Sound Content Music Recommendation System
1.0.0

あなたも私と同じなら、音楽が大好きです。私は音楽が大好きで、新しい音楽を見つけるのが大好きです。 Spotify は、インターネット上の音楽のトップ ストリーミング サービスの 1 つであり、聞いている内容に基づいて新しい音楽を発見するのに役立つ素晴らしいツールがすでに組み込まれています。これは、ユーザー間の同様の使用状況が追跡され、曲にリンクされている情報間の類似情報に基づいて新しい曲を推奨する推奨またはコンテンツベースの推奨を生成するために使用される協調フィルタリングなど、さまざまなアルゴリズムの組み合わせを通じて行われます。歌みたいな? Spotify では、その曲の「ラジオ」を聴くことができます。ラジオでは、その曲に何らかの方法または組み合わせで類似した曲のグループが収集されます。曲が好きだけど、その曲に含まれているサウンド以外の情報は気にしない場合はどうすればよいでしょうか?時々、私が聞きたいのはそれだけです。
私は音楽の音の情報だけを基にして音楽推薦システムを作るためにこのプロジェクトを作成しました。これは、ユーザーが似たサウンドの曲を通じて新しい音楽を見つけるのに役立ちます。そのために、すべての音楽の類似点も調査し、曲の音色、リズム、スタイルを数学的に捉えようとします。
音は常に私たちの周りにあります。私たちは生涯を通して、他人の音の異なる音を聞き分けられるようになります。音楽も同様です。音楽にはさまざまな種類があり、音楽は多くの場合、他のものと区別できるさまざまな種類の音やリズムの組み合わせです。しかし、その情報を自分自身で定量化できるでしょうか?場合によっては、音楽がジャンルに分類されることがあります。これは、ジャンルが、スタイル、形式、リズム、音色、楽器、文化などの類似した性質を持つミュージシャンのグループであることを意味します。