Dialog
1.0.0
Dialogは日本語チャットボットプロジェクトです。
このプロジェクトで使用されるアーキテクチャは、BERT Encoder と Transformer Decoder を備えた EncoderDecoder モデルです。
日本語で書かれた記事。
環境を構築することなく、Google Colab上でトレーニングや評価スクリプトを実行できます。
次のリンクをクリックしてください。
トレーニングノートでは、ダウンロードコマンドがノートの最後に記載されていますが、まだテストされていないことに注意してください。したがって、トレーニング ノートブックを実行しても、トレーニングされたウェイト ファイルをダウンロードできない場合は、手動でダウンロードしてください。
日本語で書かれたブログ
@ycat3 は、このプロジェクトを文生成に、Parallel Wavenet を音声合成に使用して、テキスト読み上げのサンプルを作成しました。ソース コードは共有されませんが、Parallel Wavenet を利用すれば再現できます。そのブログに音声サンプルがいくつかありますので、ぜひ聞いてみてください。
時間があれば音声合成や音声認識を使ってAIと音声で会話できるアプリを作りたいと思っていますが、今は試験の準備でできません…。
2エポック
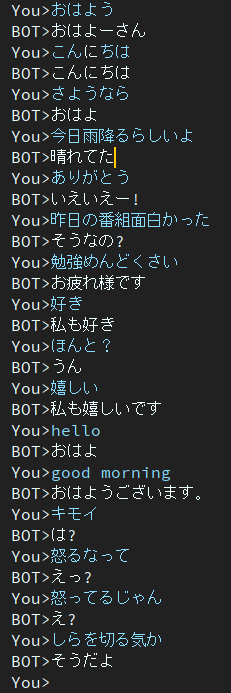
このモデルは依然としてレスポンスの鈍さの問題を抱えています。
この問題を解決するために、現在研究中です。
その後、この問題に取り組んでいる論文を見つけました。
ニューラル対話生成のための別の多様性促進目的関数
著者は奈良先端科学技術大学院大学(通称:NAIST)に所属しています。
彼らはニューラル対話生成の新しい目的関数を提案しています。
この方法がその問題の解決に役立つことを願っています。
Googleドライブで。
必要なパッケージは、
パッケージが原因でエラーが発生する場合は、不足しているパッケージをインストールしてください。
conda を使用する場合の例。
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'トレーニングを開始する準備ができたら、メイン スクリプトを実行します。
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pyさらに会話データを取得したい場合は、get_tweet.py を使用してください。
このスクリプトを使用するには、consumer_key と access_token を変更する必要があることに注意してください。
そして、以下のコマンドを実行します。
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Example コマンドを実行すると、最後の文に「私は」が含まれている場合、スクリプトは連続する 5 つの文の収集を開始します。
ただし、「連続発話」を 3 つ以上設定すると、make_training_data.py が自動的に発話のペアを作成します。
次に、次のコマンドを実行します。
$ python make_training_data.pyこのスクリプトは名前の通り「./data/tweet_data_*.txt」を使って学習データを作成します。
エンコーダー: BERT
デコーダー: バニラトランスフォーマーのデコーダー
損失: クロスエントロピー
オプティマイザー: AdamW
トークナイザー: BertJapaneseTokenizer
BERT または Transformer のアーキテクチャについて詳しく知りたい場合は、次の記事を参照してください。


