amazon bedrock rag
1.0.0
検索拡張生成 (RAG) は、大規模な言語モデルの出力を最適化するプロセスであるため、応答を生成する前に、トレーニング データ ソースの外部にある信頼できる知識ベースを参照します。大規模言語モデル (LLM) は、膨大な量のデータでトレーニングされ、数十億のパラメーターを使用して、質問への回答、言語の翻訳、文章の完成などのタスク用の元の出力を生成します。 RAG は、モデルを再トレーニングすることなく、LLM のすでに強力な機能を特定のドメインまたは組織の内部ナレッジ ベースに拡張します。これは、LLM 出力を改善するための費用対効果の高いアプローチであり、さまざまな状況において関連性、正確性、有用性を維持します。 RAG について詳しくは、こちらをご覧ください。
Amazon Bedrock は、単一の API を介して、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの大手 AI 企業の高性能基盤モデル (FM) の選択肢を提供するフルマネージド サービスです。セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築するために必要な機能。 Amazon Bedrock を使用すると、ユースケースに合わせてトップ FM を簡単に実験して評価したり、微調整や RAG などの技術を使用してデータでプライベートにカスタマイズしたり、エンタープライズ システムやデータ ソースを使用してタスクを実行するエージェントを構築したりできます。 Amazon Bedrock はサーバーレスであるため、インフラストラクチャを管理する必要がなく、使い慣れた AWS サービスを使用して生成 AI 機能をアプリケーションに安全に統合してデプロイできます。
Amazon Bedrock のナレッジベースは、データ ソースへのカスタム統合を構築したりデータ フローを管理したりすることなく、取り込みから取得、プロンプト拡張に至る RAG ワークフロー全体の実装に役立つフルマネージド機能です。セッション コンテキスト管理が組み込まれているため、アプリは複数ターンの会話を簡単にサポートできます。
