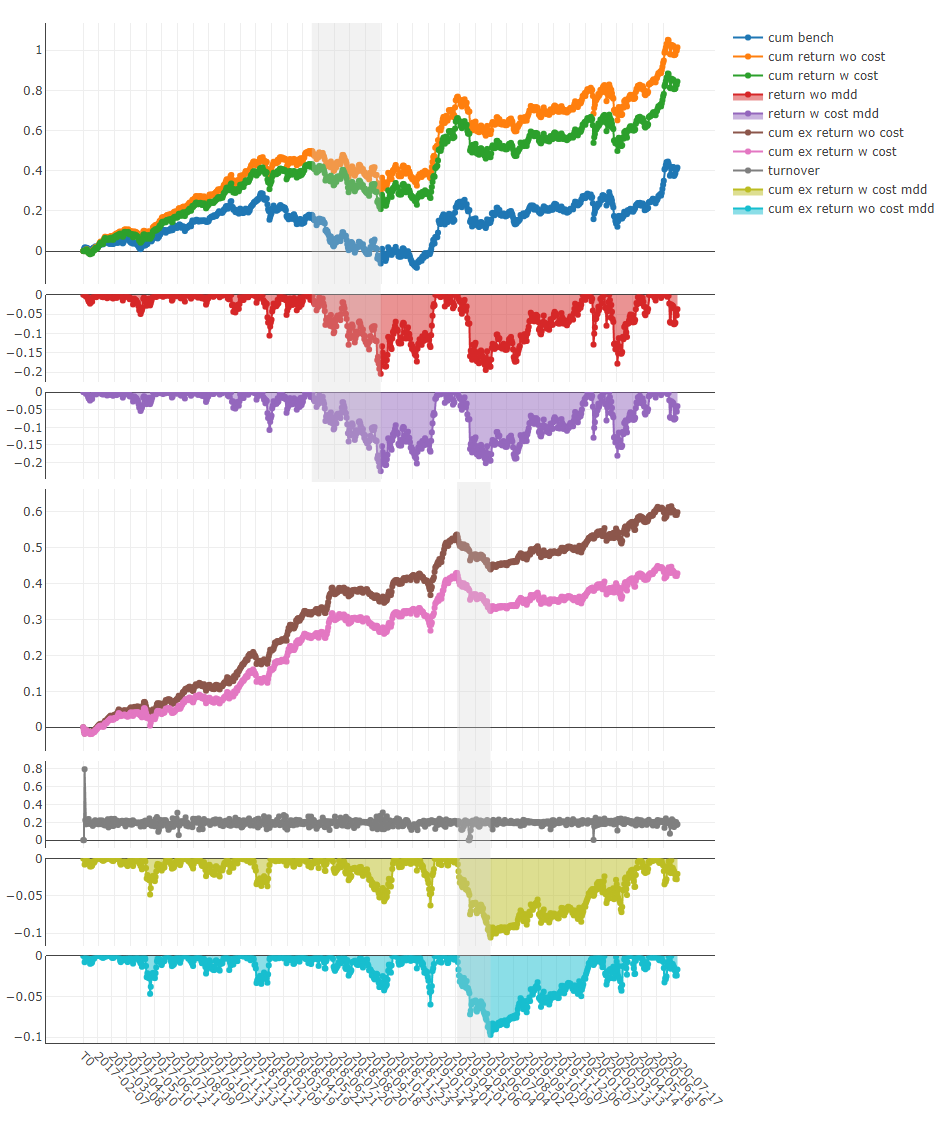
上記結果の説明
自動ワークフローは、Quant のすべての研究者の研究ワークフローに適合しない可能性があります。柔軟な Quant 研究ワークフローをサポートするために、Qlib は研究者がコードで独自のワークフローを構築できるようにするモジュール化されたインターフェイスも提供します。これは、コードによってカスタマイズされた Quant リサーチ ワークフローのデモです。
クオンツ投資は非常にユニークなシナリオであり、解決すべき重要な課題が数多くあります。現在、Qlib はそれらのいくつかに対していくつかのソリューションを提供しています。
収益性の高いポートフォリオを構築するには、株価の動向を正確に予測することが非常に重要です。しかし、金融市場にはさまざまな形式の膨大なデータがあり、予測モデルの構築が困難になっています。
複雑な財務データから貴重なシグナル/パターンをマイニングするための予測モデルの構築に焦点を当てた SOTA Quant の研究成果や論文がQlibでリリースされることが増えています。
以下はQlib上に構築されたモデルのリストです。
Quant の新モデルの PR を大歓迎です。
Alpha158およびAlpha360データセットでの各モデルのパフォーマンスは、ここで確認できます。
上記のすべてのモデルはQlibで実行可能です。ユーザーは、ベンチマーク フォルダーを通じて、提供される構成ファイルとモデルに関する詳細を見つけることができます。詳細については、上記のモデル ファイルで取得できます。
Qlib単一モデルを実行する 3 つの異なる方法を提供しており、ユーザーは自分のケースに最も適した方法を選択できます。
ユーザーは、前述のツールqrun使用して、構成ファイルに基づいてモデルのワークフローを実行できます。
ユーザーは、 examplesフォルダーにリストされているものに基づいて、 workflow_by_code Python スクリプトを作成できます。
ユーザーは、 examplesフォルダーにリストされているスクリプトrun_all_model.py使用してモデルを実行できます。使用する特定のシェル コマンドの例を次に示します。 python run_all_model.py run --models=lightgbm 。 --models引数には、上記にリストされている任意の数のモデルを指定できます (使用可能なモデルはベンチマークで見つけることができます)。その他の使用例については、ファイルの docstring を参照してください。
tensorflow==1.15.0の制限により、TFT は Python 3.6 ~ 3.7 のみをサポートします)。Qlib複数のモデルを複数の反復で実行できるスクリプトrun_all_model.pyも提供します。 (注: スクリプトは現時点ではLinuxのみをサポートしています。将来的には他の OS もサポートされる予定です。また、同じモデルを複数回並列実行することもサポートされていません。これも将来の開発で修正される予定です。)
スクリプトはモデルごとに固有の仮想環境を作成し、トレーニング後に環境を削除します。したがって、 ICおよびbacktest結果などの実験結果のみが生成および保存されます。
すべてのモデルを 10 回反復して実行する例を次に示します。
python run_all_model . py run 10また、特定のモデルを一度に実行するための API も提供します。その他の使用例については、ファイルの docstring を参照してください。
金融市場の環境は非定常であるため、データ分布はさまざまな期間で変化する可能性があり、そのため、トレーニング データに基づいて構築されたモデルのパフォーマンスは、将来のテスト データでは低下します。したがって、予測モデル/戦略を市場のダイナミクスに適応させることは、モデル/戦略のパフォーマンスにとって非常に重要です。
以下はQlib上に構築されたソリューションのリストです。
Qlib は、継続的な投資意思決定をモデル化するために設計された機能である強化学習をサポートするようになりました。この機能は、累積報酬の概念を最大化するために環境との相互作用から学習することにより、投資家が取引戦略を最適化するのに役立ちます。
