gutenberg dialog
1.0.0
独自のバージョンの Gutenberg Dialog Dataset をダウンロードして構築するためのコード。新しい言語で簡単に拡張可能。 https://ricsinaruto.github.io/chatbot.html で、さまざまな言語でトレーニングされたチャットボットを試してみてください。
| ダウンロードリンク | 発言数 | 平均発話長 | 対話の数 | 会話の平均長さ |
|---|---|---|---|---|
| 英語 | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| ドイツ語 | 226 015 | 24.44 | 43 440 | 5.20 |
| オランダ語 | 129 471 | 24.26 | 23 541 | 5.50 |
| スペイン語 | 58 174 | 18.62 | 6 912 | 8.42 |
| イタリア語 | 41 388 | 19.47 | 6 664 | 6.21 |
| ハンガリー語 | 18 816 | 14.68 | 2 826 | 6.66 |
| ポルトガル語 | 16 228 | 21.40 | 2 233 | 7.27 |
? データセットのサイズと品質のトレードオフに影響を与えるパラメーターを調整して、独自のデータセットを生成します
モジュール式インターフェースにより、データセットを他の言語に簡単に拡張できます
? データセットを構築するときに書籍を手動で簡単に除外できます
setup.py を実行して必要なパッケージをインストールします。
python setup.py
メイン ファイルはリポジトリのルートから呼び出す必要があります。以下のコマンドは、引数として指定されたカンマ区切り言語のデータセット構築パイプラインを実行します。現在、英語、ドイツ語、オランダ語、スペイン語、ポルトガル語、イタリア語、ハンガリー語がサポートされています。
python code/main.py -l=en,de,nl,es,pt,it,hu -a
設定可能なすべての引数を以下に示します。 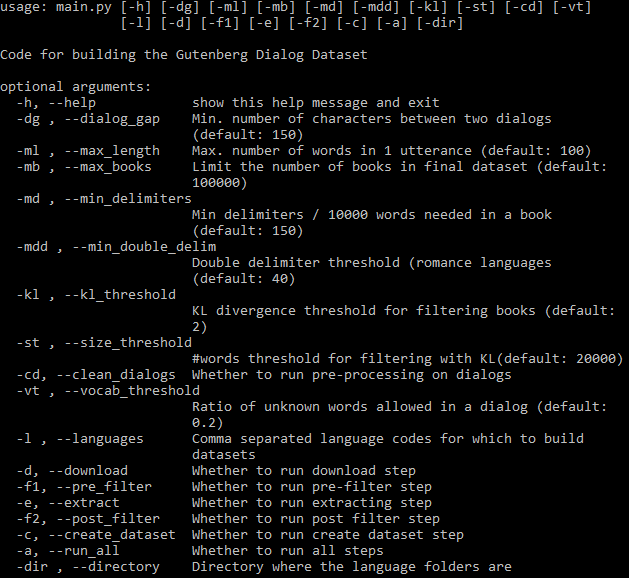
-aフラグは、パイプライン全体を自動的に実行するかどうかを制御します。 -aを省略した場合は、フラグを使用してステップのサブセットを指定する必要があります (上記のヘルプを参照)。ステップが終了すると、その出力は後続のステップで使用でき、そのステップに関連するパラメータまたはコードが変更された場合にのみ再実行されます。すべてのステップは言語ごとに個別に実行されます。
指定された言語の書籍をダウンロードします。
注:すべてのブックが「ブックをダウンロードできませんでした」というエラーでダウンロードに失敗する場合、考えられる原因は、 gutenbergパッケージで使用されるデフォルトのミラーにアクセスできなくなったことです。これが発生した場合は、 GUTENBERG_MIRROR環境変数を介して https://www.gutenberg.org/MIRRORS.ALL にリストされている代替ミラーのいずれかを使用することができます。例えば:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
プレフィルタリングにより、一部の古い書籍とノイズが除去されます。
会話は書籍から抜粋されています。データセットを新しい言語に拡張する場合 (以下のセクションを参照)、これは変更できるステップであるため、完了したら前のステップをスキップできます。
2 番目のフィルタリング ステップでは、語彙に基づいて一部のダイアログを削除します。
最終的なデータセットをまとめて、トレーニング/開発/テスト データに分割します。最後のステップでは、最終的なデータセットの抽出に使用されるすべての書籍 (およびタイトルと著者) を含むauthor_and_title.txtファイルを出力ディレクトリに作成します。ユーザーは、データセット内で許可すべきではない書籍に対応する行を、このファイルからBand_books.txtに手動でコピーできます。以降のステップの実行では、このファイル内の書籍は考慮されません。
コードは他の言語を処理するように簡単に拡張できます。 <言語コード>.py という名前のファイルを言語フォルダーに作成する必要があります。ここでは、LANG またはその他のサブクラスを親として、大文字の言語コード (英語の場合はEn ) という名前のクラスを定義する必要があります。 self.cfg を使用すると、設定パラメータにアクセスできます。このクラス内では、以下の 3 つの関数を定義する必要があります。例については it.py を参照してください。
言語統計
この関数は、キーが区切り文字となる可能性のある辞書を返す必要があります。区切り文字ごとに、入力として行を受け取り、数値を返す関数 (辞書内の値) を定義する必要があります。この数値は、たとえば、区切り文字の数、行に区切り文字があるかどうかのフラグなどです。通常、さまざまな区切り文字の重要性に応じて、重み付けされた数を使用することをお勧めします。値は、それぞれのブックで使用する区切り文字 (以下の関数に渡される) を決定するため、および区切り文字の量が少ないブックをフィルタリングするために使用されます。 en.py には、複数の区切り文字の例が含まれています。
この関数は、書籍からダイアログを抽出し、ダイアログのリストであるself.dialogsに追加する必要があります。各ダイアログは連続した発話のリストです。段落リストには、連続する段落のリストとして書籍が含まれます。 delimiter は、このファイル内でダイアログを抽出するために使用する最も一般的な区切り文字です。
この関数は、後処理ダイアログ (特定の文字の削除など) に使用されます。入力として発話を受け取ります。 nltk 単語のトークン化は自動的に実行されることに注意してください。
このプロジェクトは MIT ライセンスに基づいてライセンスされています。詳細については、LICENSE ファイルを参照してください。
作品でデータセットまたはコードを使用し、次の論文の引用を検討する場合は、このリポジトリへのリンクを含めてください。
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


