
このリポジトリには、DevOps や SRE に関連するさまざまな技術的なトピックに関する質問や演習が含まれています
現在2624 個の演習と質問があります
️これらは面接の準備に使用できますが、ほとんどの質問や演習は実際の面接を表すものではありません。詳しくはFAQページをご覧ください
? DevOps エンジニアとしてのキャリアを追求することに興味がある場合、ここで説明されている概念のいくつかを学習することは役に立ちますが、このリポジトリで説明されているすべてのトピックやテクノロジを学習することではないことを知っておく必要があります。
プル リクエストを送信することで、さらに演習を追加できます :) 貢献ガイドラインについては、こちらをお読みください。

DevOps | 
Git | 
ネットワーク | 
ハードウェア | 
Kubernetes |

ソフトウェア開発 | 
パイソン | 
行く | 
パール | 
正規表現 |

雲 | 
AWS | 
アズール | 
Googleクラウドプラットフォーム | 
オープンスタック |

オペレーティング·システム | 
Linux | 
仮想化 | 
DNS | 
シェルスクリプト |

データベース | 
SQL | 
モンゴ | 
テスト | 
ビッグデータ |

CI/CD | 
証明書 | 
コンテナ | 
オープンシフト | 
ストレージ |

テラフォーム | 
人形 | 
分散型 | 
質問できる質問 | 
アンシブル |

可観測性 | 
プロメテウス | 
サークルCI | 
| 
グラファナ |

アルゴ | 
ソフトスキル | 
安全 | 
システム設計 |

カオスエンジニアリング | 
その他 | 
弾性のある | 
カフカ | 
NodeJ |
ネットワーク
一般的に、コミュニケーションをとるためには何が必要ですか?
- 共通言語 (双方が理解できる)
- 通信したい相手に宛てる方法 接続
- (通信の内容が受信者に届くようにするため)
TCP/IPとは何ですか?
2 つ以上のデバイスが相互に通信する方法を定義する一連のプロトコル。
TCP/IP について詳しくは、ここをお読みください。
イーサネットとは何ですか?
イーサネットは、現在使用されている最も一般的なタイプのローカル エリア ネットワーク (LAN) を指します。 LAN は、より広い地理的エリアにまたがる WAN (ワイド エリア ネットワーク) とは対照的に、オフィス、大学のキャンパス、さらには自宅などの狭いエリアにあるコンピュータの接続ネットワークです。
MACアドレスとは何ですか?何に使われますか?
MAC アドレスは、ネットワーク上の個々のデバイスを識別するために使用される固有の識別番号またはコードです。
イーサネット上で送信されるパケットは常に MAC アドレスから送信され、MAC アドレスに送信されます。ネットワーク アダプターがパケットを受信すると、パケットの宛先 MAC アドレスとアダプター自体の MAC アドレスが比較されます。
この MAC アドレスはいつ使用されますか?: ff:ff:ff:ff:ff:ff
デバイスがブロードキャスト MAC アドレス (FF:FF:FF:FF:FF:FF) にパケットを送信すると、そのパケットはローカル ネットワーク上のすべてのステーションに配信されます。イーサネット ブロードキャストは、データ リンク層で (ARP によって) IP アドレスを MAC アドレスに解決するために使用されます。
IPアドレスとは何ですか?
インターネット プロトコル アドレス (IP アドレス) は、通信にインターネット プロトコルを使用するコンピュータ ネットワークに接続されている各デバイスに割り当てられる数値ラベルです。IP アドレスは、ホストまたはネットワーク インターフェイスの識別と位置のアドレス指定という 2 つの主な機能を果たします。
サブネットマスクの説明と例
サブネット マスクは、IP アドレスをマスクし、IP アドレスをネットワーク アドレスとホスト アドレスに分割する 32 ビットの数値です。サブネット マスクは、ネットワーク ビットをすべて「1」に設定し、ホスト ビットをすべて「0」に設定することによって作成されます。特定のネットワーク内では、使用可能なホスト アドレスの合計のうち 2 つは常に特定の目的のために予約されており、どのホストにも割り当てることはできません。これらは、ネットワーク アドレス (別名ネットワーク ID) として予約されている最初のアドレスと、ネットワーク ブロードキャストに使用される最後のアドレスです。
例
プライベートIPアドレスとは何ですか?どのようなシナリオ/システム設計で使用する必要がありますか?
プライベート IP アドレスは、相互に通信するために同じネットワーク内のホストに割り当てられます。 「プライベート」という名前が示すように、プライベート IP アドレスが割り当てられたデバイスには、外部ネットワークからのデバイスはアクセスできません。たとえば、私がホステルに住んでいて、ホステルの仲間に私がホストしているゲーム サーバーに参加してもらいたい場合、ネットワークはホステルに対してローカルであるため、私のサーバーのプライベート IP アドレスを介して参加するように依頼します。パブリックIPアドレスとは何ですか?どのようなシナリオ/システム設計で使用する必要がありますか?
