Multi Modality Arena
1.0.0
Multi-Modality Arena は、大規模なマルチモダリティ モデル用の評価プラットフォームです。 Fastchat に続いて、視覚的な質問応答タスクで 2 つの匿名モデルを並べて比較します。私たちはデモをリリースし、この評価イニシアチブへの皆様の参加を歓迎します。
OmniMedVQA データセット: 127,995 の QA 項目を含む 118,010 枚の画像が含まれており、12 の異なるモダリティをカバーし、20 以上の人体解剖学的領域を参照しています。データセットはここからダウンロードできます。
12 モデル: 8 つの一般領域 LVLM と 4 つの医療特化 LVLM。
小さなデータセット: 各データセットに対してランダムに選択された 50 個のサンプルのみ、つまり、使いやすさを考慮して 42 個のテキスト関連のビジュアル ベンチマークと合計 2.1K のサンプル。
追加モデル: さらに 4 モデル、つまりGoogle Bardを含む合計 12 モデル。
ChatGPT アンサンブル評価: 以前の単語一致アプローチよりも人間による評価との一致が向上しました。
LVLM-eHub は、公開されている大規模マルチモーダル モデル (LVLM) の包括的な評価ベンチマークです。 幅広く評価してくれる
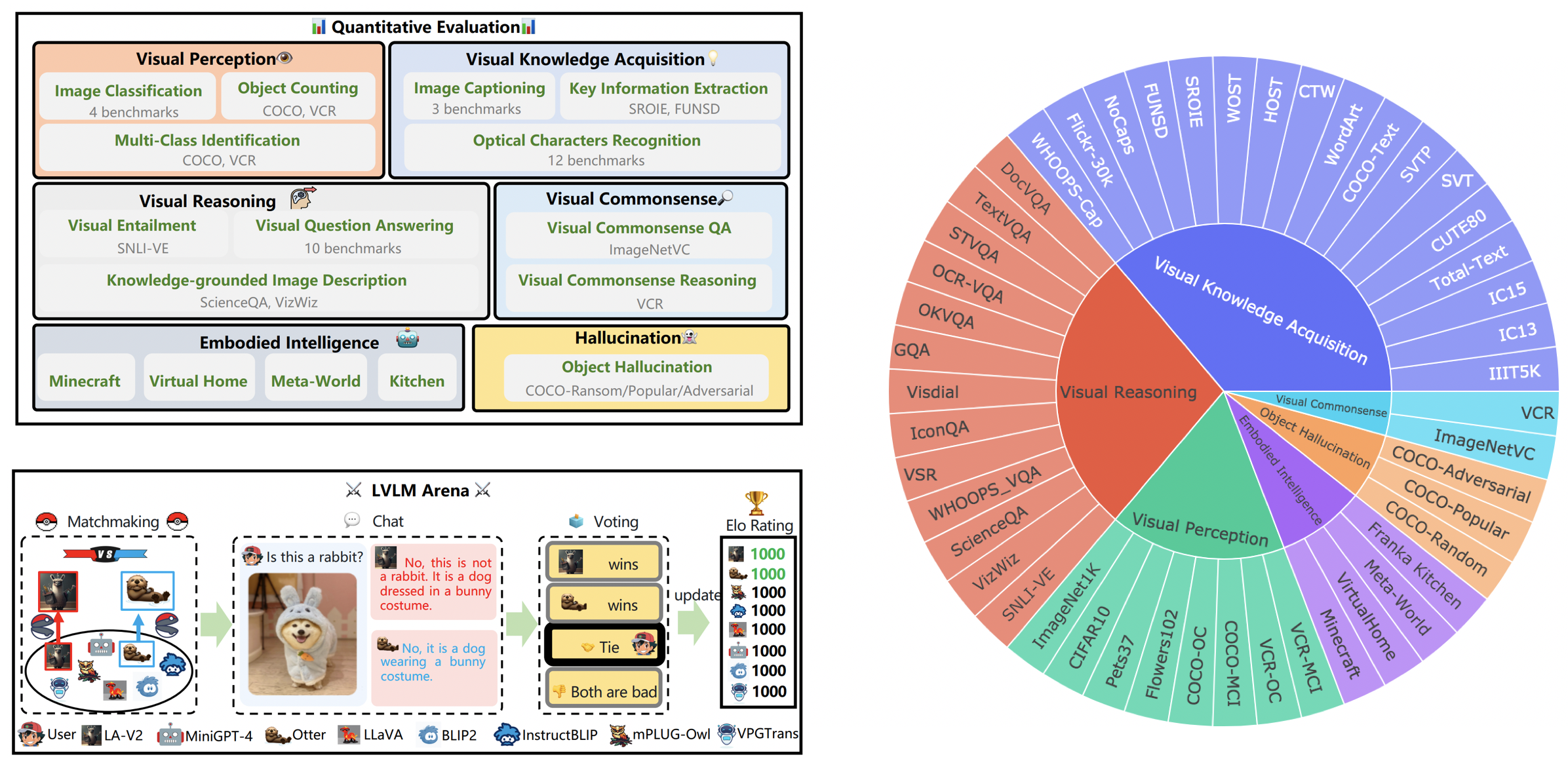
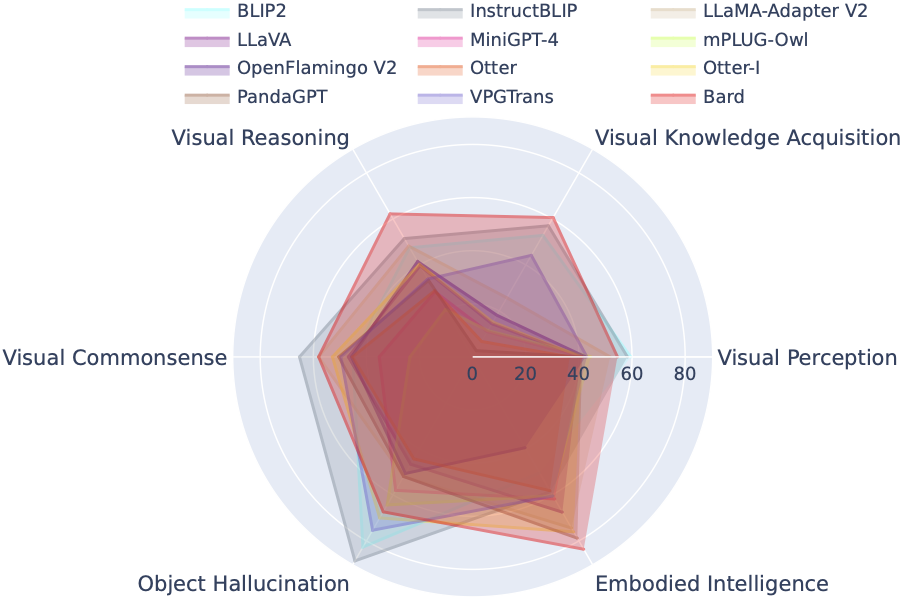
LVLM リーダーボードは、Tiny LVLM 評価で取り上げられたデータセットを、視覚認知、視覚的推論、視覚的常識、視覚的知識の獲得、物体の幻覚などの特定の対象能力に従って体系的に分類しています。このリーダーボードには、その包括性を強化するために最近リリースされたモデルが含まれています。
ここからベンチマークをダウンロードできます。詳細については、こちらをご覧ください。
| ランク | モデル | バージョン | スコア |
|---|---|---|---|
| 1 | インターンVL | インターンVLチャット | 327.61 |
| 2 | InternLM-XComposer-VL | InternLM-XComposer-VL-7B | 322.51 |
| 3 | 吟遊詩人 | 吟遊詩人 | 319.59 |
| 4 | Qwen-VL-チャット | Qwen-VL-チャット | 316.81 |
| 5 | LLaVA-1.5 | ビクーニャ-7B | 307.17 |
| 6 | ブリップを指示する | ビクーニャ-7B | 300.64 |
| 7 | インターンLM-X作曲家 | InternLM-XComposer-7B | 288.89 |
