clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
ハイエンド GPU、さらにはプロシューマおよびコンシューマ GPU を複数のユーザー間で共有することは、AI 開発を加速する最もコスト効率の高い方法です。残念ながら、これまでのところ、MIG/スライシング ハイエンド GPU (A100+) に適用され、Kubernetes が必要な唯一の既存のソリューションでした。
? Nvidia カード用のコンテナ ベースのフラクショナル GPU へようこそ! ?
事前に構築されたハード メモリ制限付きの CUDA 11.x および CUDA 12.x をサポートする、事前にパッケージ化されたコンテナーを紹介します。つまり、複数のコンテナを同じ GPU 上で起動できるため、1 人のユーザーがホスト GPU メモリ全体を割り当てることができなくなります。 (GPU メモリ全体を取得する貪欲なプロセスはもう必要ありません! 最後に、ドライバー レベルでメモリをハード制限するオプションが追加されました)。
ClearML は、GPU を分割することで GPU リソースの使用率を最適化するためのいくつかのオプションを提供します。
これらのオプションを使用すると、ClearML は、最適化されたハードウェア使用率とワークロード パフォーマンスで AI ワークロードを実行できるようになります。このリポジトリは、コンテナベースのフラクショナル GPU をカバーします。 ClearML のフラクショナル GPU サービスの詳細については、ClearML のドキュメントを参照してください。
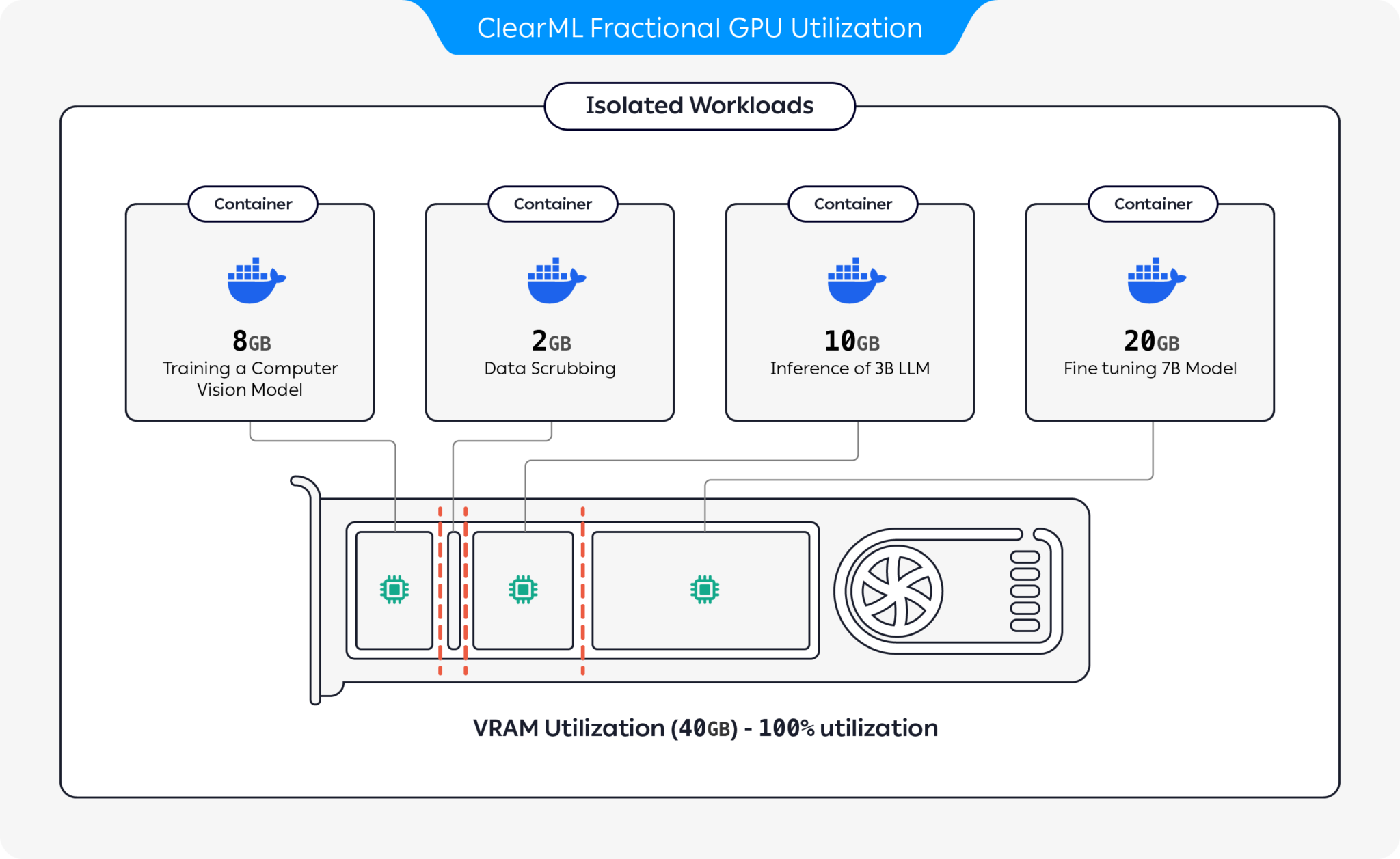
自分に合ったコンテナを選択して起動します。
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bash部分 GPU メモリ制限が正しく機能していることを確認するには、コンテナー内で次のコマンドを実行します。
nvidia-smiA100 GPU からの出力例を次に示します。
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| メモリ制限 | CUDA版 | Ubuntu版 | ドッカーイメージ |
|---|---|---|---|
| 12 GiB | 12.3 | 4月22日 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 GiB | 12.3 | 4月20日 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 GiB | 11.7 | 4月22日 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 GiB | 11.1 | 4月20日 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 GiB | 12.3 | 4月22日 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 GiB | 12.3 | 4月20日 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 GiB | 11.7 | 4月22日 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 GiB | 11.1 | 4月20日 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 GiB | 12.3 | 4月22日 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 GiB | 12.3 | 4月20日 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 GiB | 11.7 | 4月22日 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 GiB | 11.1 | 4月20日 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 GiB | 12.3 | 4月22日 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 GiB | 12.3 | 4月20日 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 GiB | 11.7 | 4月22日 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 GiB | 11.1 | 4月20日 | clearml/fractional-gpu:u20-cu11.1-2gb |
重要
--pid=host使用してコンテナを実行する必要があります。
注記
--pid=hostメモリ/使用率の使用を制限するときにドライバーがコンテナのプロセスと他のホスト プロセスを区別できるようにするために必要です
ヒント