パブリック IP アドレスは、一般向けの IP アドレスです。友人に参加してもらいたいゲーム サーバーをホストしている場合は、友人のコンピュータが接続を確立するためにあなたのネットワークとサーバーを識別して見つけられるように、パブリック IP アドレスを友人に提供します。公開 IP アドレスを使用する必要がないのは、同じネットワークに接続している友達とプレイしている場合です。その場合は、プライベート IP アドレスを使用します。誰かが内部にあるサーバーに接続できるようにするには、ポート転送を設定して、パブリック ドメインからネットワークへのトラフィック、またはその逆のトラフィックを許可するようにルーターに指示する必要があります。 OSIモデルについて説明します。どのような層があるのでしょうか?各層は何を担当しますか?
- アプリケーション: ユーザー側 (HTTP はここにあります)
- プレゼンテーション: アプリケーション層エンティティ間のコンテキストを確立します (暗号化はここにあります)
- セッション: 接続を確立、管理、終了します
- トランスポート: 可変長データ シーケンスをソースから宛先ホスト (TCP) に転送しますおよび UDP はここにあります)
- ネットワーク: あるネットワークから別のネットワークにデータグラムを転送します (IP はここにあります)
- データ リンク: 直接接続された 2 つのノード間のリンクを提供します (MAC はここにあります)
- 物理: データ接続の電気的および物理的な仕様 (ビット)ここにいます)
OSI モデルの詳細については、penguintutor.com をご覧ください。
次のそれぞれについて、どの OSI 層に属するかが決まります。- エラー訂正
- パケットルーティング
- ケーブルと電気信号
- MACアドレス
- IPアドレス
- 接続を終了する
- 3ウェイハンドシェイク
エラー修正 - データ リンクパケット ルーティング - ネットワークケーブルと電気信号 - 物理MAC アドレス - データ リンクIP アドレス - ネットワーク終了接続 - セッション3 ウェイ ハンドシェイク - トランスポートどのような配送スキームを知っていますか?
ユニキャスト: 1 人の送信者と 1 人の受信者が存在する 1 対 1 の通信。
ブロードキャスト: ネットワーク内の全員にメッセージを送信します。アドレス ff:ff:ff:ff:ff:ff はブロードキャストに使用されます。ブロードキャストを使用する 2 つの一般的なプロトコルは、ARP と DHCP です。
マルチキャスト: 加入者のグループにメッセージを送信します。 1 対多または多対多の場合があります。
CSMA/CDとは何ですか?最新のイーサネット ネットワークで使用されていますか?
CSMA/CD は、Carrier Sense Multiple Access / Collision Detection の略です。その主な焦点は、特定の時点で 1 つのホストだけが送信できる共有メディア/バスへのアクセスを管理することです。
CSMA/CD アルゴリズム:
フレームを送信する前に、別のホストがすでにフレームを送信しているかどうかを確認します。- 誰も送信していない場合は、フレームの送信を開始します。
- 2 つのホストが同時に送信すると、衝突が発生します。
- 両方のホストがフレームの送信を停止し、衝突が発生したことを全員に通知する「ジャム信号」を全員に送信します。
- 再送信するまでランダムな時間を待っています
- 各ホストはランダムな時間待機すると、再度フレームの送信を試行し、サイクルが再び開始されます。
次のネットワーク デバイスとそれらの違いについて説明します。
ルーター、スイッチ、ハブはすべて、ローカル エリア ネットワーク (LAN) 内のデバイスを接続するために使用されるネットワーク デバイスです。ただし、各デバイスの動作は異なり、固有の使用例があります。各デバイスとそれらの違いについて簡単に説明します。
ルーター: 複数のネットワーク セグメントを接続するネットワーク デバイス。 OSI モデルのネットワーク層 (レイヤー 3) で動作し、ルーティング プロトコルを使用してネットワーク間でデータを転送します。ルーターは IP アドレスを使用してデバイスを識別し、データ パケットを正しい宛先にルーティングします。- スイッチ: LAN 上で複数のデバイスを接続するネットワーク デバイス。 OSI モデルのデータ リンク層 (レイヤー 2) で動作し、MAC アドレスを使用してデバイスを識別し、データ パケットを正しい宛先に送信します。スイッチを使用すると、同じネットワーク上のデバイスがより効率的に相互に通信できるようになり、複数のデバイスが同時にデータを送信するときに発生する可能性のあるデータの衝突を防ぐことができます。
- ハブ: 1 本のケーブルを介して複数のデバイスを接続するネットワーク デバイス。ネットワークを分割せずに複数のデバイスを接続するために使用されます。ただし、スイッチとは異なり、OSI モデルの物理層 (レイヤー 1) で動作し、デバイスが目的の受信者であるかどうかに関係なく、接続されているすべてのデバイスにデータ パケットをブロードキャストするだけです。これは、データの衝突が発生する可能性があり、その結果、ネットワークの効率が低下する可能性があることを意味します。スイッチの方が効率的でネットワーク パフォーマンスが向上するため、最新のネットワーク設定ではハブは通常使用されません。
「コリジョンドメイン」とは何ですか?