しかし、すべての音楽アーティストが同じジャンルのサウンドを作成するわけではありませんし、すべてのジャンルに同じ種類の音楽が含まれるわけでもありません。では、音とは何でしょうか?また、さまざまな種類の音をどのように識別するのでしょうか?
音は音波の振動であり、音波が鼓膜を振動させるときに耳を通して知覚されます。音波は信号であり、その信号が振動する速度は周波数として知られています。音の周波数が高い場合、私たちはその音のピッチが高く感じます。音楽では、ベースやバスドラムなどの楽器は低い周波数で振動するサウンドを生成しますが、高いピッチはより高い周波数を持ちます。シンバルやハイハットの衝突音は、さまざまな周波数の多くの波の組み合わせであり、「ノイジーな」ほぼランダムに見える波で表されます。
音はどのように見えますか?サウンドを視覚化する 1 つの方法は、時間の経過に沿って信号をプロットすることです。
各サブプロットの時間枠を短縮すると、オーディオ信号をより近くで確認できるようになります。信号を最も拡大した画像では、波がさまざまな周波数の集合であることに注目してください。より小さな高周波信号と結合する 1 つの低周波信号が存在する場合があります。
したがって、時間の経過に伴う信号を視覚化することができますが、この視覚化を見るだけでその音波について多くを理解するのは難しいことがすでにわかります。その 0.01 秒のウィンドウにはどのような種類の周波数が存在しますか?それに答えるために、フーリエ変換を使用してスペクトログラムを計算します。
フーリエ変換は、オーディオ信号のセクションに存在する周波数の振幅を計算する方法です。上のグラフからわかるように、波は複雑になる可能性があり、信号の各変化は異なる周波数 (振動の速度) を表します。フーリエ変換は基本的に、時間の各セクションの周波数を抽出し、周波数振幅対時間の 2 次元配列を生成します。