PubData
1.0.0

PubData世界中のすべてのバイオインフォマティクス データベース用の検索エンジンおよびファイル検索システムです。 PubData PubMed が生物医学文献を検索する方法と同様のユーザーフレンドリーな方法で生物医学 FTP データを検索します。 PubDataは Web アプリケーションとスタンドアロンのグラフィカル ユーザー インターフェイス (GUI) ソフトウェア プログラムの両方としてホストされ、PubMed はオンライン Web サーバーとしてホストされます。 PubDataは、新しいネットワーク プログラミングと自然言語処理アルゴリズムに基づいて構築されており、ユーザーが指定したバイオインフォマティクス データベースの FTP サーバーにパッチを適用し、その内容をクエリし、ダウンロードするファイルを取得できます。
PubData 、Python プログラミング言語 (具体的には、Django と PyQt4) で書かれています。 PubData 、ローカル コンピュータ ネットワークを介して、主要なバイオインフォマティクス データベースの深くネストされたディレクトリ ツリーからファイルをリモートで検索、アクセス、表示、取得できます。 PubDataでは、すべての主要なバイオインフォマティクス データベースを 1 つのソフトウェア プログラムの下にまとめることにより、ユーザーはインターネット ブラウザを使用してデータベースに 1 つずつアクセスすることに特有の不必要な手間や標準化されていない複雑さを回避できます。さらに重要なことは、ユーザーが複数のデータベースにユーザー指定のキーワード (例: human 、 cancer 、 transcriptome ) を同時にクエリできることです。そのため、 PubData使用すると、研究者は主要なバイオインフォマティクス データベースの FTP サーバーのファイルを 1 か所から直接検索、アクセス、表示、ダウンロードできます。 