コリジョン ドメインは、デバイスが同時にデータを送信しようとすることで相互に干渉する可能性があるネットワーク セグメントです。 2 つのデバイスが同時にデータを送信すると、衝突が発生し、データが失われたり破損したりする可能性があります。コリジョン ドメインでは、すべてのデバイスが同じ帯域幅を共有するため、どのデバイスも他のデバイスによるデータ送信を妨害する可能性があります。 「ブロードキャストドメイン」とは何ですか?
ブロードキャスト ドメインは、すべてのデバイスがブロードキャスト メッセージを送信することによって相互に通信できるネットワーク セグメントです。ブロードキャスト メッセージは、特定のデバイスではなく、ネットワーク内のすべてのデバイスに送信されるメッセージです。ブロードキャスト ドメインでは、メッセージが自分宛てであるかどうかに関係なく、すべてのデバイスがブロードキャスト メッセージを受信して処理できます。 3 台のコンピュータがスイッチに接続されています。衝突ドメインはいくつありますか?ブロードキャスト ドメインはいくつありますか?
3 つのコリジョン ドメインと 1 つのブロードキャスト ドメイン
ルーターはどのように機能するのでしょうか?
ルーターは、2 つ以上のパケット交換コンピュータ ネットワーク間で情報を受け渡す物理または仮想アプライアンスです。ルーターは、特定のデータ パケットの宛先インターネット プロトコル アドレス (IP アドレス) を検査し、宛先に到達するための最適な方法を計算し、それに応じてパケットを転送します。
NATとは何ですか?
ネットワーク アドレス変換 (NAT) は、ローカル ホストにインターネット アクセスを提供するために、1 つ以上のローカル IP アドレスを 1 つ以上のグローバル IP アドレスに、またはその逆に変換するプロセスです。
プロキシとは何ですか?どのように機能するのでしょうか?何のためにそれが必要なのでしょうか?
プロキシ サーバーは、ユーザーとインターネットの間のゲートウェイとして機能します。これは、エンド ユーザーを閲覧する Web サイトから分離する中間サーバーです。
プロキシ サーバーを使用している場合、インターネット トラフィックは、要求したアドレスに向かう途中でプロキシ サーバーを通過します。その後、リクエストは同じプロキシ サーバー経由で返され (このルールには例外があります)、プロキシ サーバーは Web サイトから受信したデータを転送します。
プロキシ サーバーは、ユースケース、ニーズ、または会社のポリシーに応じて、さまざまなレベルの機能、セキュリティ、プライバシーを提供します。
TCPとは何ですか?どのように機能するのでしょうか? 3ウェイハンドシェイクとは何ですか?
TCP 3 ウェイ ハンドシェイクまたは 3 ウェイ ハンドシェイクは、TCP/IP ネットワークでサーバーとクライアント間の接続を確立するために使用されるプロセスです。
3 ウェイ ハンドシェイクは主に、TCP ソケット接続を作成するために使用されます。次の場合に機能します。
クライアント ノードは、IP ネットワーク経由で同じネットワークまたは外部ネットワーク上のサーバーに SYN データ パケットを送信します。このパケットの目的は、サーバーが新しい接続に対して開いているかどうかを尋ねたり推測したりすることです。- ターゲット サーバーには、新しい接続を受け入れて開始できるオープン ポートが必要です。サーバーはクライアント ノードから SYN パケットを受信すると、応答して確認受信 (ACK パケットまたは SYN/ACK パケット) を返します。
- クライアント ノードはサーバーから SYN/ACK を受信し、ACK パケットで応答します。
往復遅延または往復時間とは何ですか?
ウィキペディアより: 「信号の送信にかかる時間と、その信号の受信確認にかかる時間の合計」
おまけの質問: LAN の RTT とは何ですか?
SSL ハンドシェイクはどのように機能しますか?