フーリエ変換の積はスペクトログラムです。スペクトログラムから、生成された周波数をメル スケールに変換して、メル スペクトログラムを作成します。メル スペクトログラムは、私たちが聞いたときに知覚される周波数間の距離をより適切に表します。
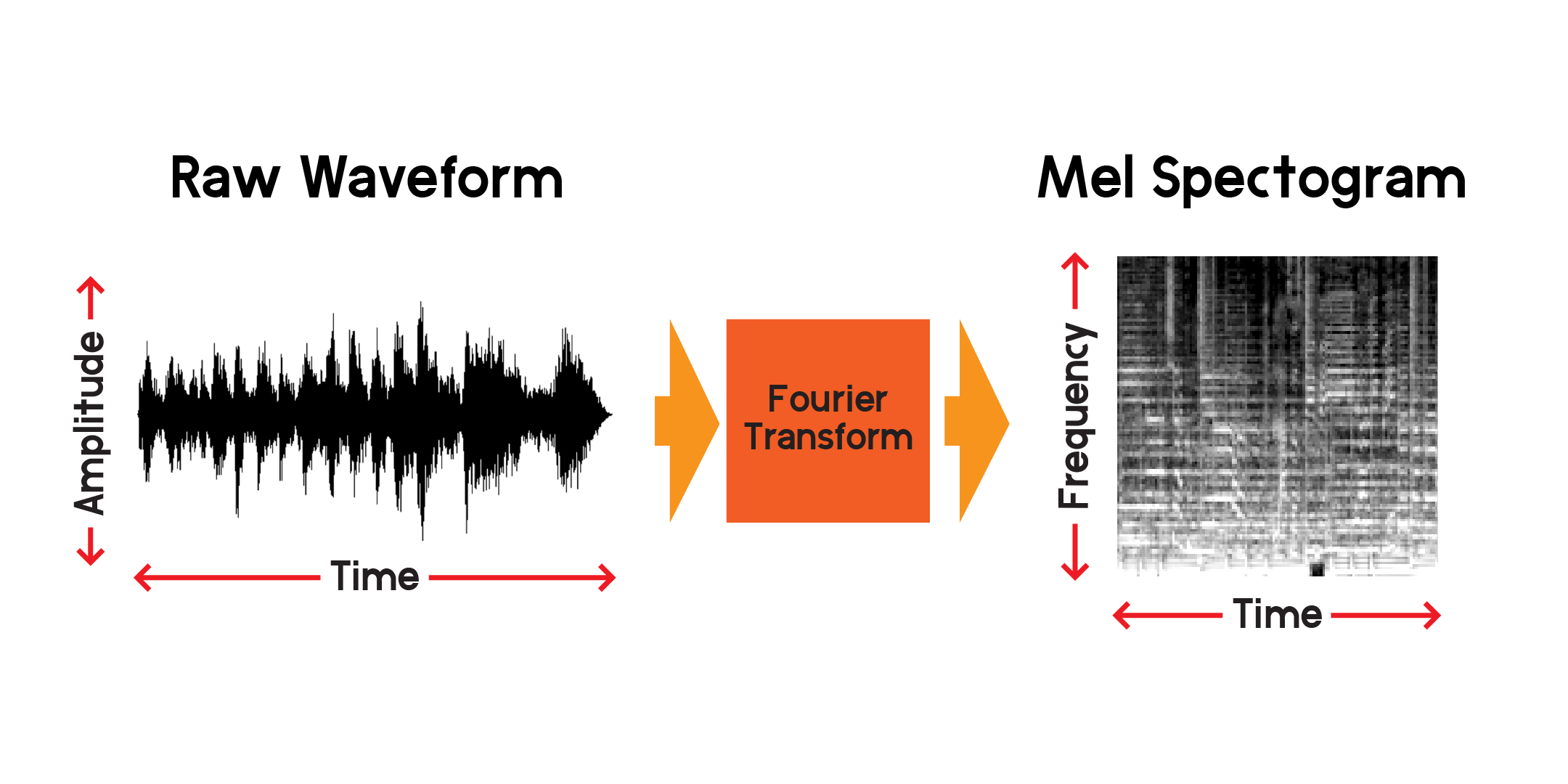
上でプロットしたのと同じオーディオ サンプルからのメル スペクトログラムの例をプロットしてみましょう。
Spotify のパブリック API を使用して、以前のノートブックに曲情報をスクレイピングしました。そこから、各曲の 30 秒の MP3 プレビューをダウンロードし、画像をトレーニングするニューラル ネットワークで使用するメル スペクトログラムに変換できます。まず、mp3 プレビューを収集するために使用するデータ フレームを見てみましょう。
別のノートブックでは、Spotify API からプレビュー リンクを取得し、mp3 をダウンロードし、サウンド ファイルをメル スペクトログラム、メル周波数ケプストラム係数、およびクロマグラムを含む複合画像に変換しました。私はこれらの他の変換を使用することを目的としてこの合成画像を作成しましたが、このプロジェクトではメル スペクトログラムでニューラル ネットワークをトレーニングするだけです。
音声の内容だけで似た曲をレコメンドするには、曲の内容を何らかの形で説明する機能を作成する必要があります。また、これを迅速に行うには、各曲の情報をメル スペクトログラムの入力よりも小さい数値セットに圧縮する必要があります。
各曲のプレビュー ファイルには 600,000 を超えるサンプルがあります。各メル スペクトログラムには、512 x 128 ピクセル、合計 65,536 ピクセルがあります。 128x128 の画像でも 16,384 ピクセルが含まれています。このオートエンコーダー モデルは、曲のコンテンツをわずか 256 個の数値に圧縮します。オートエンコーダが十分にトレーニングされると、ネットワークは最小限の損失で長さ 256 のベクトルから曲を再構築できるようになります。
