nlp lt
1.0.0
この研究の主な目的は、リトアニア語の自然言語処理 (NLP) 原理を研究し学習することです。古典的な NLP 手法を分析し、それがどのように機能するかを確認することは興味深いため、この作業では、テキスト分類、トピック抽出、検索クエリ、およびクラスタリングのアイデアを実装しました。実装の詳細とその他の情報は、paper/paper.pdfに保存されています。
データ分析はテキスト データがなければ確立できません。そのため、私の仕事は最も人気のあるニュース Web サイト www.delfi.lt から生データを取得することから始まりました。 5つのカテゴリ(犯罪[227記事]、音楽[120記事]、映画[167記事]、スポーツ[136記事]、科学[204記事])から記事をクロールすることにしました。
分類パフォーマンスは、行が真のカテゴリ、列が予測カテゴリである混同行列を使用して測定されます。さらに、このようなアプローチは 90% を超える再現率と 90% を超える精度に達します。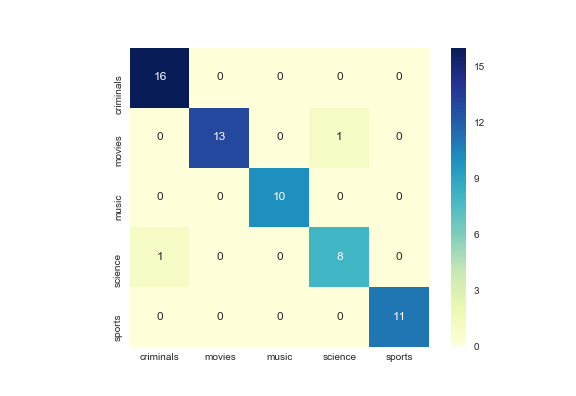
図は、各コンポーネントに 10 個のトークンを持つ 6 つのコンポーネントを示しています。これらの結果から、最も重要な単語を検出し、各主成分のトピックを直感的に推測できます。たとえば、4 主成分にはスポーツや音楽に関する情報が保存されますが、6 主成分には犯罪に関する情報が保存されます。
主な結果を以下に示します。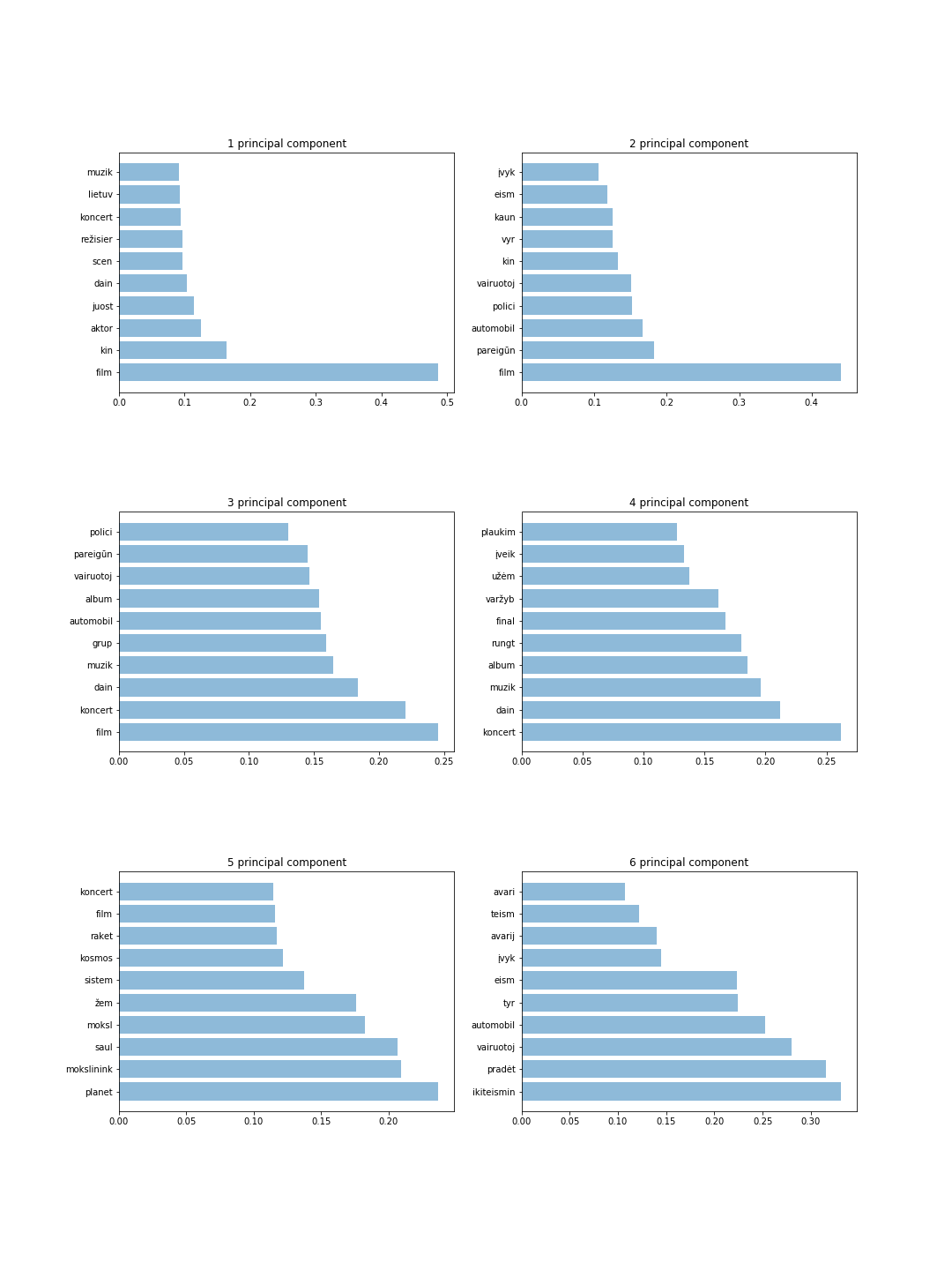
検索は http://webhome.cs.uvic.ca/~thomo/svd.pdf の記事に基づいており、lsa が適用されて、クエリの正確な類似性だけでなく、ドキュメント間のより深い関係を使用して関連ドキュメントが検索されます。
クエリ = "シュビエティム アプドヴァノジャム"
結果:
進行中


