dream
v1.13.0
DeepPavlov Dreamは、マルチスキルの生成 AI アシスタントを作成するためのプラットフォームです。
このプラットフォームとそれを使用して AI アシスタントを構築する方法の詳細については、Dream をご覧ください。 Dream を強化する DeepPavlov Agent について詳しく知りたい場合は、DeepPavlov Agent のドキュメントを参照してください。
すでに 6 つのディストリビューションが含まれています。そのうちの 4 つは軽量の Deepy ソーシャルボットに基づいており、1 つは英語のフルサイズの Dream チャットボット (Alexa プライズ チャレンジ バージョンに基づく)、およびロシア語の Dream チャットボットです。
Lunar アシスタントの基本バージョン。 Deepy Base には、スペル チェック前処理アノテーター、テンプレート ベースのハーベスター メンテナンス スキル、およびダイアログ フロー フレームワークに基づく AIML ベースのオープンドメインの Program-y スキルが含まれています。
ルナーアシスタントの上級バージョン。 Deepy Advanced には、スペル前処理、文の分割、エンティティ リンクおよびインテント キャッチャー アノテーター、目標指向の応答のためのハーベスター メンテナンス GoBot スキル、およびダイアログ フロー フレームワークに基づく AIML ベースのオープンドメイン Program-y スキルが含まれています。
Lunar アシスタントの FAQ バージョン。 Deepy FAQ には、スペル チェック前処理アノテーター、テンプレート ベースのよくある質問スキル、およびダイアログ フロー フレームワークに基づく AIML ベースのオープンドメインの Program-y スキルが含まれています。
Lunar アシスタントの目標指向バージョン。 Deepy GoBot Base には、スペル チェック前処理アノテーター、目標指向の応答のためのハーベスターズ メンテナンス GoBot スキル、ダイアログ フロー フレームワークに基づく AIML ベースのオープンドメイン Program-y スキルが含まれています。
DeepPavlov Dream Socialbot のフルバージョン。これは、Alexa プライズ チャレンジ 4 の終了時とほぼ同じバージョンの DREAM ソーシャルボットです。一部の API サービスはトレーニング可能なモデルに置き換えられています。一部のサービス (ニュース アノテーター、ゲーム スキル、天気スキルなど) では、基礎となる API の秘密キーが必要ですが、そのほとんどは無料で取得できます。これらのサービスをローカル デプロイメントで使用する場合は、キーを環境変数 ( ./.env 、 ./.env_ruなど) に追加します。 Dream Socialbot のこのバージョンは、モジュール式アーキテクチャと当初の目標 (Alexa プライズ チャレンジへの参加) のため、大量のリソースを消費します。 Dream Socialbot のデモを Web サイトで提供しています。
DeepPavlov Dream Socialbot のミニバージョン。これは、英語の DialoGPT モデルを使用してほとんどの応答を生成する生成ベースのソーシャルボットです。また、特別なユーザーリクエストをカバーするためのインテントキャッチャーコンポーネントとレスポンダーコンポーネントも含まれています。配布物へのリンク。
DeepPavlov Dream Socialbot のロシア版。これは生成ベースのソーシャルボットで、DeepPavlov によるロシアの DialoGPT を使用してほとんどの応答を生成します。また、特別なユーザーリクエストをカバーするためのインテントキャッチャーコンポーネントとレスポンダーコンポーネントも含まれています。配布物へのリンク。
プロンプトベースの生成モデルを使用した DeepPavlov Dream Socialbot のミニバージョン。これは、大規模な言語モデルを使用してほとんどの応答を生成する生成ベースのソーシャルボットです。独自のプロンプト (json ファイル) を common/prompts にアップロードし、プロンプト名をPROMPTS_TO_CONSIDER (カンマ区切り) に追加できます。提供された情報は、LLM による応答生成でプロンプトとして使用されます。配布物へのリンク。
dockerのバージョンは 20 以降。docker-compose v1.29.2 のバージョン。 git clone https://github.com/deeppavlov/dream.git
docker-compose の実行中に「アクセスが拒否されました」エラーが発生した場合は、docker ユーザーが正しく構成されていることを確認してください。
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
Dream を試す最も簡単な方法は、プロキシ経由でデプロイすることです。すべてのリクエストは DeepPavlov API にリダイレクトされるため、ローカル リソースを使用する必要はありません。詳細については、「プロキシの使用法」を参照してください。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
DeepPavlov Dream コンポーネントは大量のリソースを必要とすることに注意してください。推定要件については、コンポーネントのセクションを参照してください。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
マルチ GPU 環境用の GPU 割り当てを含む構成も含まれています。
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
再構築せずに特定の Docker コンテナを再起動する必要がある場合 ( assistant_dists/dream/dev.ymlのマッピングが正しいことを確認してください):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
マルチ GPU 環境用の GPU 割り当てを含む構成も含まれています。
DeepPavlov エージェントは、コマンド ライン インターフェイス、HTTP API、および Telegram ボットなど、対話のためのいくつかのオプションを提供します。
別のターミナル タブで次を実行します。
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
ユーザー名を入力して、Dream とチャットしましょう!
