中国語チャットボット/中国語チャットボット
- 著者は完全に移籍しました
GNN グラフのニューラル ネットワークの方向C++ 開発は NLP に準拠しなくなり、プロジェクト コードは保守されなくなります。 Yuanxiang プロジェクトが完了したとき、オンライン リソースはほとんどありませんでした。著者は、思いつきで初めて NLP とディープ ラーニングに触れ、さまざまな困難を乗り越え、最終的にこの Toy Model を書きました。したがって、作者は初心者にとってそれが簡単ではないことを知っているため、たとえプロジェクトが維持されなくなったとしても、問題や電子メール ([email protected]) にはタイムリーに応答して、深層学習の初心者を支援します。 (私が使用している Tensorflow のバージョンは古すぎます。新しいバージョンを直接実行すると、間違いなくさまざまなエラーが発生します。問題が発生した場合は、わざわざ古いバージョンの環境をインストールしないでください。Pytorch を使用することをお勧めします)私の処理ロジックに従ってそれを再構築するには、書くのが面倒です)
- GNN の側面:
- 一連のベンチマーク比較モデル: GNNs-Baseline は、アイデアの迅速な検証を容易にするために適応およびコンパイルされています。
- 私の論文 ACMMM 2023 (CCF-A) のオープンソース コードは、ここ LSTGM にあります。
- 私の論文 ICDM 2023 (CCF-B) のオープンソース コードはまだコンパイル中です。 。 。 GRN
- 仲間の追加、コミュニケーション、学習を歓迎します。
環境構成
| プログラム | バージョン |
|---|
| パイソン | 3.68 |
| テンソルフロー | 1.13.1 |
| ケラス | 2.2.4 |
| ウィンドウズ10 | |
| ジュピター | |
主な参考資料
- 論文「調整と翻訳を共同学習することによるニューラルマシン翻訳(タイトルをクリックしてダウンロード)」
- アテンション構造図
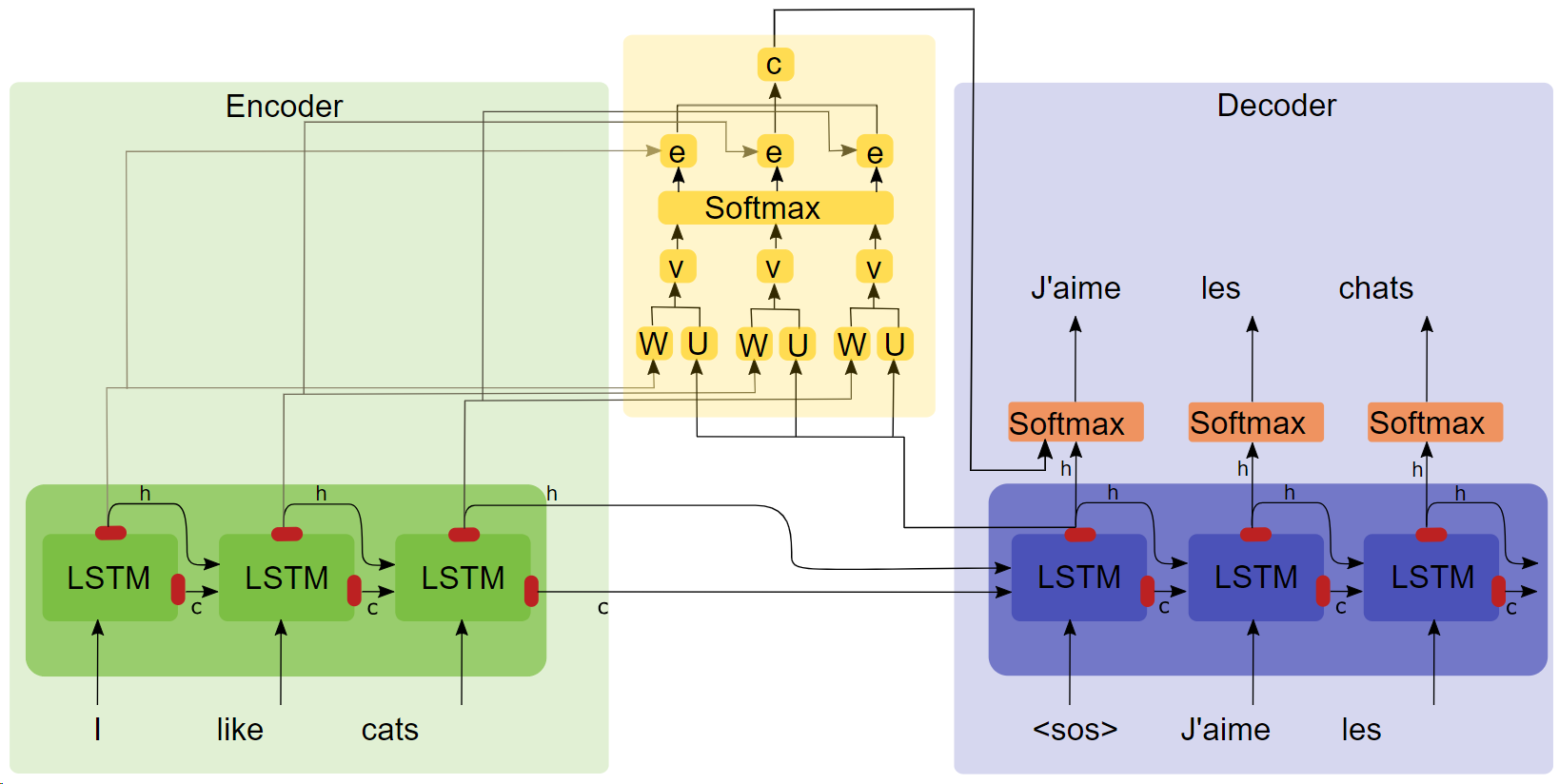
重要なポイント