SSL ハンドシェイクは、クライアントとサーバーの間に安全な接続を確立するプロセスです。クライアントは、クライアントの SSL/TLS プロトコルのバージョン、クライアントがサポートする暗号化アルゴリズムのリスト、およびランダム値を含む Client Hello メッセージをサーバーに送信します。- サーバーは、サーバーの SSL/TLS プロトコルのバージョン、ランダム値、およびセッション ID を含む Server Hello メッセージで応答します。
- サーバーは、サーバーの証明書を含む証明書メッセージを送信します。
- サーバーは Server Hello Done メッセージを送信します。これは、サーバーが Server Hello フェーズのメッセージの送信を完了したことを示します。
- クライアントは、クライアントの公開キーを含むクライアント キー交換メッセージを送信します。
- クライアントは、暗号仕様変更メッセージを送信します。これにより、クライアントが新しい暗号仕様で暗号化されたメッセージを送信しようとしていることをサーバーに通知します。
- クライアントは、サーバーの公開キーで暗号化されたプレマスター シークレットを含む暗号化ハンドシェイク メッセージを送信します。
- サーバーは暗号仕様変更メッセージを送信し、サーバーが新しい暗号仕様で暗号化されたメッセージを送信しようとしていることをクライアントに通知します。
- サーバーは、クライアントの公開キーで暗号化されたプレマスター シークレットを含む暗号化ハンドシェイク メッセージを送信します。
- これで、クライアントとサーバーはアプリケーション データを交換できるようになります。
TCPとUDPの違いは何ですか?
TCP はクライアントとサーバー間の接続を確立してパッケージの順序を保証します。一方、UDP はクライアントとサーバー間の接続を確立せず、パッケージの順序を処理しません。これにより、UDP は TCP よりも軽量になり、ストリーミングなどのサービスに最適な候補になります。
Penguintutor.com が詳しい説明を提供しています。
あなたがよく知っている TCP/IP プロトコルは何ですか?
「デフォルトゲートウェイ」について解説します
デフォルト ゲートウェイは、ネットワークに接続されたコンピュータが別のネットワークまたはインターネット内のコンピュータに情報を送信するために使用するアクセス ポイントまたは IP ルーターとして機能します。
ARPとは何ですか?どのように機能するのでしょうか?
ARPはアドレス解決プロトコルの略です。ローカル ネットワーク上の IP アドレス (たとえば 192.168.1.1) に ping を実行しようとすると、システムは IP アドレス 192.168.1.1 を MAC アドレスに変換する必要があります。これには、ARP を使用してアドレスを解決することが含まれるため、その名前が付けられています。
システムは、どの IP アドレスがどの MAC アドレスに関連付けられているかに関する情報を保存する ARP ルックアップ テーブルを保持します。 IP アドレスにパケットを送信しようとすると、システムは最初にこのテーブルを参照して、MAC アドレスがすでに認識されているかどうかを確認します。キャッシュされた値がある場合、ARP は使用されません。
TTLとは何ですか?何を防ぐのに役立ちますか?
TTL (Time to Live) は、パケットが破棄されるまでに通過できるホップまたはルーターの数を決定する IP (インターネット プロトコル) パケットの値です。ルーターによってパケットが転送されるたびに、TTL 値は 1 ずつ減ります。 TTL 値がゼロに達すると、パケットはドロップされ、パケットの有効期限が切れたことを示す ICMP (インターネット コントロール メッセージ プロトコル) メッセージが送信者に送り返されます。- TTL は、パケットがネットワーク内で無制限に循環することを防ぐために使用されます。これにより、輻輳が発生し、ネットワークのパフォーマンスが低下する可能性があります。
- また、パケットが宛先に到達せずに同じルーターのセット間を継続的に移動するルーティング ループにパケットがトラップされるのを防ぐのにも役立ちます。
- さらに、TTL を使用すると、攻撃者が虚偽または偽の IP アドレスを使用してネットワーク上の別のデバイスになりすまそうとする IP スプーフィング攻撃の検出と防止に役立ちます。 TTL はパケットが通過できるホップ数を制限することで、パケットが正当でない宛先にルーティングされるのを防ぐことができます。
DHCPとは何ですか?どのように機能するのでしょうか?
これは、Dynamic Host Configuration Protocol の略で、IP アドレス、サブネット マスク、ゲートウェイをホストに割り当てます。仕組みは次のとおりです。
- ホストはネットワークに入ると、DHCP サーバーを探すメッセージをブロードキャストします (DHCP DISCOVER)
- オファー メッセージは、リース時間、サブネット マスク、IP アドレスなどを含むパケットとして DHCP サーバーによって返送されます (DHCP OFFER)
- どのオファーが受け入れられたかに応じて、クライアントはすべての DHCP サーバーに知らせる応答ブロードキャストを送り返します (DHCP REQUEST)。
- サーバーは確認応答 (DHCP ACK) を送信します。
詳細はこちらをご覧ください
同じネットワーク上に 2 つの DHCP サーバーを配置できますか?どのように機能するのでしょうか?