オートエンコーダは、エンコーダとデコーダで構成されるニューラル ネットワークの一種です。まず、エンコーダーは入力の情報をはるかに少ないデータ量に圧縮し、デコーダーは元の出力にできるだけ近くなるようにデータを再構築します。
オートエンコーダーは、完全に監視されていないわけではありませんが、監視されていないという点で特殊なタイプのニューラル ネットワークでもあります。入力を使用してモデルの出力をトレーニングするため、自己教師ありです。
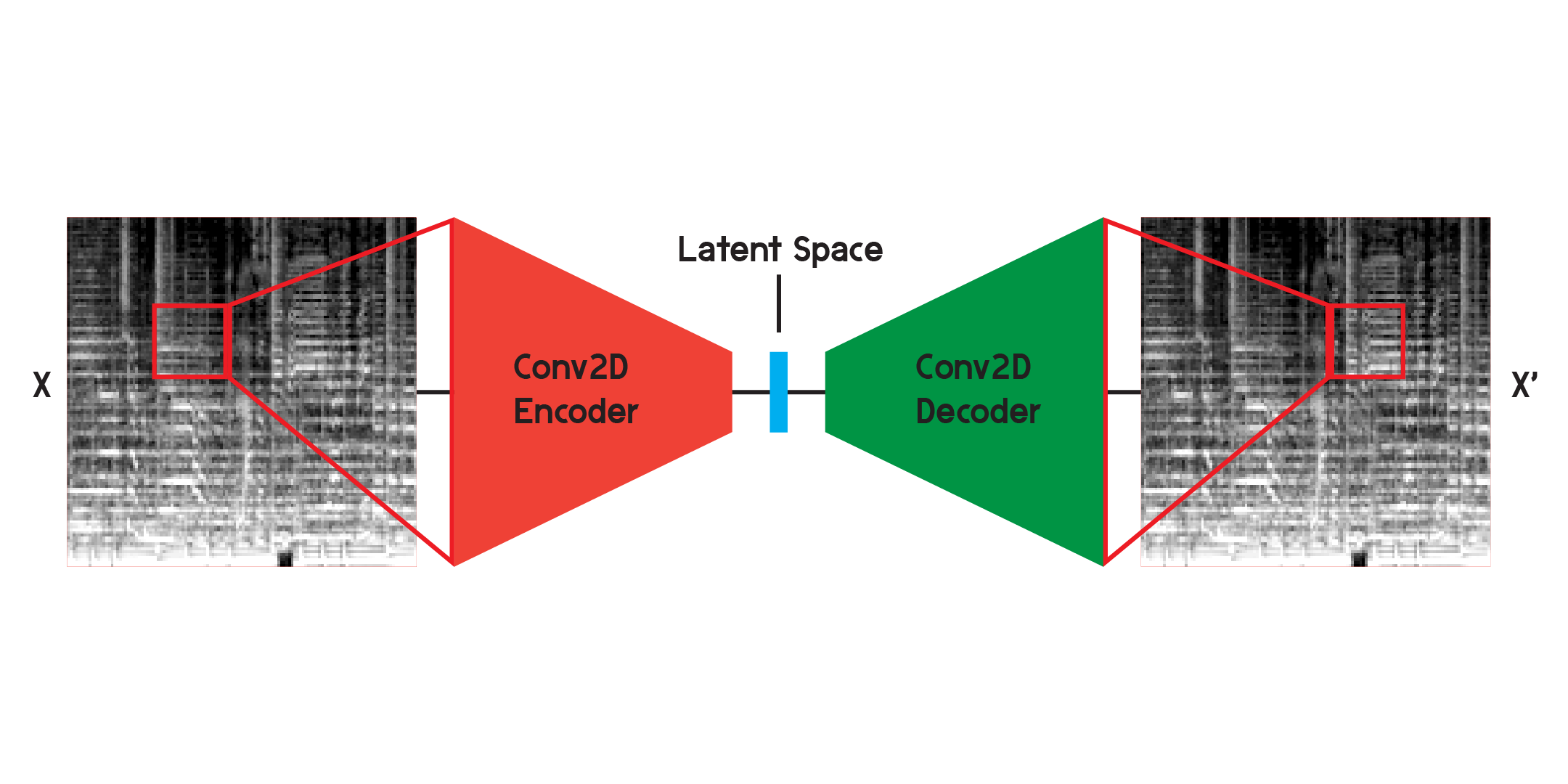
画像を操作する場合、エンコーダは一連の 2 次元畳み込み層であり、加重フィルターを作成して画像内のパターンを抽出すると同時に、画像をますます小さい形状に圧縮します。デコーダはエンコーダのプロセスを鏡映し、少量のデータを再形成してより大きなデータに拡張します。このモデルは、オリジナルと再構成の間の平均二乗誤差を最小限に抑えます。十分にトレーニングされると、モデルの元のモデルと出力の間の平均二乗誤差は非常に小さくなります。平均二乗誤差は最小限になりますが、再構成画像と元の画像の間には、特に細部において視覚的な違いが依然として存在します。オートエンコーダーはノイズリデューサーです。できるだけ多くの詳細を抽出したいと考えていますが、最終的にはオートエンコーダーによって一部の詳細もブレンドされます。
最初に上に示した構造を使用してネットワークをトレーニングしましたが、再構成では多くの詳細が欠落していることがわかりました。畳み込み層は、画像全体のほんの一部であるパターンを検索します。しかし、フィルターをトレーニングして観察した後、抽出されたパターンを直感的に理解するのは困難です。