ボットを開始すると、DeepPavlov のエージェント API がhttp://localhost:4242で実行されます。 API については、DeepPavlov エージェントのドキュメントから学ぶことができます。
基本的なチャット インターフェイスはhttp://localhost:4242/chatで利用できます。
現在、HTTP API の代わりにTelegram ボットがデプロイされています。 docker-compose.override.yml構成内のagent command定義を編集します。
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
注: Telegram トークンをシークレットとして扱い、パブリック リポジトリにコミットしないでください。
Dream では、いくつかの docker-compose 構成ファイルを使用します。
./docker-compose.ymlは、DeepPavlov エージェントと mongo データベースのコンテナーを含むコア構成です。
./assistant_dists/*/docker-compose.override.ymlは、ディストリビューションのすべてのコンポーネントがリストされます。
./assistant_dists/dream/dev.ymlには、Dream のデバッグを容易にするボリューム バインディングが含まれています。
./assistant_dists/dream/proxy.yml 、プロキシされたコンテナーのリストです。
デプロイメント リソースが限られている場合は、コンテナを DeepPavlov によってホストされているプロキシされたコピーに置き換えることができます。これを行うには、 proxy.yml内のコンテナ定義をオーバーライドします。例:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
この設定をデプロイメント コマンドに含めます。
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
デフォルトでは、 proxy.ymlは使用可能なすべてのプロキシ定義が含まれています。
Dream Architecture は次の図に示されています。 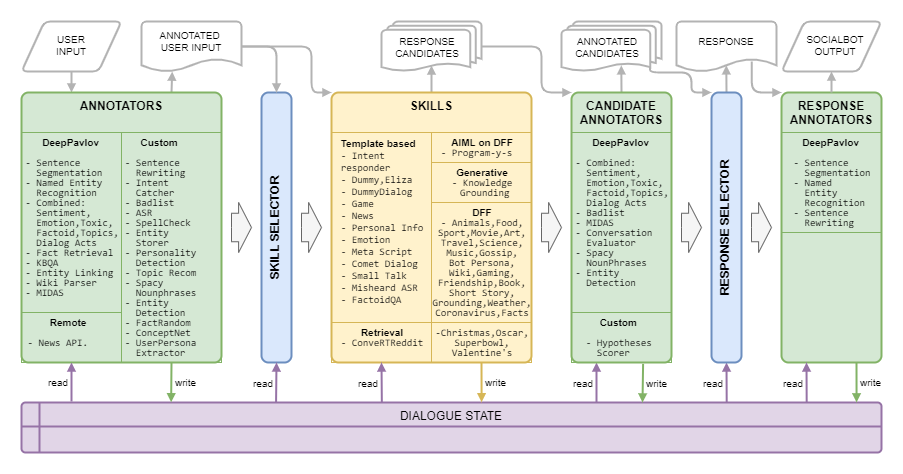
| 名前 | 要件 | 説明 |
|---|---|---|
| ルールベースのセレクター | トピック、エンティティ、感情、毒性、対話行為、対話履歴に基づいて、現在のコンテキストに対する応答候補を生成するスキルのリストを選択するアルゴリズム | |
| 応答セレクター | 50MBのRAM | 与えられた回答候補リストから最終的な回答を選択するアルゴリズム |
| 名前 | 要件 | 説明 |
|---|---|---|
| ASR | 40MBのRAM | 特定の発話に対する全体的な ASR 信頼度を計算し、非常に低い、低い、中程度、または高い(Amazon マークアップの場合) のいずれかに等級付けします。 |
| 不良リストに掲載された単語 | 150MBのRAM | バッドリストから単語やフレーズを検出します |
| 複合分類 | 1.5 GB RAM、3.5 GB GPU | トピック分類、対話行為分類、センチメント、毒性、感情、ファクトイド分類を含む BERT ベースのモデル |
| 複合分類軽量 | 1.6 GB RAM | 複合分類と同じモデルですが、バックボーンが軽量化されたことで所要時間が 42% 短縮されました |
| 彗星アトミック | 2 GB RAM、1.1 GB GPU | 常識的な予測モデル COMeT Atomic |
| COMeTコンセプトネット | 2 GB RAM、1.1 GB GPU | 常識的な予測モデル COMeT ConceptNet |
| コンバーズ評価者アノテーター | 1 GB RAM、4.5 GB GPU | 以前のコンテストの Alexa 賞データに基づいてトレーニングされ、候補者の回答が興味深いか、理解できるか、話題に合っているか、魅力的か、または間違っているかを予測します。 |
| 感情の分類 | 2.5 GB RAM | 感情分類アノテーター |
| エンティティの検出 | 1.5 GB RAM、3.2 GB GPU | 発話からエンティティとそのタイプを抽出します |
| エンティティのリンク | 2.5 GB RAM、1.3 GB GPU | エンティティ検出で検出されたエンティティのウィキデータ エンティティ ID を検索します |