ナレッジ ベースの作成の一環として、選択したデータ ソースとベクター ストアを構成します。データ ソース コネクタを使用すると、独自のデータをナレッジ ベースに接続できます。データ ソース コネクタを構成したら、ナレッジ ベースとデータを同期または最新の状態に保ち、データをクエリできるようにすることができます。 Amazon Bedrock は、効率的なデータ取得のために、まずドキュメントまたはコンテンツを管理可能なチャンクに分割します。次に、チャンクは埋め込みに変換され、元のドキュメントへのマッピングを維持しながら、ベクトル インデックス (データのベクトル表現) に書き込まれます。ベクトル埋め込みにより、テキストの類似性を数学的に比較できます。
このプロジェクトは 2 つのデータ ソースを使用して実装されています。 1 つは Amazon S3 に保存されているドキュメントのデータ ソース、もう 1 つは Web サイトで公開されているコンテンツのデータ ソースです。ベクトル検索コレクションは、ベクトルストレージ用に Amazon OpenSearch Serverless に作成されます。
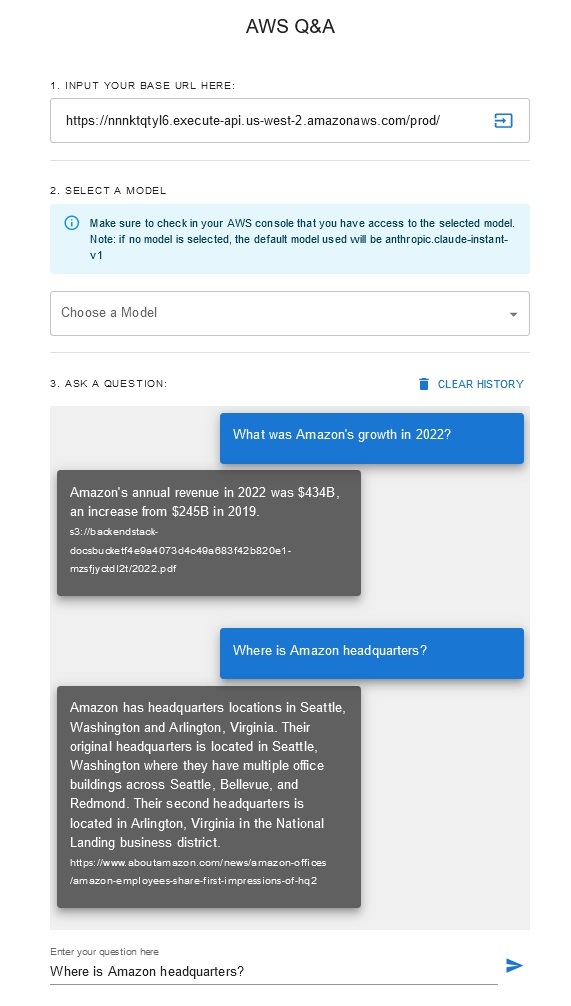
Q&Aチャットボット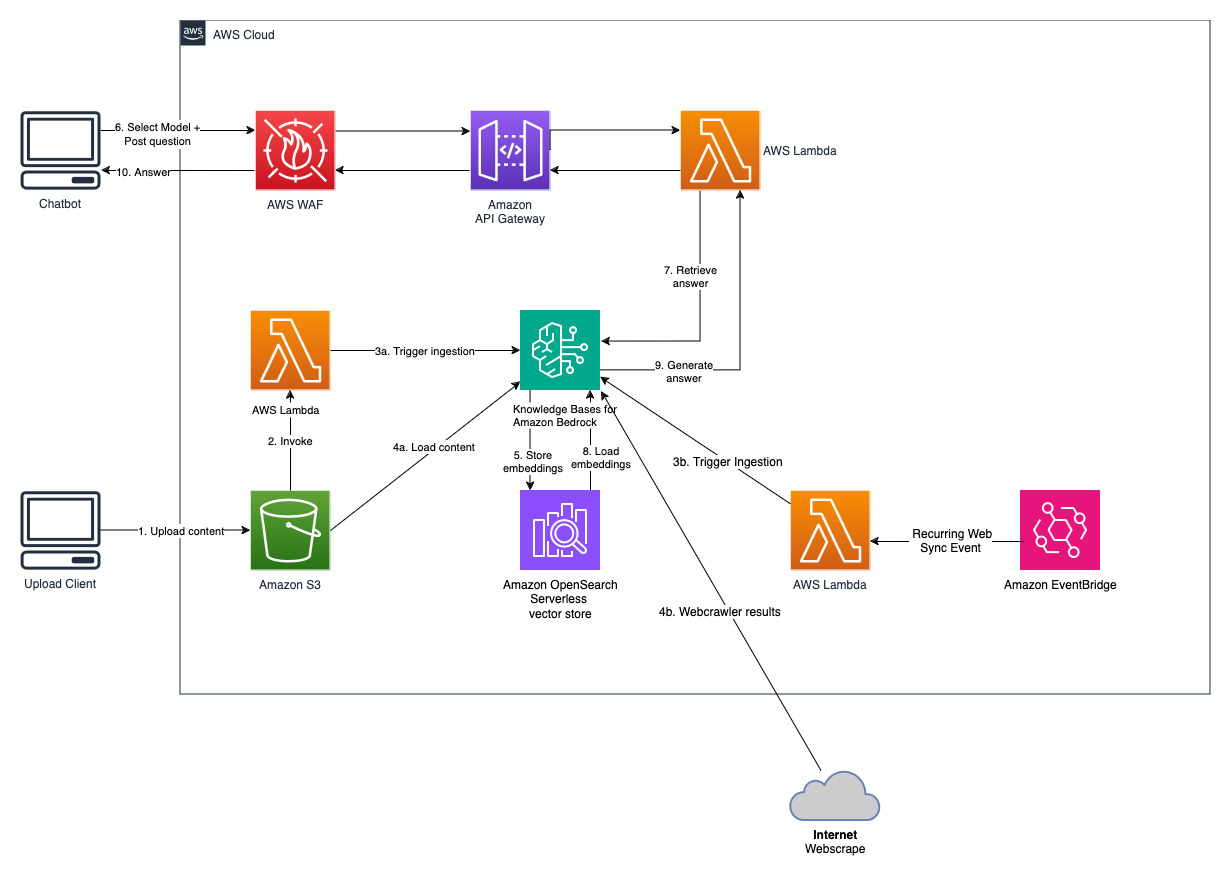
Web データソース用の新しい Web サイトを追加する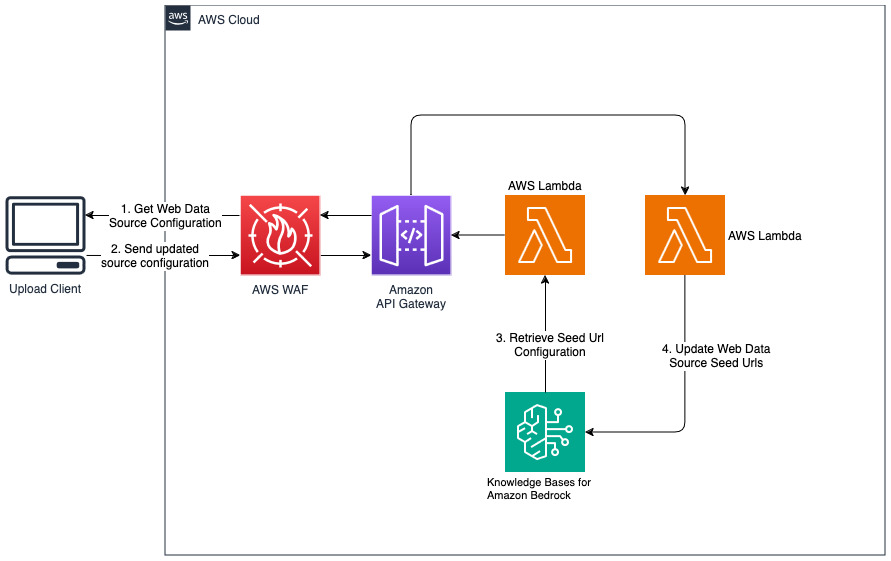
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
API ゲートウェイへのアクセスが許可されるクライアント IP アドレスを、「allowedip」コンテキスト変数の一部として CIDR 形式で指定します。
導入が完了すると、