このようなオートエンコーダーは、いくつかの異なる問題に使用でき、畳み込み層を使用すると、画像の認識と生成に多くの用途があります。しかし、メル スペクトログラムは単なる画像ではなく、時間の経過に伴う音の内容の周波数のグラフであるため、2 次元の畳み込みによって生じる不確実性を最小限に抑えながら、再構成の損失を最小限に抑えるために、少し異なる構造を実装できると思います。層。
モデルの最終結果に使用されるモデルでは、エンコーダーを 2 つの別個のエンコーダーに分割しました。各エンコーダは1 次元の畳み込み層を使用して画像の空間を圧縮します。 1 つのエンコーダーは X でトレーニングし、もう 1 つは X 転置または入力の 90 度回転バージョンでトレーニングします。このようにして、一方のエンコーダーは画像の時間軸から情報を学習し、もう一方のエンコーダーは周波数軸から学習します。
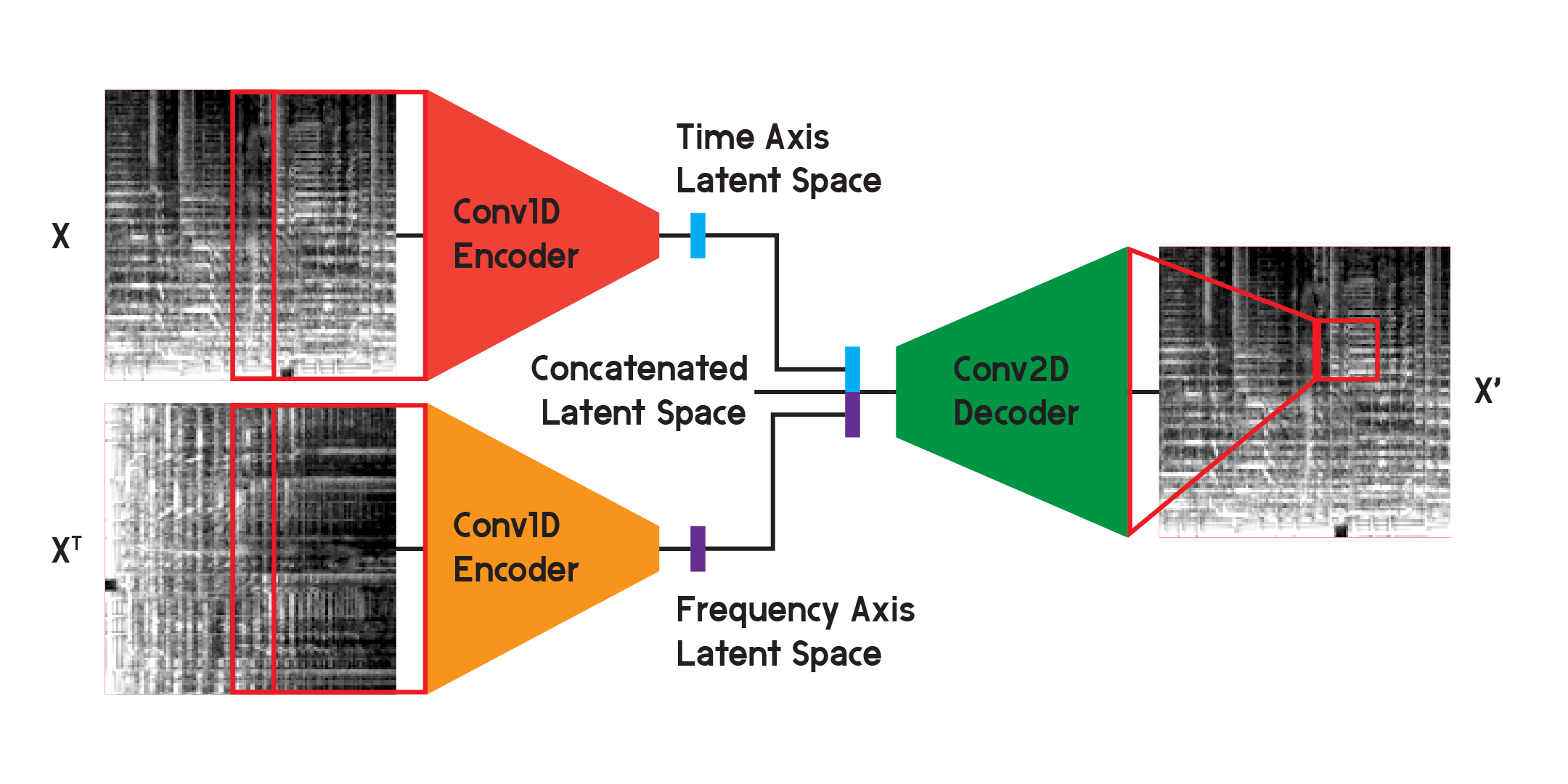
入力が各エンコーダを通過した後、結果として得られるエンコードされたベクトルは 1 つのベクトルに連結され、前に示したように2 次元畳み込みデコーダに入力されます。出力は、以前と同様に入力間の損失を最小限に抑えるようにトレーニングされます。
最終的に、最終モデルの損失は基本構造よりもはるかに低くなり、20 エポック後には平均二乗誤差が 0.0037 (トレーニング)、0.0037 (検証) に達しました。トレーニング セットには 125,440 枚の画像があり、トレーニング セットには 2560 枚の画像がありました。検証セット。
別のノートブックでモデルをトレーニングしたため、ここではデモンストレーションのみを目的としてモデルを構築し、構築後にトレーニング済みのモデルから重みをロードします。