| エンティティ保管者 | 220MBのRAM | ルールベースのコンポーネント。意見表現がパターンまたは MIDAS 分類子で検出された場合に、ユーザーとソーシャルボットの発話からエンティティを保存し、対話状態に対する検出された態度とともに保存します。 |
| ファクトランダム | 50MBのRAM | 指定されたエンティティ (ユーザーの発話からのエンティティ) についてランダムなファクトを返します。 |
| 事実の検索 | 7.4 GB RAM、1.2 GB GPU | Wikipedia と wikiHow から事実を抽出します |
| インテントキャッチャー | 1.7 GB RAM、2.4 GB GPU | ユーザーの発話を、フレーズと正規表現のセットでトレーニングされた多数の事前定義されたインテントに分類します。 |
| KBQA | 2 GB RAM、1.4 GB GPU | ウィキデータ KB に基づいてユーザーの事実上の質問に回答します |
| MIDAS の分類 | 1.1 GB RAM、4.5 GB GPU | MIDAS データセットのセマンティック クラス サブセットでトレーニングされた BERT ベースのモデル |
| MIDAS 予測器 | 30MBのRAM | MIDAS データセットのセマンティック クラス サブセットでトレーニングされた BERT ベースのモデル |
| NER | 2.2 GB RAM、5 GB GPU | 大文字と小文字を区別しないテキストから人名、場所の名前、組織を抽出します |
| ニュース API アノテーター | 80MBのRAM | GNews API を使用してエンティティまたはトピックに関する最新ニュースを抽出します。 DeepPavlov Dream のデプロイメントでは、独自の API キーが使用されます。 |
| パーソナリティキャッチャー | 30MBのRAM | スキルは、チャットインターフェイスを介してシステムのパーソナリティの説明を変更することです。これはシステムコマンドとして機能し、応答はシステムのようなメッセージです |
| プロンプトセレクター | 50MBのRAM | アノテーターは、Sentence Ranker を利用してプロンプトをランク付けし、最も関連性の高いプロンプトN_SENTENCES_TO_RETURNを選択します (プロンプトで提供された質問に基づいて) |
| プロパティの抽出 | 6.3 GiB RAM | 発話からユーザー属性を抽出します |
| レーキキーワード | 40MBのRAM | RAKE アルゴリズムを利用して発話からキーワードを抽出します |
| 相対的ペルソナ抽出ツール | 50MBのRAM | アノテーターは Sentence Ranker を利用してペルソナの文をランク付けし、最も関連性の高い文をN_SENTENCES_TO_RETURNを選択します。 |
| セントレライト | 200MBのRAM | 代名詞を特定の名前に置き換えることによってユーザーの発話を書き換え、下流のコンポーネントにより有用な情報を提供します。 |
| センツェグ | 1GBのRAM | ユーザーの発話を文に分割し、句読点を復元することで、長く複雑なユーザーの発話を処理できるようになります。 |
| スペーシーな名詞 | 180MBのRAM | Spacyを使用して名詞句を抽出し、一般的なものを除外します |
| 音声機能分類器 | 1.1 GB RAM、4.5 GB GPU | Eggins と Slade によって記述された音声関数の予測のための、いくつかの線形モデルとルールベースのアプローチに基づく階層アルゴリズム |
| 音声機能予測器 | 1.1 GB RAM、4.5 GB GPU | 音声関数分類器によって予測された音声関数に従う音声関数の確率を生成します。 |
| スペルチェックの前処理 | 50MBのRAM | さまざまな口語表現をよりフォーマルなスタイルの会話に書き換えるためのパターンベースのコンポーネント |
| トピックの推奨事項 | 40MBのRAM | 議論されたトピックとユーザーの好みに関する情報を使用して、さらに会話するためのトピックを提供します。現在のバージョンは Reddit のパーソナリティに基づいています (Alexa 賞 4 のドリーム レポートを参照)。 |
| 有毒物質の分類 | 3.5 GB RAM、3 GB GPU | PRETRAINED_MODEL_NAME_OR_PATH として指定された Transformers の有毒分類モデル |
