T5Elasticsearch
1.0.0
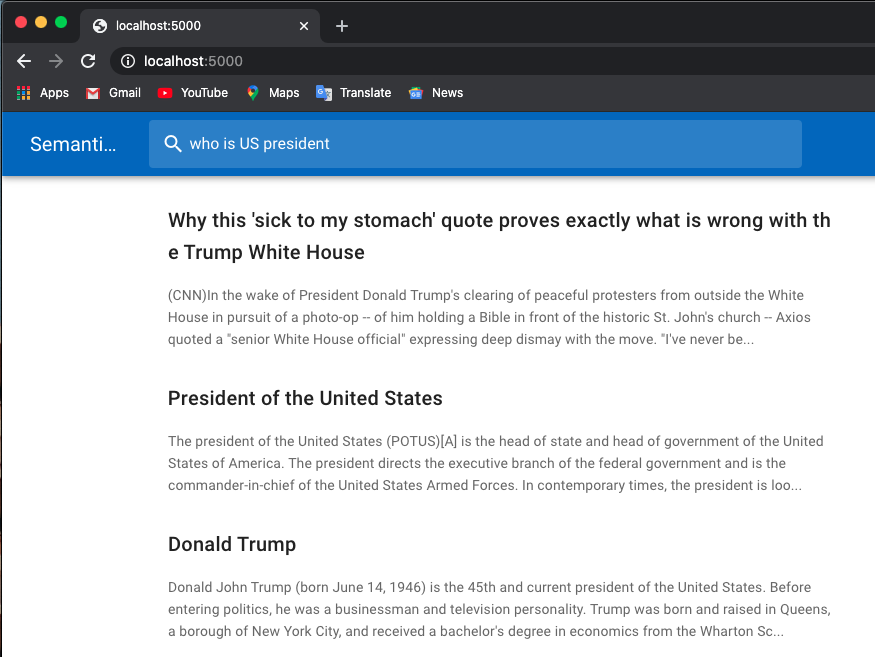
以下は求人検索の例です。
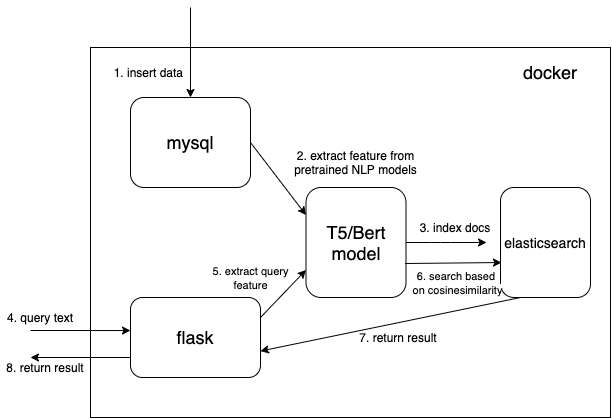
ハグフェイストランスフォーマーの事前トレーニング済みモデルを使用します。
事前トレーニングされたトークナイザーと t5/bert モデルをローカル ディレクトリに手動でダウンロードします。ここでモデルを確認できます。
「t5-small」モデルを使用しています。ここにチェックを入れ、 List all files in modelをクリックしてファイルをダウンロードします。 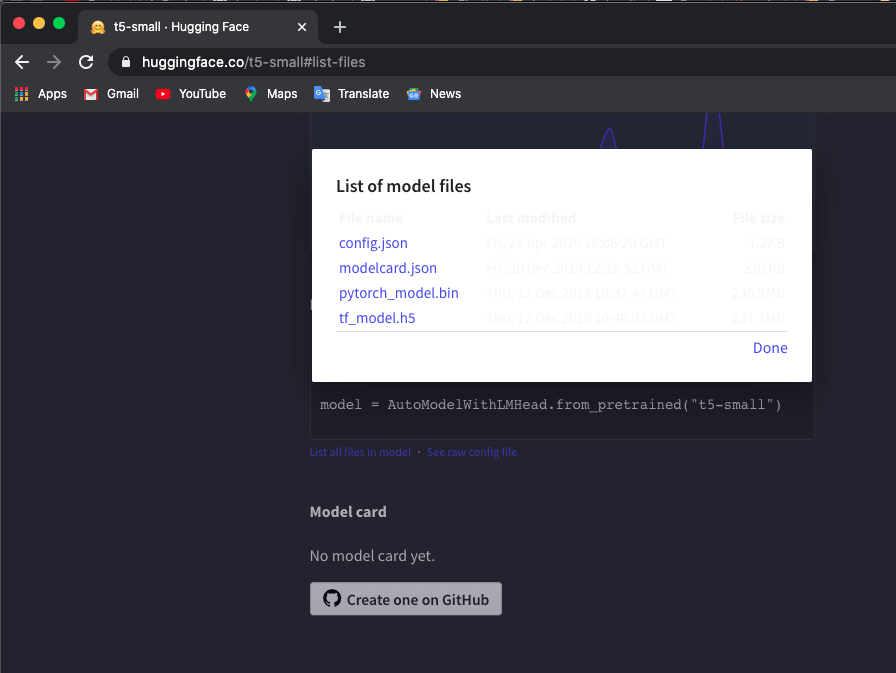
手動でダウンロードしたファイルのディレクトリ構造に注目してください。
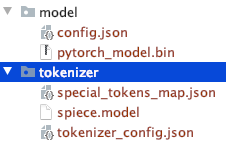
他の T5 モデルまたは Bert モデルを使用することもできます。
他のモデルをダウンロードする場合は、hugaface transformers pretraid モデル リストでモデル名を確認してください。
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --buildまた、 docker system prune使用して、未使用のコンテナー、ネットワーク、イメージをすべて削除し、メモリを増やしています。 Container exits with non-zero exit code 137する場合は、Docker メモリを増やしてください (私は8GBを使用します)。
事前トレーニングされた NLP モデル (ここでは t5 または bert ですが、興味のある事前トレーニングされたモデルを自分で追加できます) から抽出された特徴を保存するために、密なベクトル データタイプを使用します。
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
}寸法寸法dims:512 T5 モデル用です。 Bert モデルを使用する場合は、 dimsを 768 に変更します。
mysql からドキュメントを読み取り、ドキュメントを正しい json 形式に変換して elasticsearch に一括保存します。
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'http://127.0.0.1:5000 にアクセスします。
事前トレーニング済みモデルを使用して特徴を抽出するための主要なコードは、 ./index_files/indexing_files.pyおよび./web/app.pyファイルのget_emb関数です。
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()コードを変更して、お気に入りの事前トレーニング済みモデルを使用できます。たとえば、GPT2 モデルを使用できます。
. .webapp.pyのcosineSimilarityの代わりに独自のスコア関数を使用して、elasticsearch をカスタマイズすることもできます。
この担当者は、bert 機能を抽出するためにbert-servingパッケージを使用する Hironsan/bertsearch に基づいて変更されています。 TF1.xに限る