ネットワーク経由で推論を実行し、結果を保存するためのカスタム クラスを使用すると、すべてのメル スペクトログラムの潜在空間を構築できます。これを行うには、エンコーダのみを介してデータを実行し、モデルを初期化したサイズ (この場合は 256 次元) のベクトルを受け取ります。
データの潜在空間によって作成された抽象的な風景をモデルを通じて探索するには、次元削減を使用できます。 UMAP は、T-SNE と同様に、多次元空間を 2 次元に縮小してプロットで視覚化できます。
カスタム LatentSpace クラスは、各ベクトルのコサイン類似度を使用して推奨事項を検索します。
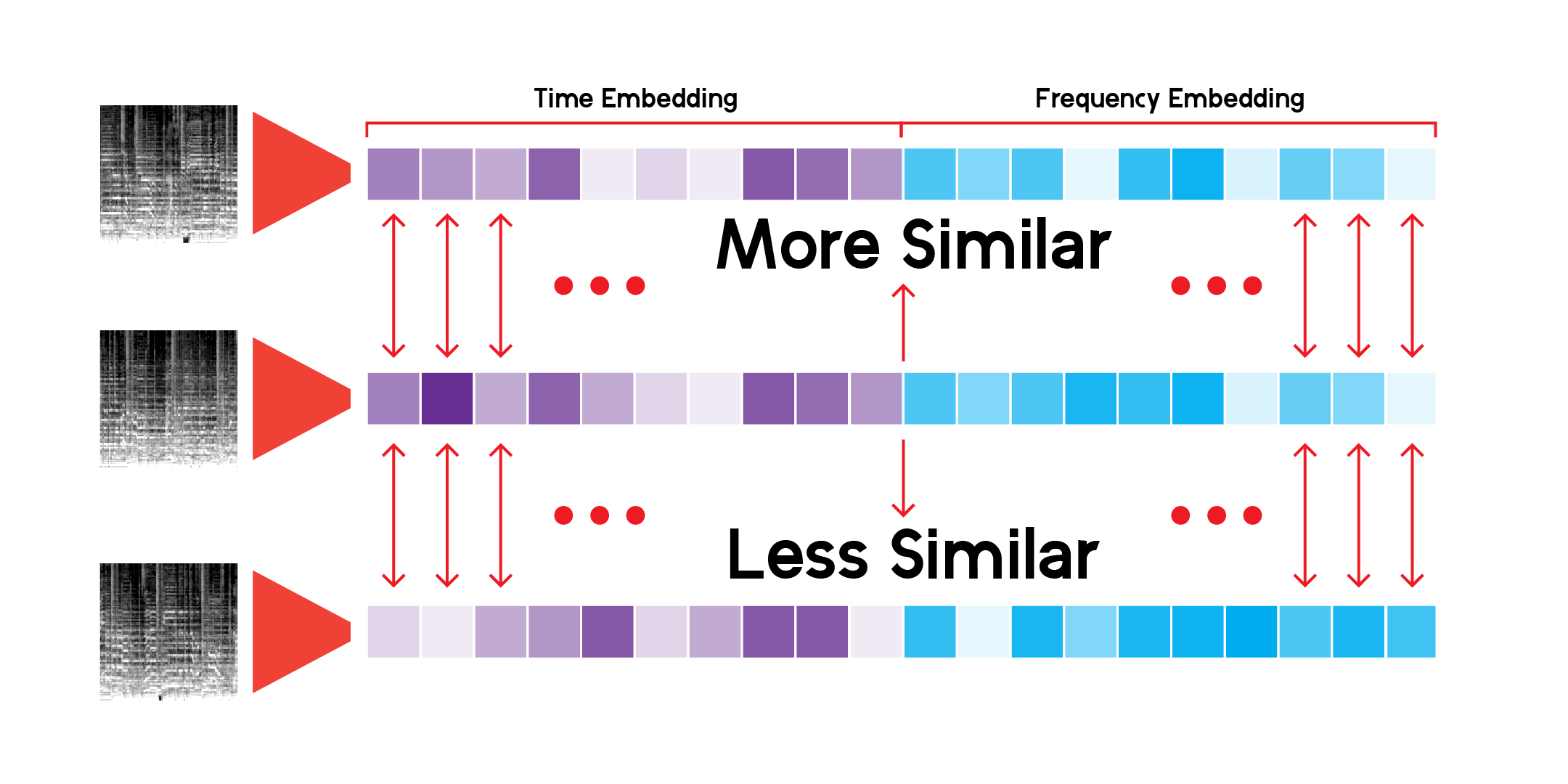
私はこのレコメンデーション システムを際限なく検索してきましたが、このモデルが異なる、しかし似ている音楽サウンドの間の非常に興味深いつながりを見つけ出すことができることに満足しています。私の結論の一部を以下に示します。
これが言いたいのは、モデルは各曲の音声コンテンツに基づいて推奨を行っていますが、曲を聴いているわけではないということです。メル スペクトログラムを作成し、数学的比較を行います。
場合によっては、システムが曲の古さに基づいて曲を推奨することがあります。曲がずっと前に録音された場合、録音素材または機器の特定の周波数がモデルによって検出され、結果が表示されます。
また、このモデルは声や特定の楽器を拾うのにも非常に優れています。このため、曲に話したり、話したり歌ったりすることが多く含まれている場合は、スポークン ワード トラックのみが推奨される可能性があります。また、曲に歪みが多い場合には、雨の音や鳥のさえずりが推奨される場合があります。