| ユーザーペルソナ抽出ツール | 40MBのRAM | いくつかのキーワードに基づいてユーザーがどの年齢カテゴリに属するかを決定します |
| ウィキパーサー | 100MBのRAM | エンティティ リンクで検出されたエンティティの Wikidata トリプレットを抽出します |
| ウィキの事実 | 1.7 GB RAM | Wikipedia および WikiHow ページから関連する事実を抽出するモデル |
| 名前 | 要件 | 説明 |
|---|---|---|
| DialogGPT | 1.2 GB RAM、2.1 GB GPU | Transformers 生成モデルに基づく生成サービス。モデルは docker compose 引数PRETRAINED_MODEL_NAME_OR_PATHに設定されます (たとえば、GPU で 0.2 ~ 0.5 秒のmicrosoft/DialoGPT-small )。 |
| DialoGPT ペルソナベース | 1.2 GB RAM、2.1 GB GPU | Transformers 生成モデルに基づく生成サービス。このモデルは、ソーシャルボットのペルソナのいくつかの文に条件付けされた応答を生成するために、ペルソナチャット データセットで事前トレーニングされました。 |
| 画像のキャプション | 4 GB RAM、5.4 GB GPU | 受け取った画像のテキスト表現を作成します |
| 充填 | 1 GB RAM、1.2 GB GPU | (オフになっていますが、コードは利用可能です) Infilling モデルに基づく生成サービス。指定された発話に対して、元のテキストの_が生成されたトークンに置き換えられる発話を返します。 |
| 知識の基礎付け | 2 GB RAM、2.1 GB GPU | BlenderBot アーキテクチャに基づく生成サービス。追加のテキスト段落を考慮してコンテキストへの応答を提供します。 |
| マスクドLM | 1.1 GB RAM、1 GB GPU | (オフになっていますが、コードは利用可能です) |
| Seq2seq ペルソナベース | 1.5 GB RAM、1.5 GB GPU | Transformers seq2seq モデルに基づく生成サービス。このモデルは、ソーシャルボットのペルソナのいくつかの文に条件付けされた応答を生成するために、ペルソナチャット データセットで事前トレーニングされました。 |
| 文章ランカー | 1.2 GB RAM、2.1 GB GPU | PRETRAINED_MODEL_NAME_OR_PATHとして指定されたランキング モデル。OS 文のペアに対して対応の浮動スコアを返します。 |
| ストーリーGPT | 2.6 GB RAM、2.15 GB GPU | 微調整された GPT-2 に基づく生成サービス。指定されたキーワードのセットに対して、キーワードを使用した短編小説を返します。 |
| GPT-3.5 | 100MBのRAM | OpenAI APIサービスをベースにした生成サービスでは、docker composeの引数PRETRAINED_MODEL_NAME_OR_PATHにモデルが設定されます(特にこのサービスではtext-davinci-003が使用されます)。 |
| チャットGPT | 100MBのRAM | OpenAI APIサービスをベースにした生成サービスでは、docker composeの引数PRETRAINED_MODEL_NAME_OR_PATHにモデルが設定されます(特にこのサービスではgpt-3.5-turboが使用されます)。 |
| プロンプトストーリーGPT | 3 GB RAM、4 GB GPU | 微調整された GPT-2 に基づく生成サービス。1 つの名詞で表される特定のトピックに対して、特定のトピックに関する短編小説が返されます。 |
| GPT-J6B | 1.5 GB RAM、24.2 GB GPU | Transformers 生成モデルに基づく生成サービスでは、モデルは docker compose の引数PRETRAINED_MODEL_NAME_OR_PATHに設定されます (特に、このサービスでは GPT-J モデルが使用されます)。 |
| ブルームズ 7B | 2.5 GB RAM、29 GB GPU | Transformers 生成モデルに基づく生成サービスでは、モデルは docker compose の引数PRETRAINED_MODEL_NAME_OR_PATHに設定されます (特に、このサービスでは BLOOMZ-7b1 モデルが使用されます)。 |
