idt
1.0.0

画像データセット ツール (IDT) は、ディープ ラーニングに使用する画像データセットを簡単かつ迅速に作成できるようにするために開発された CLI アプリです。このツールは、duckgo、bing、deviantart などのいくつかの検索エンジンから画像をスクレイピングすることでこれを実現します。 IDT は画像データセットも最適化します。この機能はオプションですが、ユーザーは画像をダウンスケールして圧縮して、最適なファイル サイズと寸法にすることができます。 idt を使用して作成されたサンプル データセットには、合計 23.688 個の画像ファイルが含まれており、その重さはわずか 559.2 メガバイトです。
最新バージョンを発表できることを誇りに思います。 ??
何が変わったのか
pip 経由でインストールするか、このリポジトリのクローンを作成してインストールできます。
user@admin:~ $ pip3 install idt
または
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
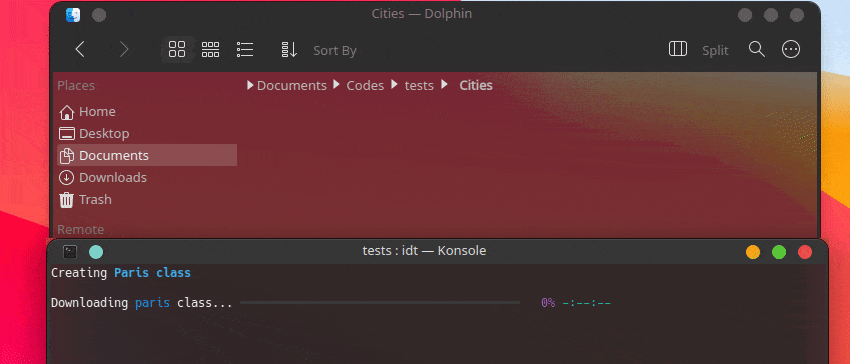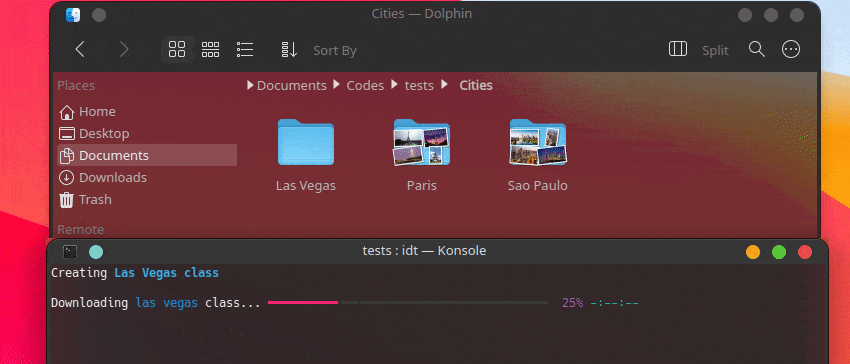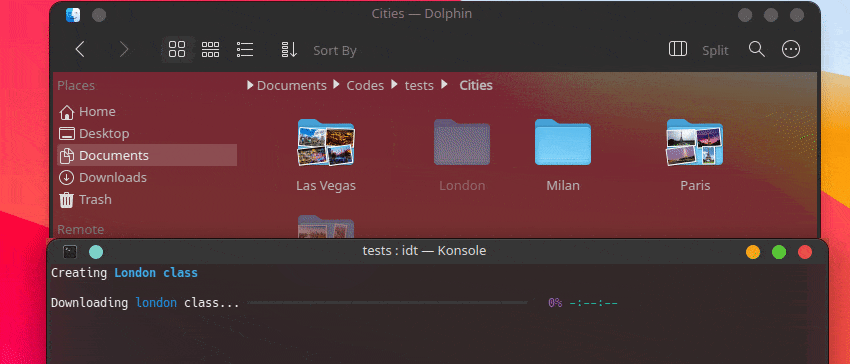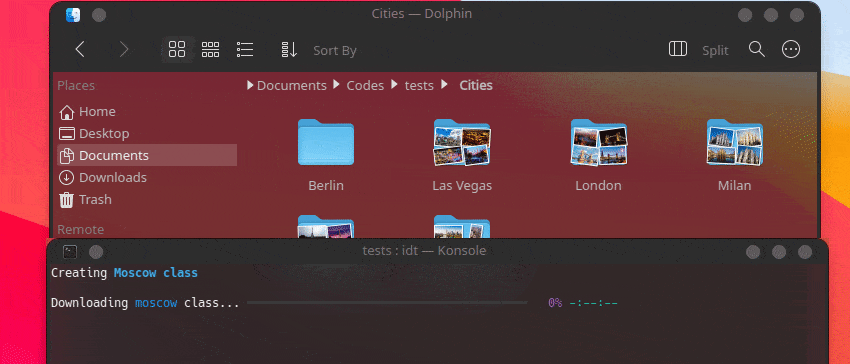
IDT を使い始める最も簡単な方法は、単純な「run」コマンドを実行することです。お気に入りのコンソールに次のように書き込むだけです。
user@admin:~ $ idt run -i apples これにより、50 枚のリンゴの画像がすぐにダウンロードされます。デフォルトでは、これを行うために、duckgo 検索エンジンが使用されます。 run コマンドは次のオプションを受け入れます。
| オプション | 説明 |
|---|---|
| -iまたは--input | キーワードを入力して目的の画像を検索します。 |
| -sまたは--size | ダウンロードする画像の量。 |
| -eまたは--engine | 希望の検索エンジン (オプション: duckgo、bing、bing_api、flickr_api) |
| --サイズ変更メソッド | 画像のサイズ変更方法を選択します。 (オプション:long_side、short_side、smartcrop) |
| -isまたは--image-size | 希望の画像サイズ比率を設定するオプション。デフォルト=512 |
| -akまたは--api-key | API キーを必要とする検索エンジンを使用している場合、このオプションは必須です |
IDT には、データセットをどのように編成するかを指示する構成ファイルが必要です。次のコマンドを使用して作成できます。
user@admin:~ $ idt initこのコマンドは構成ファイル作成者をトリガーし、必要なデータセット パラメーターを要求します。この例では、お気に入りの車の画像を含むデータセットを作成してみましょう。このコマンドで尋ねられる最初のパラメーターは、データセットにどのような名前を付ける必要があるかということです。この例では、データセットに「私のお気に入りの車」という名前を付けます。
Insert a name for your dataset: : My favorite cars次に、ツールは、データセットをマウントするために検索ごとにいくつのサンプルが必要か尋ねます。深層学習用に適切なデータセットを構築するには、多くの画像が必要です。また、検索エンジンを使用して画像を収集しているため、適切なサイズのデータセットをマウントするには、さまざまなキーワードを使用して多数の検索を行う必要があります。この値は、検索ごとにダウンロードする画像の数に対応します。この例では、各クラスに 250 個の画像を含むデータセットが必要で、5 つのキーワードを使用して各クラスをマウントします。したがって、ここに数字 50 を入力すると、IDT は指定されたすべてのキーワードの画像を 50 枚ダウンロードします。 5 つのキーワードを指定すると、必要な 250 枚の画像が取得されるはずです。
