Seq2seq Chatbot for Keras
1.0.0
このリポジトリには、seq2seq モデリングに基づくチャットボットの新しい生成モデルが含まれています。このモデルの詳細については、論文「生成的会話エージェントのためのエンドツーエンドの敵対的学習」のセクション 3 を参照してください。このリポジトリのアイデアやコードを使用して出版する場合は、この論文を引用してください。
ここで利用可能なトレーニング済みモデルは、約 8,000 個のコンテキスト (現時点までの対話の最後の 2 つの発話) とそれぞれの応答のペアで構成される小規模なデータセットを使用しました。データはオンラインの英語コースの対話から収集されました。このトレーニング済みモデルは、クローズド ドメイン データセットを使用して現実世界のアプリケーションに合わせて微調整できます。
標準 seq2seq モデルは、入力と出力の発話が異なる言語で書かれているため、入力シーケンスと出力シーケンスに属する単語の事前確率分布が異なるタスクであるニューラル機械翻訳で普及しました。ここで提示されるアーキテクチャは、入力ワードと出力ワードに対して同じ事前分布を前提としています。したがって、新しいモデルの採用により、エンコードとデコードのプロセス間で埋め込み層 (Glove の事前トレーニング済み単語埋め込み) を共有します。コンテキストの感度を向上させるために、思考ベクトル (つまり、エンコーダーの出力) は、現在の時点までの会話の最後の 2 つの発話をエンコードします。回答生成中にコンテキストを忘れることを避けるために、思考ベクトルは、現時点までに生成された不完全な回答をエンコードする密なベクトルに連結されます。結果のベクトルは、答えの現在のトークンを予測する密な層に提供されます。私たちのモデルの利点について詳しくは、論文のセクション 3.1 を参照してください。
このアルゴリズムは、予測されたトークンを不完全な応答に含めて、以下に示すモデルの右側の入力層にフィードバックすることを繰り返します。
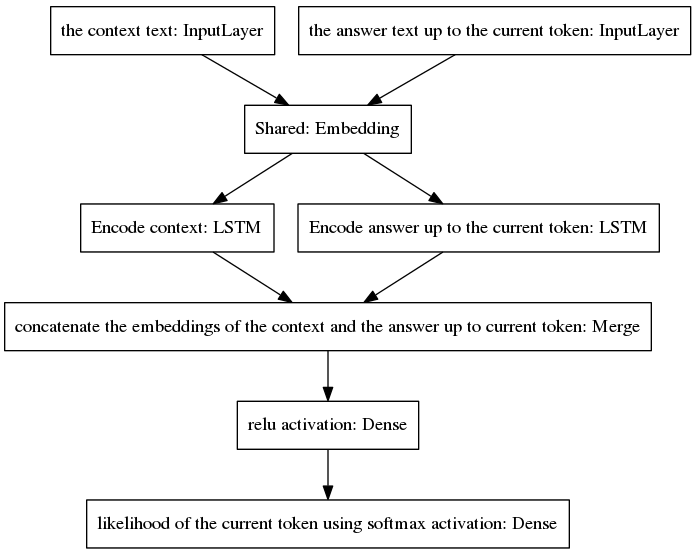
上の図からわかるように、2 つの LSTM は並列に配置されていますが、標準 seq2seq にはエンコーダーとデコーダーの反復層が直列に配置されています。リカレント層は時間の経過とともにバックプロパゲーション中に展開され、その結果、多数の入れ子関数が生成され、その結果、勾配が消失するリスクが高くなります。これは、ゲート アーキテクチャの場合でも、標準 seq2seq モデルのリカレント層のカスケードによって悪化します。 LSTMなど。これが、私のモデルが正規の seq2seq よりもトレーニング中に適切に動作する理由の 1 つであると考えています。
次の疑似コードはアルゴリズムを説明します。

この新しいモデルのトレーニングは、いくつかのエポックで収束します。 8K トレーニング サンプルのデータセットを使用すると、GPU GTX980 で実行すると 139 秒/エポックのコストがかかり、カテゴリカル クロスエントロピー損失 0.0318 に達するのに必要なエポックはわずか 100 エポックでした。このトレーニング済みモデル (このリポジトリで提供されている) のパフォーマンスは、Cornell Movie Dialogs Corpus の約 300,000 個のトレーニング サンプルでトレーニングされたバニラの seq2seq モデルのパフォーマンスと同じくらい説得力があるように見えますが、トレーニングに必要な計算量ははるかに少なくなります。
事前トレーニングされたモデルとチャットするには:
ここから、Python ファイル「conversation.py」、語彙ファイル「vocabulary_movie」、および正味重み「my_model_weights20」をダウンロードします。
会話.pyを実行します。
新しい GAN ベースのトレーニング アルゴリズムによってトレーニングされた新しいモデルとチャットするには:
Python ファイル「conversation_discriminator.py」、語彙ファイル「vocabulary_movie」、正味重み「my_model_weights20.h5」、「my_model_weights.h5」、および「my_model_weights_discriminator.h5」をダウンロードします。これらはここにあります。
会話_discriminator.pyを実行します。
このモデルは、同じトレーニング データを使用するとパフォーマンスが向上します。 GAN ベースのモデルの弁別器は、2 つのモデルの間で最良の答えを選択するために使用されます。1 つは教師強制によってトレーニングされ、もう 1 つは新しい GAN のようなトレーニング方法によってトレーニングされます。その詳細については、この論文で説明します。
新しいモデルをトレーニングするか、独自のデータを微調整するには:
最初からトレーニングする場合は、ファイル my_model_weights20.h5 を削除します。データを微調整するには、このファイルを保存しておいてください。
Glove フォルダー「glove.6B」をダウンロードし、このフォルダーをチャットボットのディレクトリに含めます (このフォルダーはここで見つかります)。このアルゴリズムは、トレーニング中に微調整される事前トレーニング済みの単語埋め込みを使用して転移学習を適用します。
split_qa.py を実行してトレーニング データのコンテンツを 2 つのファイル「context」と「answers」に分割し、get_train_data.py を実行してパディングされた文をファイル「Padded_context」と「Padded_answers」に保存します。
train_bot.py を実行してチャットボットをトレーニングします (GPU の使用をお勧めします。これを行うには、THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py と入力します)。
トレーニング データに「data.txt」という名前を付けます。このファイルには、1 行に 1 つの対話発話が含まれている必要があります。データセットが大きい場合は、変数 num_subsets (train_bot.py の 29 行目) をより大きな数値に設定します。
weights_file = 'my_model_weights20.h5'weights_file_GAN = 'my_model_weights.h5'weights_file_discrim = 'my_model_weights_discriminator.h5'
さまざまなフレームワーク向けのニューラル会話モデルの現在の実装に関する優れた概要 (いくつかの結果とともに) は、ここで見つけることができます。
私たちのモデルは、テキストの要約など、他の NLP タスクに適用できます。たとえば、代替 2: 再帰的モデル A を参照してください。私たちは、他のタスクにも私たちのモデルを適用することをお勧めします。この場合、私たちの成果をできるだけ引用していただくようお願いいたします。 2017 年 7 月に登録されたこの文書に記載されています。
これらのコードは、Ubuntu 14.04.3 LTS、Python 2.7.6、Theano 0.9.0、および Keras 2.0.4 で実行できます。別の構成を使用するには、若干の調整が必要になる場合があります。