同じネットワーク上に 2 つの DHCP サーバーを配置することは可能ですが、お勧めできません。競合や構成上の問題を防ぐために、慎重に構成することが重要です。
2 つの DHCP サーバーが同じネットワーク上に構成されている場合、両方のサーバーが IP アドレスとその他のネットワーク構成設定を同じデバイスに割り当てるリスクがあり、競合や接続の問題が発生する可能性があります。さらに、DHCP サーバーが異なるネットワーク設定またはオプションで構成されている場合、ネットワーク上のデバイスは競合する、または一貫性のない構成設定を受信する可能性があります。- ただし、1 つの DHCP サーバーではすべての要求を処理できない大規模なネットワークなど、場合によっては、同じネットワーク上に 2 つの DHCP サーバーが必要になることがあります。このような場合、DHCP サーバーは、相互に干渉しないように、異なる IP アドレス範囲または異なるサブネットにサービスを提供するように構成できます。
SSLトンネリングとは何ですか?どのように機能するのでしょうか?
- SSL (Secure Sockets Layer) トンネリングは、インターネットなどの安全でないネットワーク上で 2 つのエンドポイント間に安全な暗号化された接続を確立するために使用される技術です。 SSL トンネルは、SSL 接続内のトラフィックをカプセル化することによって作成され、機密性、整合性、および認証が提供されます。
SSL トンネリングの仕組みは次のとおりです。
クライアントはサーバーへの SSL 接続を開始します。これには、SSL セッションを確立するためのハンドシェイク プロセスが含まれます。- SSL セッションが確立されると、クライアントとサーバーは暗号化アルゴリズムやキーの長さなどの暗号化パラメータをネゴシエートし、デジタル証明書を交換して相互に認証します。
- 次に、クライアントは SSL トンネル経由でトラフィックをサーバーに送信し、サーバーはトラフィックを復号化して宛先に転送します。
- サーバーは SSL トンネル経由でトラフィックをクライアントに送り返し、クライアントはトラフィックを復号化してアプリケーションに転送します。
ソケットとは何ですか?システム内のソケットのリストはどこで確認できますか?
ソケットは、ネットワーク上のプロセス間の双方向通信を可能にするソフトウェア エンドポイントです。ソケットはネットワーク通信用の標準化されたインターフェイスを提供し、アプリケーションがネットワーク上でデータを送受信できるようにします。 Linux システムで開いているソケットのリストを表示するには: netstat -an- このコマンドは、開いているすべてのソケットのリストを、そのプロトコル、ローカル アドレス、外部アドレス、および状態とともに表示します。
IPv6とは何ですか? IPv4 を使用している場合に、なぜそれを使用することを検討する必要があるのでしょうか?
- IPv6 (インターネット プロトコル バージョン 6) は、ネットワーク上のデバイスの識別と通信に使用されるインターネット プロトコル (IP) の最新バージョンです。 IPv6 アドレスは 128 ビットのアドレスで、2001:0db8:85a3:0000:0000:8a2e:0370:7334 のように 16 進数表記で表されます。
IPv4 ではなく IPv6 の使用を検討すべき理由はいくつかあります。
アドレス空間: IPv4 のアドレス空間は限られており、世界の多くの地域で枯渇しています。 IPv6 ははるかに大きなアドレス空間を提供し、数兆個の一意の IP アドレスを使用できるようになります。- セキュリティ: IPv6 には、ネットワーク トラフィックのエンドツーエンドの暗号化と認証を提供する IPsec のサポートが組み込まれています。
- パフォーマンス: IPv6 には、単一のパケットを複数の宛先に同時に送信できるマルチキャスト ルーティングなど、ネットワーク パフォーマンスの向上に役立つ機能が含まれています。
- 簡素化されたネットワーク構成: IPv6 には、DHCP サーバーを必要とせずにデバイスが独自の IPv6 アドレスを自動的に構成できるステートレス自動構成など、ネットワーク構成を簡素化できる機能が含まれています。
- モビリティ サポートの向上: IPv6 には、デバイスが異なるネットワーク間を移動するときに IPv6 アドレスを維持できるようにするモバイル IPv6 など、モビリティ サポートを向上させる機能が含まれています。
VLANとは何ですか?
- VLAN (仮想ローカル エリア ネットワーク) は、物理的な場所に関係なく、物理ネットワーク上の一連のデバイスをグループ化する論理ネットワークです。 VLAN は、スイッチ上の特定のポートまたはポートのグループに接続されているデバイスによって送信されるフレームに特定の VLAN ID を割り当てるようにネットワーク スイッチを構成することによって作成されます。
MTUとは何ですか?
MTU は最大伝送ユニットの略です。これは、1 回のトランザクションで送信できる最大の PDU (プロトコル データ ユニット) のサイズです。
MTU より大きいパケットを送信するとどうなりますか?
IPv4 プロトコルを使用すると、ルーターは PDU を断片化し、断片化されたすべての PDU をトランザクションを通じて送信できます。
IPv6 プロトコルでは、ユーザーのコンピュータにエラーが発行されます。
本当か嘘か?信頼性の高い接続を重視しないため、Ping は UDP を使用します。
間違い。 Ping は実際には、ネットワーク通信に関連する診断メッセージと制御メッセージを送信するために使用されるネットワーク プロトコルである ICMP (Internet Control Message Protocol) を使用しています。
SDNとは何ですか?