| 8 | ブリップ2 | フランT5xl | 284.72 |
| 9 | ブリバ | ビクーニャ-7B | 284.17 |
| 10 | オオヤマネコ | ビクーニャ-7B | 279.24 |
| 11 | チーター | ビクーニャ-7B | 258.91 |
| 12 | LLaMA アダプター v2 | LLaMA-7B | 229.16 |
| 13 | VPGトランス | ビクーニャ-7B | 218.91 |
| 14 | カワウソの画像 | Otter-9B-LA-InContext | 216.43 |
| 15 | ビジュアルGLM-6B | ビジュアルGLM-6B | 211.98 |
| 16 | mPLUG-フクロウ | LLaMA-7B | 209.40 |
| 17 | LLaVA | ビクーニャ-7B | 200.93 |
| 18 | MiniGPT-4 | ビクーニャ-7B | 192.62 |
| 19 | カワウソ | オッター-9B | 180.87 |
| 20 | OFv2_4BI | RedPajama-INCITE-命令-3B-v1 | 176.37 |
| 21 | パンダGPT | ビクーニャ-7B | 174.25 |
| 22 | ラヴィン | LLaMA-7B | 97.51 |
| 23 | 総務省 | フランT5xl | 94.09 |
2024 年 3 月 31 日。医療用 LVLM の大規模総合評価ベンチマークである OmniMedVQA をリリースします。一方、私たちは一般領域の LVLM が 8 つ、医療専門の LVLM が 4 つあります。詳細については、MedicalEval をご覧ください。
2023 年 10 月 16 日。LVLM-eHub から派生した能力レベルのデータセット分割を示し、最近リリースされた 8 つのモデルを含めることで補完します。データセット分割、評価コード、モデル推論結果、包括的なパフォーマンス テーブルにアクセスするには、tiny_lvlm_evaluation ✅ にアクセスしてください。
2023.08.08 [Tiny LVLM-eHub]をリリースしました。評価ソースコードとモデル推論結果は tiny_lvlm_evaluation でオープンソース化されています。
2023 年 6 月 15 日 大規模ビジョン言語モデルの評価ベンチマーク[LVLM-eHub]をリリースしました。コードは近日公開予定です。