| GPT-JT6B | 2.5 GB RAM、25.1 GB GPU | Transformers 生成モデルに基づく生成サービスでは、モデルは docker compose の引数PRETRAINED_MODEL_NAME_OR_PATHに設定されます (特に、このサービスでは GPT-JT モデルが使用されます)。 |
| 名前 | 要件 | 説明 |
|---|---|---|
| アレクサ・ハンドラー | 30MBのRAM | いくつかの特定の Alexa コマンドのハンドラー |
| クリスマススキル | 30MBのRAM | クリスマスに関するよくある質問、豆知識、台本をサポート |
| コメットダイアログスキル | 300MBのRAM | COMeT ConceptNet モデルを使用して、意見を表明したり、ダイアログで言及されたユーザーの行動について質問したりコメントしたりする |
| Redditを変換する | 1.2 GB RAM | ConveRT エンコーダを使用して文章の効率的な表現を構築します |
| ダミースキル | エージェントコンテナの一部 | 複数の毒性のない候補応答を含むフォールバック スキル |
| ダミースキルダイアログ | 600MBのRAM | ダミー スキルに対するユーザーの応答がソース データ内の対応する応答と類似している場合、トピック チャット データセットから次のターンを返します。 |
| エリザ | 30MBのRAM | チャットボット (https://github.com/wadetb/eliza) |
| エモーションスキル | 40MBのRAM | 複合分類アノテーターからの感情分類によって検出された感情に対するテンプレート応答を返します |
| ファクトイド QA | 170MBのRAM | 事実上の質問に答える |
| ゲーム連携スキル | 100MBのRAM | ユーザーにコンピュータ ゲームに関する会話を提供します。過去 1 年、先月、先週のベスト ゲームのチャートを示します。 |
| ハーベスターのメンテナンススキル | 30MBのRAM | ハーベスターのメンテナンススキル |
| ハーベスターのメンテナンス ゴボット スキル | 30MBのRAM | ハーベスターのメンテナンス 目標指向のスキル |
| 知識の基礎となるスキル | 100MBのRAM | 対話履歴と現在の会話トピックに関連する提供された知識に基づいて応答を生成します |
| メタスクリプトスキル | 150MBのRAM | 人間の活動に関するマルチターンの対話を提供します。このスキルは、COMeT Atomic モデルを使用して、いくつかの側面に関する常識的な説明と質問を生成します |
| ASRの聞き間違い | 40MBのRAM | ASR の信頼度が低すぎる場合、ASR プロセッサの注釈を使用してユーザーにフィードバックを提供します |
| ニュースAPIスキル | 60MBのRAM | GNews API を使用して、エンティティまたはトピックに関する最も評価の高い最新ニュースを提示します |
| オスカースキル | 30MBのRAM | Oscar の FAQ、事実、スクリプトをサポート |
| 個人情報スキル | 40MBのRAM | ユーザーの名前、出生地、および場所をクエリして保存します |
| DFF プログラム Y スキル | 800MBのRAM | 【DFF新バージョン】 Dream socialbotに対応したChatbot Program Y (https://github.com/keiffster/program-y) |
| DFF プログラム Y 危険なスキル | 100MBのRAM | [新しい DFF バージョン] Dream ソーシャルボットに適応したチャットボット プログラム Y (https://github.com/keiffster/program-y)、危険な状況に対するダイアログでの応答が含まれています |
| DFF プログラム Y ワイドスキル | 110MBのRAM | [新しい DFF バージョン] Dream ソーシャルボットに適応したチャットボット プログラム Y (https://github.com/keiffster/program-y)。非常に一般的なテンプレートのみが含まれています (信頼性は低い) |