SDN は Software-Defined Networking の略です。これは、ネットワーク制御の集中化に重点を置いたネットワーク管理へのアプローチであり、管理者がソフトウェアの抽象化を通じてネットワークの動作を管理できるようにします。- 従来のネットワークでは、ルーター、スイッチ、ファイアウォールなどのネットワーク デバイスは、専用のソフトウェアまたはコマンド ライン インターフェイスを使用して個別に構成および管理されます。対照的に、SDN はネットワーク コントロール プレーンをデータ プレーンから分離し、管理者が集中ソフトウェア コントローラーを通じてネットワークの動作を管理できるようにします。
ICMPとは何ですか?何に使われますか?
- ICMP は Internet Control Message Protocol の略です。これは、IP ネットワークでの診断と制御の目的で使用されるプロトコルです。これはインターネット プロトコル スイートの一部であり、ネットワーク層で動作します。
ICMP メッセージは、次のようなさまざまな目的に使用されます。
エラー報告: ICMP メッセージは、宛先に配信できなかったパケットなど、ネットワーク内で発生したエラーを報告するために使用されます。- Ping: ICMP は ping メッセージの送信に使用されます。ping メッセージは、ホストまたはネットワークに到達可能かどうかをテストし、パケットの往復時間を測定するために使用されます。
- パス MTU 検出: ICMP は、パスの最大送信単位 (MTU) を検出するために使用されます。MTU は、断片化せずに送信できる最大のパケット サイズです。
- Traceroute: ICMP は、パケットがネットワークを通過するパスを追跡するために、traceroute ユーティリティによって使用されます。
- ルーターの検出: ICMP は、ネットワーク内のルーターを検出するために使用されます。
NATとは何ですか?どのように機能するのでしょうか?
NAT はネットワーク アドレス変換の略です。これは、情報を転送する前に、複数のローカルのプライベート アドレスをパブリック アドレスにマッピングする方法です。複数のデバイスに単一の IP アドレスを使用させる必要がある組織は、ほとんどのホーム ルーターと同様に NAT を使用します。たとえば、コンピュータのプライベート IP は 192.168.1.100 である可能性がありますが、ルーターはトラフィックをパブリック IP (例: 1.1.1.1) にマッピングします。インターネット上のすべてのデバイスには、プライベート IP (192.168.1.100) ではなくパブリック IP (1.1.1.1) からのトラフィックが表示されます。
次の各プロトコルで使用されるポート番号はどれですか?- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- FTP
- SFTP
SSH-22- SMTP - 25
- HTTP - 80
- DNS - 53
- HTTPS - 443
- FTP-21
- SFTP-22
ネットワークのパフォーマンスに影響を与える要因はどれですか?
ネットワークのパフォーマンスに影響を与える可能性がある要因は次のとおりです。
帯域幅: ネットワーク接続で利用可能な帯域幅は、そのパフォーマンスに大きな影響を与える可能性があります。帯域幅が制限されているネットワークでは、データ転送速度が遅く、遅延が長く、応答性が低下する可能性があります。- レイテンシー: レイテンシーは、ネットワークのあるポイントから別のポイントにデータが送信されるときに発生する遅延を指します。遅延が長いと、特にビデオ会議やオンライン ゲームなどのリアルタイム アプリケーションの場合、ネットワーク パフォーマンスが低下する可能性があります。
- ネットワークの輻輳: 同時にネットワークを使用するデバイスが多すぎると、ネットワークの輻輳が発生し、データ転送速度の低下やネットワーク パフォーマンスの低下につながる可能性があります。
- パケットロス: パケットロスは、送信中にデータのパケットがドロップされると発生します。これにより、ネットワーク速度が低下し、ネットワーク全体のパフォーマンスが低下する可能性があります。
- ネットワーク トポロジ: スイッチ、ルーター、その他のネットワーク デバイスの配置を含むネットワークの物理レイアウトは、ネットワーク パフォーマンスに影響を与える可能性があります。
- ネットワーク プロトコル: ネットワーク プロトコルが異なればパフォーマンス特性も異なり、ネットワーク パフォーマンスに影響を与える可能性があります。たとえば、TCP はデータの配信を保証できる信頼性の高いプロトコルですが、エラー チェックと再送信に必要なオーバーヘッドによりパフォーマンスが低下する可能性もあります。
- ネットワーク セキュリティ: ファイアウォールや暗号化などのセキュリティ対策は、特に大幅な処理能力が必要な場合や追加の遅延が発生する場合に、ネットワーク パフォーマンスに影響を与える可能性があります。
- 距離: ネットワーク上のデバイス間の物理的な距離は、ネットワークのパフォーマンスに影響を与える可能性があります。特に、信号強度や干渉が接続性やデータ転送速度に影響を及ぼす可能性があるワイヤレス ネットワークの場合は影響を受けます。
APIPAとは何ですか?