最初の EDA で指摘したように、一部のトラックのプレビューは Spotify API では利用できません。したがって、モデルへの貢献も欠けており、モデルに完全に適合する可能性がある場合には推奨されません。たとえば、ジェームス ブラウン、ビートルズ、プリンスの曲はありません。さらに多くのデータが必要です。
このシステムは推奨を行うために 278,000 を超えるプレビューを使用していますが、それでも十分ではありません。すべてのトラックの UMAP 投影を見ると、データには多くの連続性がありますが、いくつかの穴があります。理想的には、システムはより多くのデータを利用できるようになります。
Spotify のようなレコメンデーション システム/サービスがレコメンデーションの作成に非常に優れているのは、このようなさまざまな種類のレコメンデーション システムと機能を組み合わせてレコメンデーションを提供しているためです。あなたが定期的に聴いている曲の追跡から、類似したユーザーの使用状況に基づいて推奨事項を見つけるための協調フィルタリングの使用まで、Spotify は、誰かが何を好み、何を聴くかについて、よりバランスのとれた予測を行うことができます。このモデルは予測を行う上で興味深いと思いますが、より適切な予測を行うために、類似のジャンル、リリース年、類似のユーザー データなどの機能を追加することで機能を強化できます。
全体として、予測や推奨を行うことは別として、このモデルの真の重要性は、音楽言語とサウンドの連続性とスペクトルを説明することにあると感じています。ジャンルは人々がアーティストやサウンドに付けるラベルですが、ジャンルは融合しており、少なくとも数学的にはすべてのサウンドがこの連続した空間に存在します。
また、音楽には壁がありません。ほとんどの場合、レコメンデーション システムで曲をクエリすると、さまざまな時代やさまざまな場所から結果が得られます。曲のメタデータはオートエンコーダーへの入力ではないため、結果は音の類似性に基づくものであり、それ以上のものではありません。


