duplicut
v2.2 release
現在、パスワード ワードリストの作成には、通常、複数のデータ ソースの連結が含まれます。
理想的には、最も可能性の高いパスワードが単語リストの先頭に配置され、一般的なパスワードが即座に解読されるようにする必要があります。
既存の重複排除ツールでは、順序を保持するか、大量のワードリストを処理するかを選択する必要があります。
残念ながら、ワードリストの作成には次の両方が必要です。

それで、この非常に特殊なニーズに対処するために、高度に最適化された C で duplicut を作成しました。
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt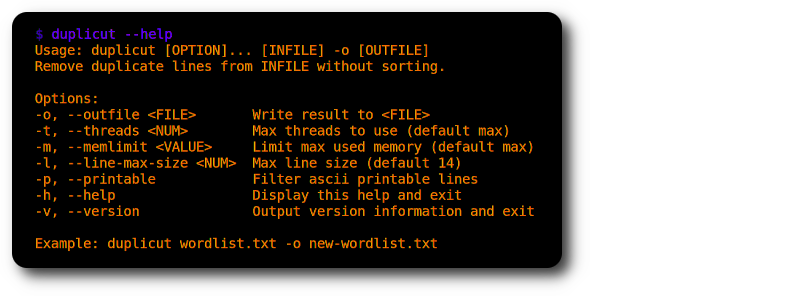
特徴:
-lオプション)-pオプション)実装:
制限事項:
uint64 、ポインタの追加ビット内にsize情報をパックすることにより、ハッシュマップ内の行にインデックスを付けるのに十分です。
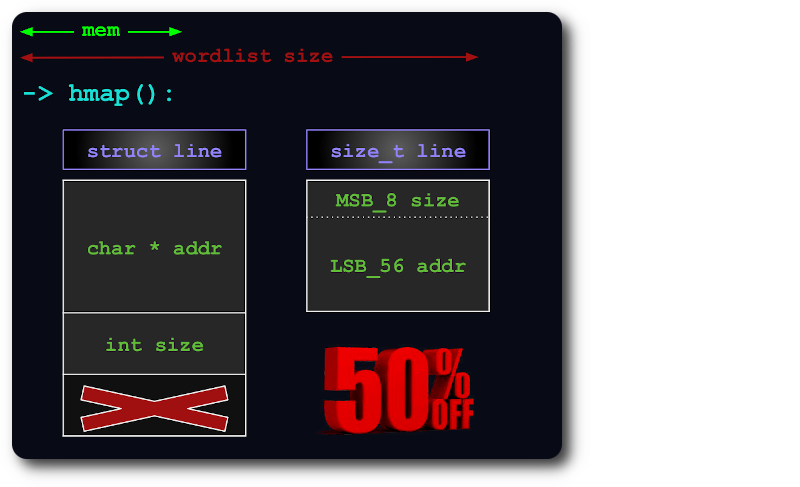
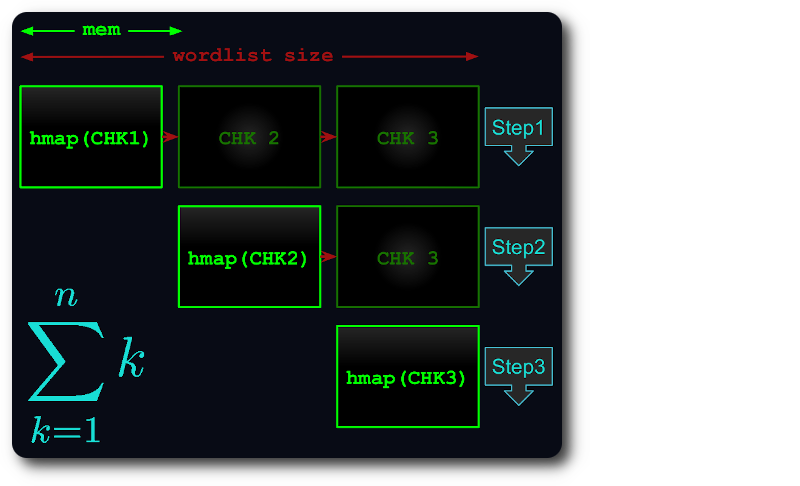
ファイル全体がメモリに収まらない場合は、各チャンクができるだけ多くの RAM を使用するように、仮想チャンクに分割されます。
次に、各チャンクがハッシュマップにロードされ、重複が除去され、後続のチャンクに対してテストされます。
こうすることで、実行時間は最大でも thトライアングル番号まで短縮されます。
バグを見つけた場合、または何かが期待どおりに動作しない場合は、duplicut をデバッグ モードでコンパイルし、出力を添付して問題を投稿してください。
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