APIPA は、メイン DHCP サーバーにアクセスできない場合にデバイスに割り当てられる IP アドレスのセットです。
APIPA はどの IP 範囲を使用しますか?
APIPA は IP 範囲 169.254.0.1 ~ 169.254.255.254 を使用します。
コントロールプレーンとデータプレーン
「コントロール プレーン」とは何を指しますか?
コントロール プレーンは、パケットを別の場所にルーティングおよび転送する方法を決定するネットワークの一部です。
「データプレーン」とは何を指しますか?
データ プレーンは、実際にデータ/パケットを転送するネットワークの一部です。
「管理プレーン」とは何を指しますか?
監視および管理機能を指します。
ルーティング テーブルの作成はどのプレーン (データ、コントロールなど) に属しますか?
コントロールプレーン。
スパニング ツリー プロトコル (STP) について説明します。
リンクアグリゲーションとは何ですか?なぜ使われるのでしょうか?
非対称ルーティングとは何ですか?どうやって対処すればいいのでしょうか?
どのオーバーレイ (トンネル) プロトコルに精通していますか?
GREとは何ですか?どのように機能するのでしょうか?
VXLANとは何ですか?どのように機能するのでしょうか?
SNATとは何ですか?
OSPFについて説明します。
OSPF (Open Shortest Path First) は、さまざまな種類のルーターに実装できるルーティング プロトコルです。一般に、OSPF は、Cisco、Juniper、Huawei などのベンダーのルータを含む、ほとんどの最新ルータでサポートされています。このプロトコルは、IPv4 と IPv6 の両方を含む IP ベースのネットワークで動作するように設計されています。また、階層型ネットワーク設計も採用されており、ルーターがエリアにグループ化され、各エリアが独自のトポロジ マップとルーティング テーブルを持ちます。この設計は、ルーター間で交換する必要があるルーティング情報の量を削減し、ネットワークの拡張性を向上させるのに役立ちます。
OSPF 4 タイプのルーターは次のとおりです。
- 内部ルーター
- エリアボーダールーター
- 自律システム境界ルーター
- バックボーンルーター
OSPF ルーターの種類の詳細については、https://www.educba.com/ospf-router-types/ をご覧ください。
レイテンシーとは何ですか?
レイテンシは、情報が送信元から宛先に到達するまでにかかる時間です。
帯域幅とは何ですか?
帯域幅は、通信チャネルが特定の期間にどれだけのデータを処理できるかを測定するための通信チャネルの容量です。帯域幅が増えると、より多くのトラフィック処理が行われ、より多くのデータ転送が行われることになります。
スループットとは何ですか?
スループットとは、任意の伝送チャネルを通じて一定期間にわたって転送される実際のデータ量の測定値を指します。
検索クエリを実行するとき、レイテンシーとスループットのどちらがより重要ですか?そして、グローバルなインフラストラクチャを確実に管理するにはどうすればよいでしょうか?
待ち時間。待ち時間を長くするには、検索クエリを最も近いデータ センターに転送する必要があります。
ビデオをアップロードするとき、レイテンシーとスループットのどちらがより重要ですか?そしてそれをどうやって保証するのでしょうか?
スループット。良好なスループットを実現するには、アップロード ストリームを十分に活用されていないリンクにルーティングする必要があります。
リクエストを転送する際には、他にどのような考慮事項 (レイテンシーとスループットを除く) がありますか?
- キャッシュを最新の状態に保ちます (つまり、リクエストが最も近いデータセンターに転送されない可能性があります)
背骨と葉の説明
「スパイン & リーフ」は、複数のスイッチを接続し、ネットワーク トラフィックを効率的に管理するためにデータセンター環境で一般的に使用されるネットワーク トポロジです。これは、「スパイン-リーフ」アーキテクチャまたは「リーフ-スパイン」トポロジとしても知られています。この設計は、高帯域幅、低遅延、拡張性を提供し、大量のデータとトラフィックを処理する最新のデータセンターに最適です。 Spine & Leaf ネットワーク内には、スイッチの 2 つの主要なポリシーがあります。
- スパイン スイッチ: スパイン スイッチは、スパイン層に配置された高性能スイッチです。これらのスイッチはネットワークのコアとして機能し、通常は各リーフ スイッチと相互接続されます。各スパイン スイッチは、データ センター内のすべてのリーフ スイッチに接続されます。
- リーフ スイッチ: リーフ スイッチは、サーバー、ストレージ アレイ、その他のネットワーク機器などのエンド デバイスに接続されます。各リーフ スイッチは、データ センター内のすべてのスパイン スイッチに接続されます。これにより、リーフ スイッチとスパイン スイッチ間にノンブロッキングのフルメッシュ接続が確立され、どのリーフ スイッチも最大のスループットで他のリーフ スイッチと通信できるようになります。
Spine & Leaf アーキテクチャは、最新のクラウド コンピューティング、仮想化、ビッグ データ アプリケーションの要求に対応し、スケーラブルで高性能、信頼性の高いネットワーク インフラストラクチャを提供できるため、データ センターでの人気が高まっています。
ネットワークの輻輳とは何ですか?何が原因で起こるのでしょうか?
