inverted_index
1.0.0
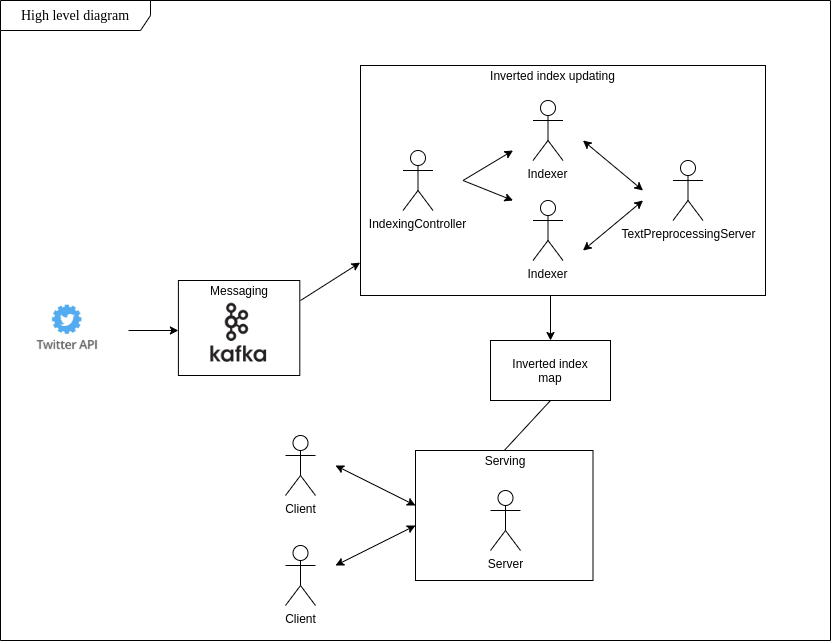
周りの人が言ったフレーズを検索するのは難しいかもしれません。このデータセットの動的更新はどうなるでしょうか?スケーラブルなストレージと低遅延?このプロジェクトの私の主な目標は、これらの要件を満たし、ツイートに存在するトレンドをリアルタイムで把握できるシステムを構築することです。
転置インデックスのアイデアに従って、特定のコンテンツを含むツイートをリアルタイムで検索し、ローカル ファイル システムに保存し、クライアント接続の初期化直後に単語ベースの検索を実行できるようにするアプリを実装しました。
アプリを実行するには次のものが必要です。
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' クライアントとサーバーの Dockerfile を作成します。
./gradlew clean build createClientDockerfile createMainDockerfile
これにより、ルート ディレクトリに app_server.Dockerfile と app_client.Dockerfile が生成されます。
アプリケーションを開始します:
docker-compose up
クライアントセッションを起動します。
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
興味のある単語の入力を開始します。サーバーはツイートの場所を「dataset_v2//tweet_N.txt」形式で返します。例えば:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
提案された機能 (および既知の問題) のリストについては、未解決の問題を参照してください。
MIT ライセンスに基づいて配布されます。詳細については、 LICENSEを参照してください。


