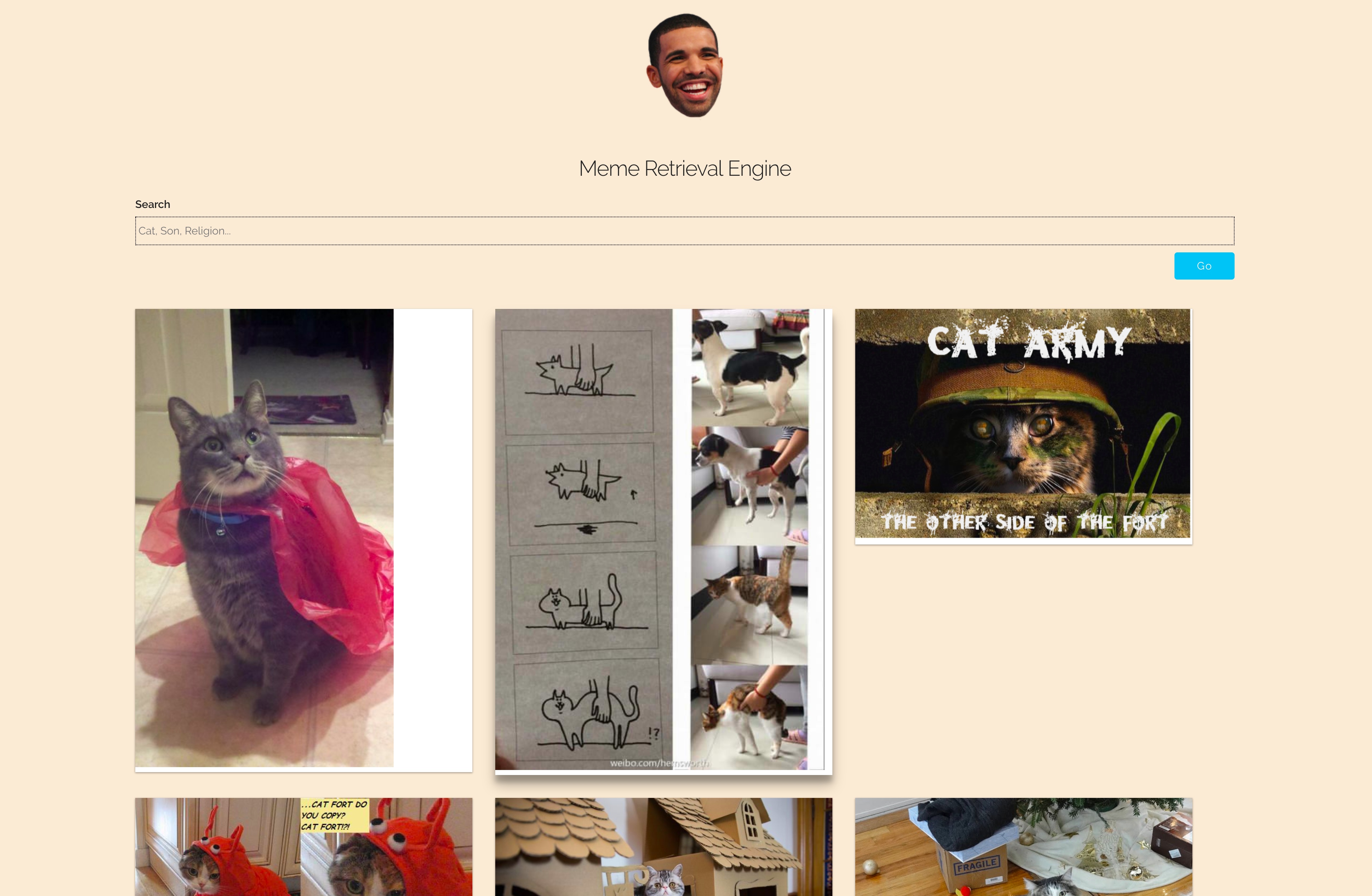
ミーム検索エンジン
プロジェクトの説明
採用技術
コレクション
ミームは、スクレイパー スクリプトscrape/scraper.pyを使用して人気のサブレディットから収集されます。
標準化
- 収集されたミームは
rawフォルダーに置かれ、スクリプトstandard.pyが実行されます。 - 各ファイル名が抽出され、画像用に生成された新しい 16 進数ベースのファイル名の隣のテキスト ファイルに保存されます。
- 規格化された画像は
processedフォルダーに保存されます
クエリの抽出
- 入力されたクエリは単語に分割され、nltk ライブラリを使用して各単語の同義語が
related queriesのリストに追加されます。 - データベースをスキャンして、単語を
related queries内の単語と照合します。 - これにより検索範囲が広がり、出力ゼロのシナリオが最小限に抑えられます。
クエリとの関連性
- ミームは検索クエリとの関連性の順に並べられます。
- これは、データベース内に存在する各ミームにスコアを割り当て、スコアの降順に並べ替えることによって行われます。
光学式文字認識
- OCR はTesseractを使用して行われ、プロジェクトの重要な部分であるミームからテキストを抽出します。
- 抽出されたテキストは完全に正確ではないため、ocr からの出力が Python
autocorrectライブラリのスペルチェッカーに入力されます。 - スペルチェッカーにより変換がより正確になります
クイックテスト
GUI を実行して機能をテストするには、次のように入力します。
集めて実行する
- bash スクリプトは、Meme Engine が適切に機能できるようにするデータベースを準備します。
- ミーム検索エンジン (ミーム ファインダー) を実行するには、次のように入力します。
- テキストフィールドにクエリを入力し、
Goをクリックします。 - ミームは関連性に基づいて並べ替えられます
- 選択したミームは、
Next 」ボタンとPreviousボタンを使用して参照できます。
新しいサブレディットをリストに追加する
要件
- cv2 (OpenCV)
- ピテセラクト
- NLTK
- ピル
- ハッシュリブ
- シャティル
- オートコレクト
- ピモンゴ
今後の改善点
- プログレスバーに機能を追加する
- キャンバス上に表示するミームのサイズ スケーリングを修正します。
- 保存されたミームをフラッシュする機能の追加
- 人気のミームテンプレートを保存し、画像の類似性をチェックし、特別なキーワードを関連付けます
ドキュメント
MemeFinder ドキュメント