| スモールトークスキル | 35MBのRAM | 恋愛、スポーツ、仕事、ペットなどを含む 25 のトピックについて、手書きの台本を使用して質問します。 |
| スーパーボウルのスキル | 30MBのRAM | スーパーボウルの FAQ、事実、スクリプトをサポート |
| テキストQA | 1.8 GB RAM、2.8 GB GPU | このサービスは、ファクトイドの質問に対する回答をテキストで検索します。 |
| バレンタインスキル | 30MBのRAM | バレンタインデーの FAQ、事実、スクリプトをサポート |
| ウィキデータ ダイヤル スキル | 100MBのRAM | ウィキデータのトリプレットを使用して発話を生成します。電源が入っていない、改善が必要 |
| DFFアニマルスキル | 200MBのRAM | DFF を使用して作成され、動物に関する会話の 3 つの分岐があります。ユーザーのペット、ソーシャルボットのペット、野生動物です。 |
| DFFアートスキル | 100MBのRAM | アートについて議論するための DFF ベースのスキル |
| DFFブックスキル | 400MBのRAM | [新しい DFF バージョン] は、 Wiki パーサーとエンティティ リンクを利用してユーザーの発話で言及された書籍のタイトルと著者を検出し、GoodReads データベースの情報を活用して書籍を推奨します。 |
| DFFボットのペルソナスキル | 150MBのRAM | ユーザーのお気に入りや最も人気のあるもの 20 個について、それらに対するソーシャルボットの意見を表現した短いストーリーで議論することを目的としています。 |
| DFF コロナウイルス スキル | 110MBのRAM | [新しい DFF バージョン] は、ジョン ホプキンス大学システム科学工学センターから取得した、さまざまな場所でのコロナウイルスの感染者数と死亡者数に関するデータを取得します。 |
| DFFフードスキル | 150MBのRAM | 食品関連の会話を促進するために DFF で構築 |
| DFF友情スキル | 100MBのRAM | [新しい DFF バージョン]ダイアログの先頭でユーザーに挨拶し、ユーザーをスクリプト化されたスキルに転送する DFF ベースのスキル |
| DFFファンファクトスキル | 100MBのRAM | 【DFF新バージョン】ユーザーに楽しい情報を伝える |
| DFFゲーミングスキル | 80MBのRAM | ビデオゲームのディスカッションを提供します。ゲーム スキルは、ビデオ ゲームに関するより一般的な話題を対象としています。 |
| DFFゴシップスキル | 95MBのRAM | 他の人についてのニュースについて話し合う DFF ベースのスキル |
| DFFイメージスキル | 100MBのRAM | [新しい DFF バージョン]送信された画像キャプション (注釈から) に基づいて、食べ物、動物、または人が検出された場合は指定された応答を返し、それ以外の場合はデフォルトの応答を返すスクリプト化されたスキル |
| DFFテンプレートスキル | 50MBのRAM | 【DFF新バージョン】 DFFの使用例を示すDFFベースのスキル |
| DFF テンプレートのプロンプト スキル | 50MBのRAM | [新しい DFF バージョン]指定されたプロンプトとダイアログ コンテキストに基づいて言語モデルによって生成された回答を提供する DFF ベースのスキル。使用するモデルはGENERATIVE_SERVICE_URLで指定します。たとえば、Transformer LM GPTJ サービスを使用できます。 |
| DFFグラウンディングスキル | 90MBのRAM | [新しい DFF バージョン] MIDAS による会話のトピックに答え、肯定応答を生成し、一部の対話行為に対して普遍的な応答を生成する DFF ベースのスキル |
| DFF インテント レスポンダー | 100MBのRAM | [新しい DFF バージョン] は、 Intent Catcher アノテーターによって検出された一部のインテントに対してテンプレートベースの応答を提供します |
| DFFムービースキル | 1.1 GB RAM | DFF を使用して実装され、映画に関連した会話を処理します |
| DFFミュージックスキル | 70MBのRAM | 音楽について議論するための DFF ベースのスキル |
| DFFサイエンススキル | 90MBのRAM | 科学について議論するための DFF ベースのスキル |