ClearML-Agent ユーザーは、構成ファイルのagent.extra_docker_argumentsセクションに[--pid=host]を追加します。
独自のコンテナを構築し、元のコンテナから継承します。
ここでいくつかの例を見つけることができます。
フラクショナル GPU コンテナーは、ベアメタル実行および Kubernetes POD で使用できます。はい! Fractional GPU コンテナの 1 つを使用すると、ジョブ/ポッドのメモリ消費を制限し、互いのメモリ クラッシュを心配することなく GPU を簡単に共有できます。
シンプルな Kubernetes POD テンプレートを次に示します。
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] 重要
ポッドはhostPID: trueで実行する必要があります。
注記
hostPID: trueが必要です
コンテナーは、Nvidia ドライバー <= 545.xxをサポートします。新しいドライバーがリリースされ続けるたびに更新とサポートを続けます
サポートされている GPU : RTX シリーズ 10、20、30、40、A シリーズ、および Data-Center P100、A100、A10/A40、L40/s、H100
制限事項: Windows ホスト マシンは現在サポートされていません。これが重要な場合は、「問題」セクションにリクエストを残してください。
Q : コンテナ内でnvidia-smi実行すると、ローカル プロセスの GPU 消費量が報告されますか?
A : はい、 nvidia-smi低レベル ドライバーと直接通信し、正確なコンテナー GPU メモリとコンテナーのローカル メモリ制限の両方を報告します。
GPU 使用率は、特定のローカル コンテナー GPU 使用率ではなく、グローバル (つまりホスト側) GPU 使用率になることに注意してください。
Q : Python / Pytorch / Tensorflow が実際にメモリ制限されていることを確認するにはどうすればよいですか?
A : PyTorch の場合は、以下を実行できます。
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )番号の例:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Q : ユーザーが制限を破ることはできますか?
A : 悪意のあるユーザーは必ず方法を見つけるでしょう。悪意のあるユーザーから保護することは私たちの意図ではありませんでした。
悪意のあるユーザーがマシンにアクセスしている場合、フラクショナル GPU が最大の問題ではありませんか?
Q : メモリ制限をプログラムで検出するにはどうすればよいですか?
A : OS 環境変数GPU_MEM_LIMIT_GBを確認できます。
これを変更しても、制限が解除または軽減されるわけではないことに注意してください。
Q : --pid=hostを使用してコンテナを実行することは安全ですか?
A : 安全かつ安全でなければなりません。セキュリティの観点からの主な注意点は、コンテナ プロセスはホスト システム上で実行されているコマンド ラインを認識できるということです。プロセスのコマンドラインに「シークレット」が含まれている場合、データ漏洩の可能性があります。コマンド ラインで「シークレット」を渡すのは賢明ではないため、セキュリティ リスクとは考えていないことに注意してください。ただし、セキュリティが重要な場合は、エンタープライズ エディション (以下を参照) を使用するとpid-hostで実行する必要がなくなり、完全に安全になります。
Q : --pid=hostなしでコンテナを実行できますか?
A : できますよ!ただし、clearml-fractional-gpu コンテナーのエンタープライズ バージョンを使用する必要があります (そうしないと、メモリ制限がコンテナー全体ではなくシステム全体に適用されます)。この機能が重要な場合は、ClearML のセールス & サポートにお問い合わせください。
ClearML を使用するライセンスは、研究または開発の目的でのみ付与されます。 ClearML は、教育用、個人用、または社内の商用目的で使用できます。
製品またはサービス内で使用するための拡張商用ライセンスは、ClearML Scale または Enterprise ソリューションの一部として利用できます。
ClearML は、フラクショナル GPU に多くの追加機能を追加するエンタープライズおよび商用ライセンスを提供します。これには、オーケストレーション、優先キュー、クォータ管理、コンピューティング クラスター ダッシュボード、データセット管理と実験管理、エンタープライズ グレードのセキュリティとサポートが含まれます。 ClearML オーケストレーションの詳細については、こちらをご覧ください。または、ClearML 営業担当者に直接お問い合わせください。
みんなにも教えてね! #ClearMLFractionalGPU
Slack チャンネルに参加してください
動作しない場合はお知らせください。問題ページでデバッグにご協力ください。
この製品は、ClearML チームによって提供されています ❤️