ここでは、シナリオ別に分類されたQlib上に構築されたソリューションのリストを示します。
今回はこのシナリオの紹介です。ここでは、以下のすべての方法を比較します。
データセットは Quant において非常に重要な役割を果たします。 Qlib上に構築されたデータセットのリストは次のとおりです。
| データセット | 米国市場 | 中国市場 |
|---|---|---|
| アルファ360 | √ | √ |
| アルファ158 | √ | √ |
これはQlibを使用してデータセットを構築するチュートリアルです。新しい Quant データセットを構築するための PR を大歓迎します。
Qlib は高度にカスタマイズ可能であり、そのコンポーネントの多くは学習可能です。学習可能なコンポーネントはForecast ModelとTrading Agentのインスタンスです。これらはLearning Frameworkワーク層に基づいて学習され、 Workflow層の複数のシナリオに適用されます。学習フレームワークは、 Workflow層も活用します (例: Information Extractorの共有、 Execution Envに基づく環境の作成)。
学習パラダイムに基づいて、強化学習と教師あり学習に分類できます。
Workflow層のExecution Envを利用して環境を作成します。 NestedExecutorもサポートされていることは注目に値します。これにより、ユーザーはさまざまなレベルの戦略/モデル/エージェントを一緒に最適化することができます (例: 特定のポートフォリオ管理戦略に対する注文執行戦略の最適化)。qlib の最も頻繁に使用されるコンポーネントをざっと確認したい場合は、ここでノートブックを試すことができます。
詳細なドキュメントは docs にまとめられています。 HTML 形式でドキュメントを構築するには、Sphinx と readthedocs テーマが必要です。
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make html最新のドキュメントをオンラインで直接閲覧することもできます。
Qlib は活発に開発が続けられています。私たちの計画はロードマップに記載されており、github プロジェクトとして管理されています。
Qlib のデータ サーバーは、 OfflineモードまたはOnlineモードのいずれかとして展開できます。デフォルトのモードはオフライン モードです。
Offlineモードでは、データはローカルに展開されます。
Onlineモードでは、データは共有データ サービスとして展開されます。データとそのキャッシュはすべてのクライアントによって共有されます。キャッシュヒット率の向上により、データ取得パフォーマンスの向上が期待できます。消費するディスク容量も少なくなります。オンライン モードのドキュメントは Qlib-Server にあります。オンライン モードは、Azure CLI ベースのスクリプトを使用して自動的にデプロイできます。オンライン データ サーバーのソース コードは Qlib-Server リポジトリにあります。
データ処理のパフォーマンスは、AI テクノロジーのようなデータ駆動型の手法にとって重要です。 AI 指向のプラットフォームとして、Qlib はデータ ストレージとデータ処理のためのソリューションを提供します。 Qlib データ サーバーのパフォーマンスを実証するために、他のいくつかのデータ ストレージ ソリューションと比較します。
私たちは、株式市場 (2007 年から 2020 年まで毎日 800 銘柄) の基本的な OHLCV 日次データからデータセット (14 の特徴/要素) を作成する同じタスクを完了することによって、複数のストレージ ソリューションのパフォーマンスを評価します。このタスクにはデータのクエリと処理が含まれます。
| HDF5 | MySQL | モンゴDB | 流入DB | Qlib -E -D | クリブ +E -D | クリブ +E +D | |