How many samples per search will be necessary? : 50ツールは画像サイズの比率を尋ねます。ニューラル ネットワークのトレーニングに大きな画像を使用することは現実的ではないため、オプションで次の画像サイズ比率のいずれかを選択し、画像をそのサイズに縮小することができます。この例では 512x512 を使用しますが、このタスクには 256x256 の方がさらに適しています。
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1そして、サイズ変更方法として「longer_side」を選択します。
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
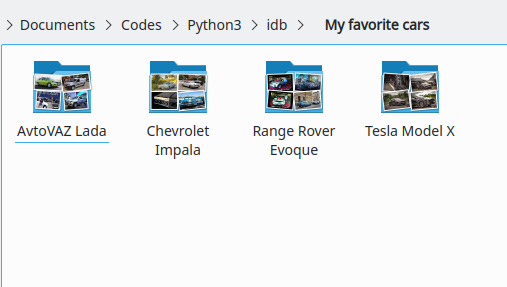
次に、データセットに含めるクラス/フォルダーの数を選択する必要があります。この例では、この部分は非常に個人的なものになる可能性がありますが、私の好きな車は、シボレー インパラ、レンジローバー イヴォーク、テスラ モデル X、そして(なぜそうではないのか)アフトヴァズ ラダです。したがって、この場合、お気に入りごとに 1 つずつ、計 4 つのクラスがあります。
How many image classes are required? : 4その後、利用可能な検索エンジンのいずれかを選択するよう求められます。この例では、DuckGO を使用して画像を検索します。
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1次に、フォームへの入力を繰り返し行う必要があります。各クラスと、画像の検索に使用されるすべてのキーワードに名前を付ける必要があります。この部分は後で独自のコードで変更して、さらに多くのクラスとキーワードを生成できることに注意してください。
Class 1 name: : Chevrolet Impala最初のクラス名を入力すると、データセットを見つけるためのすべてのキーワードを入力するように求められます。各キーワードの 50 枚の画像をダウンロードするようにプログラムに指示したことを思い出してください。この場合、250 枚の画像すべてを取得するには、5 つのキーワードを指定する必要があります。各キーワードはカンマ(,)で区切る必要があります。
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
次に、必要な 4 つのクラスをすべて入力するまで、クラス名とそのキーワードを入力するプロセスを繰り返します。
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!データセット構成ファイルが作成されました。次のコマンドを錆び付けて、魔法が起こるのを確認してください。
user@admin:~ $ idt buildデータセットがマウントされるまで待ちます。
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
最後に、すべての画像がデータセット名のフォルダーで利用できるようになります。また、データセットの統計情報を含む csv ファイルもデータセットのルート フォルダーに含まれています。
深層学習ではデータセットをトレーニング/検証フォルダーのサブセットに分割する必要があることが多いため、このプロジェクトではこれも行うことができます。ただ実行してください:
user@admin:~ $ idt split次に、トレーニング/有効な比率を選択する必要があります。この例では、画像の 70% がトレーニング用に予約され、残りが検証用に予約されることを選択しました。
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yそれで終わりです!データセット分割は、対応する train/valid サブディレクトリで見つかるはずです。
このプロジェクトは暇なときに開発していますが、バグをなくすにはまだ多くの努力が必要です。プル リクエストと貢献者は本当に感謝しています。できる限りの方法で自由に貢献してください。