2023 年 6 月 8 日。VPGTrans の著者である Dr. Zhang の修正に感謝します。 VPGTrans の著者は主に NUS と清華大学の出身です。以前、VPGTrans を再実装するときにいくつかの小さな問題がありましたが、実際にはパフォーマンスが向上していることがわかりました。さらに多くのモデル作成者については、電子メールで議論するために私に連絡してください。また、より正確な結果が得られるモデル ランキング リストに従ってください。
5月。 22、2023。mPLUG-Owl の作者、Ye 博士の訂正に感謝します。 mPLIG-Owl の実装におけるいくつかの小さな問題を修正しました。
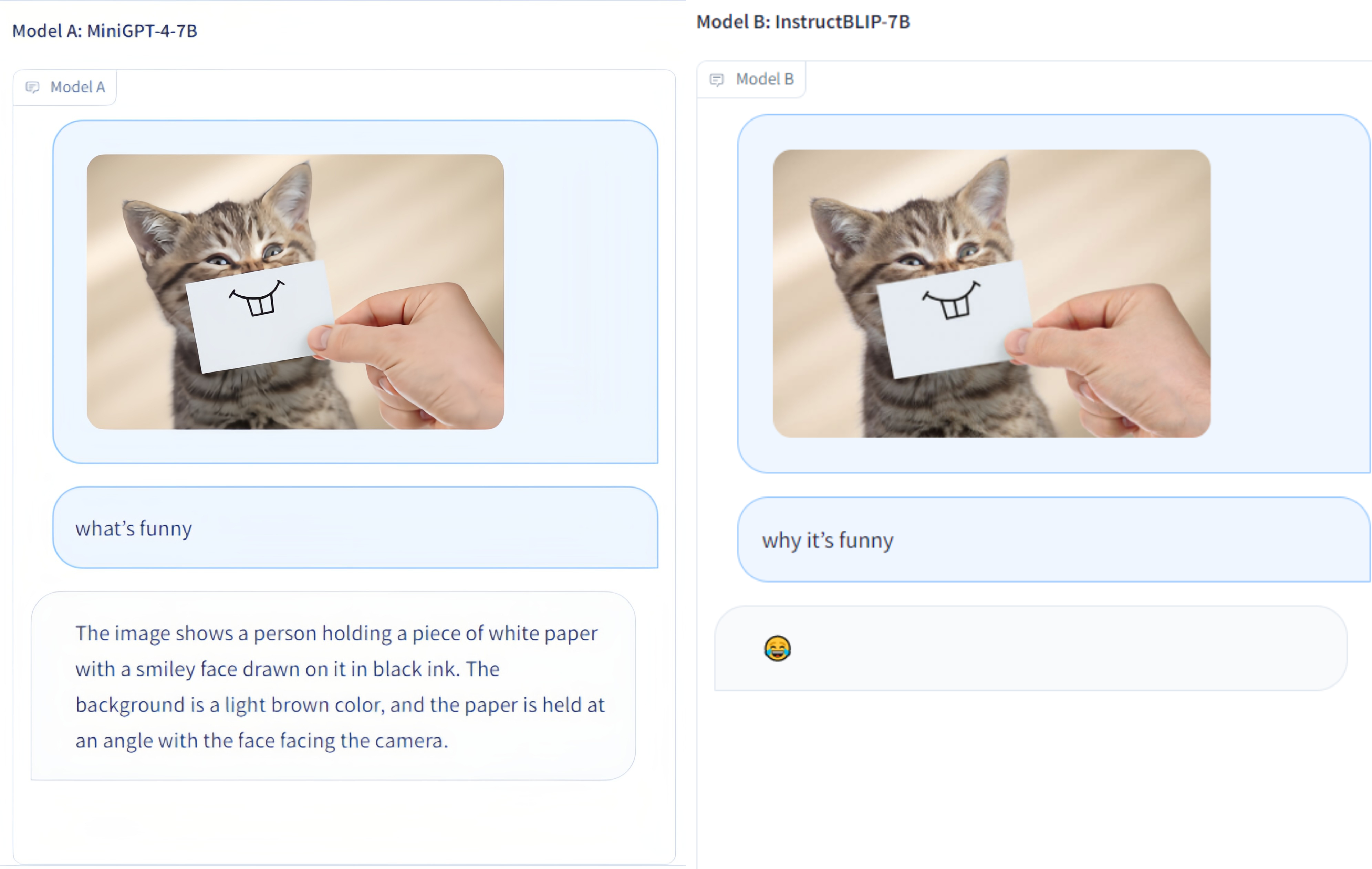
現在、以下のモデルがランダムバトルに参加しています。
KAUST/ミニGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
DAMOアカデミー/mPLUG-Owl
NTU/カワウソ
ウィスコンシン大学マディソン校/LLaVA
上海 AI ラボ/llama_adapter_v2
NUS/VPGトランス
これらのモデルの詳細については、 ./model_detail/.model.jpgを参照してください。私たちは、アリーナでより多くのマルチモダリティ モデルをホストできるようにコンピューティング リソースをスケジュールする予定です。
VLarena プラットフォームの一部にご興味がございましたら、お気軽に Wechat グループにご参加ください。

conda環境を作成する
conda create -n arena python=3.10 conda アクティブアリーナ
コントローラーとサーバーの実行に必要なパッケージをインストールします
pip インストール numpy gradio uvicorn fastapi
次に、モデルごとに、競合するバージョンの Python パッケージが必要になる場合があるため、GitHub リポジトリに基づいてモデルごとに特定の環境を作成することをお勧めします。
Web UI を使用してサービスを提供するには、ユーザーとインターフェースをとる Web サーバー、2 つ以上のモデルをホストするモデル ワーカー、Web サーバーとモデル ワーカーを調整するコントローラーの 3 つの主要コンポーネントが必要です。
ターミナルで実行するコマンドは次のとおりです。
Pythonコントローラー.py
このコントローラーは分散ワーカーを管理します。
python model_worker.py --モデル名 SELECTED_MODEL --device TARGET_DEVICE
プロセスがモデルのロードを完了し、「Uvicorn running on ...」が表示されるまで待ちます。モデル ワーカーは自身をコントローラーに登録します。モデル ワーカーごとに、使用するモデルとデバイスを指定する必要があります。