- LSTM
- シーケンス2シーケンス
- 注意実験では、注意メカニズムを追加した後、トレーニング速度が速くなり、収束が速くなり、効果がより優れていることがわかりました。
コーパスとトレーニング環境
Google 共同研究室で訓練された Qingyun コーパスからの 100,000 の対話グループ。
走る
方法 1: プロセスを完了する
- データの前処理
get_data
- モデルのトレーニング
chatbot_train (これは Google Colab にマウントされたバージョンです。ローカルの実行パスを少し変更する必要があります)
- モデル予測
chatbot_inference_Attention
方法 2: 既存のモデルをロードする
chatbot_inference_Attentionを実行する
models/W--184-0.5949-.h5
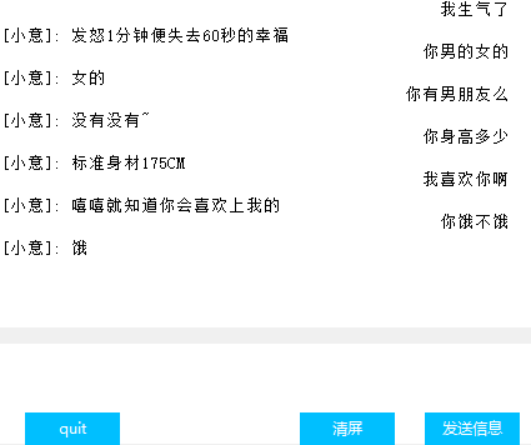
インターフェース(Tkinter)
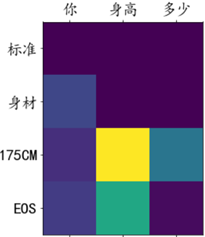
アテンションウェイトの視覚化
他の
- トレーニング ファイル chat_bot では、コードの最後の 3 つのブロックのうち最初の 2 つは Google Cloud Disk をマウントするために使用され、最後のブロックは描画を容易にするためにこれらの損失を取得するために使用されます。なぜコールバック関数に Tensorbord が含まれるのかはわかりません。ではうまくいかないので、この戦略を思いつきました。
- 予測ファイルの最後から 2 番目のコード ブロックにはテキスト入力のみがあり、インターフェイスはありません。2 つのブロックのうちの 1 つは、必要に応じてすぐに実行できます。
- コードには多くの中間出力があります。コードの理解に役立つことを願っています。
- モデルには私がトレーニングしたモデルがあります。通常の動作には問題ありません。自分でトレーニングすることもできます。
- 著者の能力は限られており、対話の効果を定量化する指標を見つけていないため、損失はトレーニングの進捗状況を大まかに反映することしかできません。