| DFFショートストーリースキル | 90MBのRAM | [新しい DFF バージョン] では、(1) 寓話や道徳的な物語などの就寝前の物語、(2) ホラー ストーリー、(3) 面白いストーリーの 3 つのカテゴリからユーザーのショート ストーリーを伝えます。 |
| DFFスポーツスキル | 70MBのRAM | スポーツについて議論するための DFF ベースのスキル |
| DFFトラベルスキル | 70MBのRAM | 旅行について話し合うための DFF ベースのスキル |
| DFFウェザースキル | 1.4 GB RAM | [新しい DFF バージョン]は OpenWeatherMap サービスを使用してユーザーの位置の予測を取得します |
| DFF Wiki スキル | 150MBのRAM | エンティティの抽出、スロットの埋め込み、ファクトの挿入、確認応答を含むシナリオの作成に使用されます。 |
| 名前 | 要件 | 説明 |
|---|---|---|
| AI FAQ スキル | 150MBのRAM | [DFF 新バージョン]現代の AI について知りたかったけど、聞くのが怖かったすべてのこと!この FAQ アシスタントは、今日のテクノロジー世界の最も単純なトピックを説明しながらチャットします。 |
| ファッションスタイリストのスキル | 150MBのRAM | [新しい DFF バージョン] da Costa Industries 衣類アシスタントであらゆる季節を守りましょう!天候に関係なく、究極の快適さと保護を体験してください。冬も暖かく過ごせます... |
| ドリームペルソナスキル | 150MBのRAM | [新しい DFF バージョン]指定された生成サービスを利用して、指定されたプロンプトに基づいて応答を生成するプロンプトベースのスキル |
| マーケティングスキル | 150MBのRAM | [DFF 新バージョン] Marketing AI Assistant を使用して、これまでにない方法で視聴者とつながりましょう!共感の力を活用して、新たな成功の高みに到達しましょう。さようなら.. |
| おとぎ話のスキル | 150MBのRAM | [新しい DFF バージョン]このアシスタントは、あなたやあなたの子供たちに、短くても魅力的なおとぎ話を教えてくれます。キャラクターとトピックを選択し、残りは AI の想像力に任せます。 |
| 栄養スキル | 150MBのRAM | [DFF 新バージョン] AI アシスタントで健康的な食事の秘密を発見しましょう!あなたやあなたの愛する人のための栄養価の高い食品のオプションを簡単に見つけてください。食事時のストレスに別れを告げ、おいしいものにこんにちは... |
| ライフコーチングスキル | 150MBのRAM | [新しい DFF バージョン] Rhodes & Co の特許取得済みの AI アシスタントで潜在能力を最大限に引き出します。職場でも家庭でも最高のパフォーマンスを発揮します。楽に最高のパフォーマンスを発揮して、他の人にインスピレーションを与えましょう。 |
クラトフ Y. et al. Alexa 賞 2019 の DREAM 技術レポート //Alexa 賞の議事録。 – 2020年。
Baymurzina D. et al. Alexa 賞の DREAM テクニカル レポート 4 //Alexa 賞の議事録。 – 2021年。
DeepPavlov Dream は Apache 2.0 に基づいてライセンスされています。
Program-y ( dream/skills/dff_program_y_skill 、 dream/skills/dff_program_y_wide_skill 、 dream/skills/dff_program_y_dangerous_skillを参照) は、Apache 2.0 でライセンスされています。 Eliza ( dream/skills/eliza参照) は MIT License に基づいてライセンスされています。
ボット応答を含む証明書xlsxファイルを作成するには、 xlsx_responder.pyスクリプトを実行して使用できます。
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .jsonすべてのサービスがデプロイされていることを確認してください。 --input - 認定の質問が含まれるxlsxファイル、 --output - ボットの応答が含まれるxlsxファイル、 --cache - 詳細なマークアップが含まれ、キャッシュに使用されるjson 。