Pythonサーバー_デモ.py
これは、ユーザーが対話するユーザー インターフェイスです。
これらの手順に従うことで、Web UI を使用してモデルを提供できるようになります。今すぐブラウザを開いてモデルとチャットできます。モデルが表示されない場合は、gradio Web サーバーを再起動してみてください。
私たちは、評価の質を高めることを目的としたすべての貢献を深く評価しています。このセクションは、 Contributions to LVLM EvaluationとContributions to LVLM Arenaという 2 つの主要なセグメントで構成されています。
LVLM_evaluation フォルダー内の評価コードの最新バージョンにアクセスできます。このディレクトリには、必要なデータセットを伴う包括的な評価コードのセットが含まれています。評価プロセスに参加することに熱心な場合は、[email protected] まで電子メールで評価結果またはモデル推論 API を遠慮なく共有してください。
モデルを LVLM アリーナに統合することに関心をお持ちいただき、ありがとうございます。モデルをアリーナに組み込みたい場合は、次のような構造のモデル テスターをご用意ください。
class ModelTester:def __init__(self, device=None) -> なし:# TODO: モデルの初期化と必要なプリプロセッサdef move_to_device(self, device) -> なし:# TODO: この関数は、CPU と CPU の間でモデルを転送するために使用されます。 GPU (オプション)defgenerate(self, image, question) -> str: # TODO: モデル推論コード
さらに、Gradio などのプラットフォームによって提供されるオンライン モデル推論リンクも受け入れます。皆様のご貢献に心より感謝申し上げます。
私たちは、ChatBot Arena の尊敬すべきチームと、LVLM 評価の取り組みのインスピレーションとなった影響力のある仕事に対して、彼らの論文 Judging LLM-as-a-judge に感謝の意を表します。また、大規模なビジョン言語モデルの進歩と進歩に多大な貢献をしてくださった LVLM のプロバイダーにも心からの感謝の意を表したいと思います。最後に、LVLM-eHub で使用したデータセットのプロバイダーに感謝します。
このプロジェクトは、非営利目的のみを目的とした実験的研究ツールです。安全対策が限られており、不適切なコンテンツが生成される可能性があります。違法、有害、暴力的、人種差別的、または性的な目的で使用することはできません。