このソリューションにより、ユーザーは取得および生成フェーズ中に使用する基本モデルを選択できます。デフォルトのモデルはAnthropic Claude Instantです。ナレッジベース埋め込みモデルの場合、このソリューションはAmazon Titan Embeddings G1 - テキストモデルを使用します。これらの基礎モデルにアクセスできることを確認してください。
最近公開されている Amazon の年次レポートを入手し、それを前にメモした S3 バケット名にコピーします。簡単なテストとして、AWS S3 コンソールを使用して Amazon の 2022 年年次報告書をコピーできます。ソリューションのデプロイメントでは S3 バケット内の新しいコンテンツを監視し、取り込みワークフローをトリガーするため、S3 バケットのコンテンツはナレッジベースと自動的に同期されます。
デプロイされたソリューションは、URL https://www.aboutamazon.com/news/amazon-officesを使用して「WebCrawlerDataSource」という Web データ ソースを初期化します。ウェブサイトの取り込みは今後行われる予定であるため、ウェブサイトのコンテンツを検索するには、このウェブ クローラー データ ソースを AWS コンソールのナレッジベースと手動で同期する必要があります。 Amazon Bedrock コンソールに基づくナレッジからこのデータ ソースを選択し、「同期」操作を開始します。詳細については、「データソースと Amazon Bedrock ナレッジベースを同期する」を参照してください。 Web サイトのコンテンツは、同期が完了した後にのみ Q&A チャットボットで利用できるようになることに注意してください。 Web サイトをデータソースとして設定する場合は、このガイダンスを使用してください。
「cdk destroy」を使用して、このソリューションのデプロイメントで作成されたクラウド リソースのスタックを削除します。