PubData使用すると、GUI または Web アプリケーションのみを使用して、ユーザーが快適なローカル コンピューターから直接複数のバイオインフォマティクス FTP サーバーを同時にサーフィンできるようになります。
PubDataからインスピレーションを得たメソッドを使用するソース内では、「Khomtchouk et al.: 'PubData: search Engine for bioinformatics Databases Abroad', 2016: http://dx.doi.org/10.1101/069575」を引用してください。
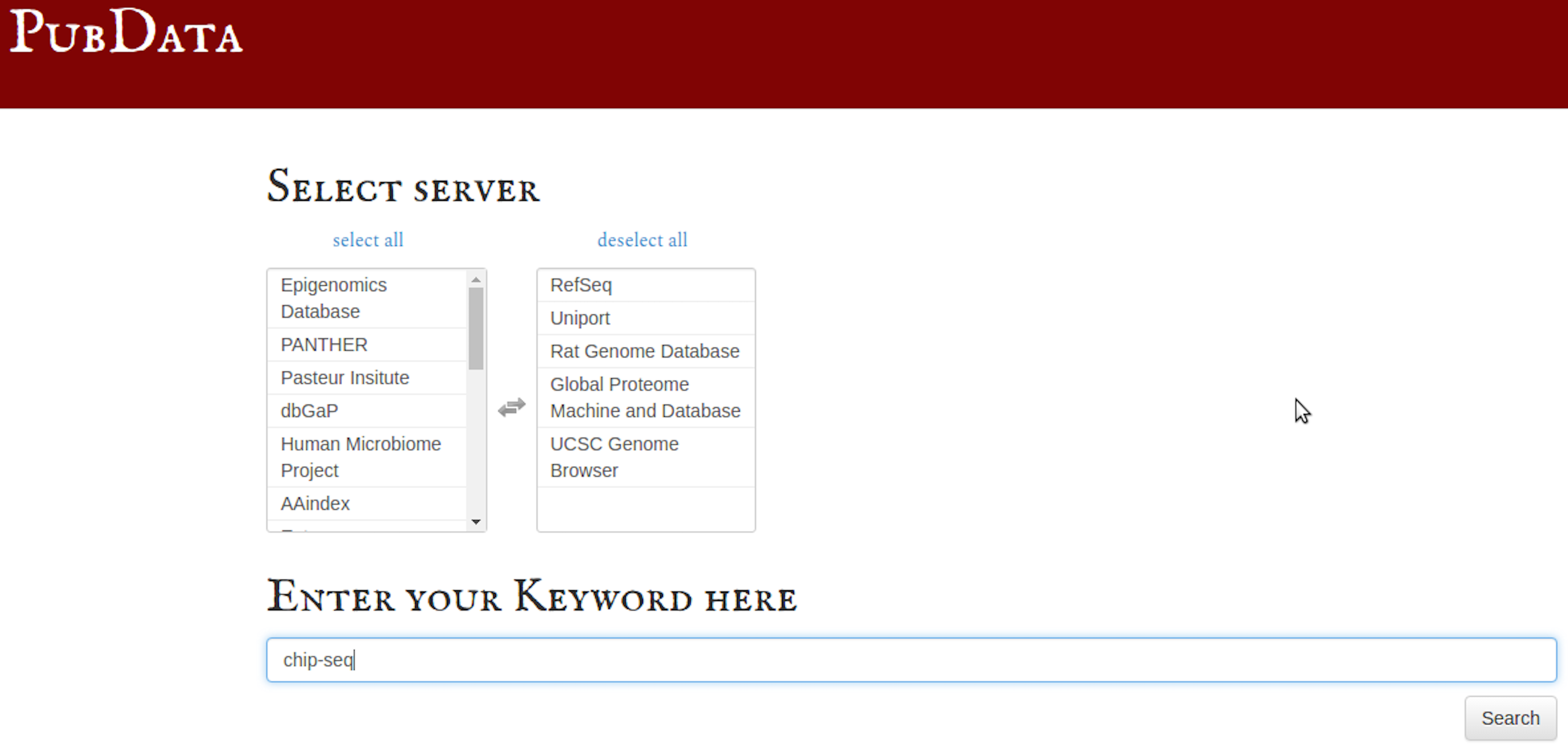
PubDataディレクトリをクローンします。PubDataを開いたら、まずログインするバイオインフォマティクス データベースを選択します。
PANTHER (進化的関係によるタンパク質分析) 分類システム データベースにログインしました:
お気に入りのデータベースがリストにない場合は、自分で手動で挿入できます (最近公開されたデータベースの場合に便利です)。
複数のデータベースを同時に「Google 検索」したいとします。
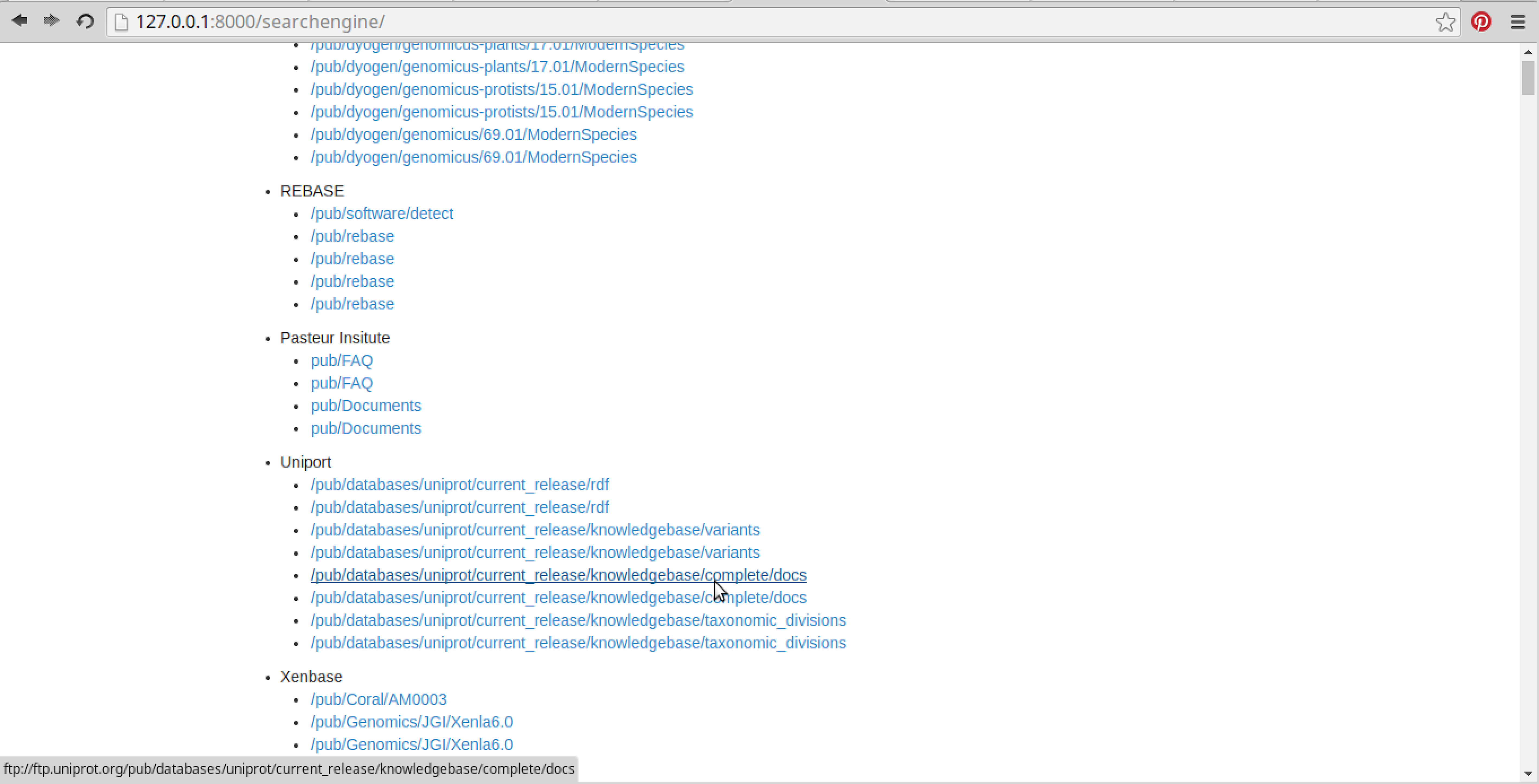
これらの選択したデータベース全体で ChIP-seq ファイルをキーワード検索します (複数のキーワードも使用できます)。
選択したすべてのデータベースにわたる ChIP-seq ファイルに関連するすべての検索結果を表示します。
これらの選択したデータベース全体で RNA-seq ファイルをキーワード検索します (複数のキーワードも使用できます)。
(選択したデータベースからの) RNA-seq ファイルに関連するすべての検索結果を表示します。