|---|---|---|---|---|---|---|---|
| 合計 (1CPU) (秒) | 184.4±3.7 | 365.3±7.5 | 253.6±6.7 | 368.2±3.6 | 147.0±8.8 | 47.6±1.0 | 7.4±0.3 |
| 合計 (64CPU) (秒) | 8.8±0.6 | 4.2±0.2 |
+(-)E (out) ExpressionCacheがあることを示します+(-)D (out) DatasetCacheがあることを示しますほとんどの汎用データベースは、データのロードに時間がかかりすぎます。基盤となる実装を調査した結果、汎用データベース ソリューションではデータがあまりにも多くのレイヤーのインターフェイスと不必要な形式変換を通過していることがわかりました。このようなオーバーヘッドにより、データの読み込みプロセスが大幅に遅くなります。 Qlib データはコンパクトな形式で保存されるため、科学計算用に配列に組み合わせるのが効率的です。
Qlibに貢献したい場合は、プル リクエストを作成してください。IM ディスカッション グループに参加します。
| ギッター |
|---|
 |
すべての貢献に感謝し、すべての貢献者に感謝します。
2020 年 9 月に Qlib を Github でオープンソース プロジェクトとしてリリースするまで、Qlib はグループの内部プロジェクトでした。残念ながら、内部コミット履歴は保持されません。私たちのグループの多くのメンバーも Qlib に多大な貢献をしています (Ruihua Wang、yingda Zhang、Haisu Yu、Shuyu Wang、Bochen Pang、Dong Zhou など)。特に、Dong Zhou の Qlib の初期バージョンに感謝します。
このプロジェクトは貢献と提案を歓迎します。
ここでは、プル リクエストを送信するためのコード標準と開発ガイダンスをいくつか示します。
貢献することは難しいことではありません。問題の解決 (問題リストや gitter で提起された質問に答えるだけかもしれません)、バグの修正/発行、ドキュメントの改善、さらにはタイプミスの修正も、Qlib への重要な貢献です。
たとえば、Qlib のドキュメント/コードに貢献したい場合は、次の図の手順に従うことができます。

貢献を開始する方法がわからない場合は、次の例を参照してください。
| タイプ | 例 |
|---|---|
| 問題の解決 | 質問に答えてください。バグの発行または修正 |
| ドキュメント | ドキュメントの品質を向上させる。タイプミスを修正 |
| 特徴 | 要求された機能を次のように実装します。インターフェースのリファクタリング |
| データセット | データセットを追加する |
| モデル | 新しいモデルの実装、モデルに貢献するためのいくつかの手順 |
最初に適した号には、投稿を開始しやすいことを示すラベルが付けられています。
Qlib でrg 'TODO|FIXME' qlibでいくつかの不完全な実装を見つけることができます。
Qlib のメンテナーになってさらに貢献したい場合 (例: PR のマージや問題のトリアージなど)、電子メール ([email protected]) でご連絡ください。許可のアップグレードを喜んでお手伝いいたします。
ほとんどの投稿では、投稿を使用する権利をお客様が有しており、実際に当社に付与することを宣言する投稿者ライセンス契約 (CLA) に同意する必要があります。詳細については、https://cla.opensource.microsoft.com をご覧ください。
プル リクエストを送信すると、CLA ボットが CLA を提供する必要があるかどうかを自動的に判断し、PR を適切に装飾します (ステータス チェック、コメントなど)。ボットが提供する指示に従ってください。 CLA を使用するすべてのリポジトリでこれを 1 回行うだけで済みます。
このプロジェクトはマイクロソフトのオープンソース行動規範を採用しています。詳細については、「行動規範に関するよくある質問」を参照するか、追加の質問やコメントがあれば [email protected] までお問い合わせください。