ネットワークの輻輳は、ネットワーク上で送信できるデータが多すぎて、需要を処理するのに十分な容量がない場合に発生します。
これにより、遅延が増加し、パケット損失が発生する可能性があります。原因は、ネットワーク使用率の高さ、大きなファイル転送、マルウェア、ハードウェアの問題、ネットワーク設計の問題など、複数である可能性があります。
ネットワークの輻輳を防ぐには、ネットワークの使用状況を監視し、需要を制限または管理する戦略を実装することが重要です。
UDP パケット形式について教えてください。 TCPパケットフォーマットはどうなるのでしょうか?どう違うのですか?
指数関数的バックオフ アルゴリズムとは何ですか?どこで使われていますか?
ハミング コードを使用すると、次のデータ ワード 100111010001101 のコード ワードは何になりますか?
00110011110100011101
アプリケーション層にあるプロトコルの例を挙げる
ハイパーテキスト転送プロトコル (HTTP) - インターネット上の Web ページに使用されます。- Simple Mail Transfer Protocol (SMTP) - 電子メール送信
- 電気通信ネットワーク - (TELNET) - クライアントが Telnet サーバーにアクセスできるようにする端末エミュレーション
- ファイル転送プロトコル (FTP) - 任意の 2 台のマシン間のファイル転送を容易にします。
- ドメイン ネーム システム (DNS) - ドメイン名の変換
- 動的ホスト構成プロトコル (DHCP) - IP アドレス、サブネット マスク、ゲートウェイをホストに割り当てます。
- Simple Network Management Protocol (SNMP) - ネットワーク上のデバイス上のデータを収集します。
ネットワーク層にあるプロトコルの例を挙げる
インターネット プロトコル (IP) - あるマシンから別のマシンへのパケットのルーティングを支援します。- インターネット コントロール メッセージ プロトコル (ICMP) - エラー メッセージやデバッグ情報など、何が起こっているかを知ることができます。
HSTSとは何ですか?
HTTP Strict Transport Security は、最初に送信されブラウザに返される応答ヘッダーを通じて接続の処理方法をユーザー エージェントと Web ブラウザに通知する Web サーバー ディレクティブです。これにより、HTTPS 暗号化を介した接続が強制され、HTTP を介してそのドメイン内のリソースをロードするスクリプトの呼び出しは無視されます。詳細は [こちら](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security) をご覧ください。 %20(HSTS、および%20バック%20から%20へ%20ブラウザ。)
ネットワーク - その他
インターネットとは何ですか?ワールドワイドウェブと同じでしょうか?
インターネットとは、世界中で膨大な量のデータを転送するネットワークのネットワークを指します。
World Wide Web は、インターネット上の何百万ものサーバー上で実行されるアプリケーションであり、いわゆる Web ブラウザーを通じてアクセスされます。
ISPとは何ですか?
ISP(インターネットサービスプロバイダー)は、地元のインターネット会社プロバイダーです。
オペレーティング·システム
オペレーティングシステムの演習
| 名前 | トピック | 目的と指示 | 解決 | コメント |
|---|
| フォーク101 | フォーク | リンク | リンク | |
| フォーク102 | フォーク | リンク | リンク | |
オペレーティングシステム - 自己評価
オペレーティングシステムとは何ですか?
本「オペレーティングシステム:3つの簡単なピース」から:
「プログラムを簡単に実行できるようにする責任があり(同時に多くの人を実行できるようにすることもできます)、プログラムがメモリを共有できるようにし、プログラムがデバイスと対話できるようにします。
オペレーティングシステム - プロセス
プロセスとは何かを説明できますか?
プロセスは実行中のプログラムです。プログラムは1つ以上の指示であり、プログラム(またはプロセス)はオペレーティングシステムによって実行されます。
オペレーティングシステムのプロセスのAPIを設計する必要がある場合、このAPIはどのように見えますか?
以下をサポートします。
作成 - 新しいプロセスを作成できます- 削除 - プロセスを削除/破壊します
- 状態 - プロセスの状態が実行されているか、停止し、待機しているかなどを確認してください。
- 停止 - 実行中のプロセスを停止します
プロセスはどのように作成されますか?
OSはプログラムのコードを読んでいます。- プログラムのコードは、メモリまたはより具体的には、プロセスのアドレス空間にロードされます。
- メモリは、プログラムのスタック(ランタイムスタック)に割り当てられます。 STACKは、argv、argc、main()へのパラメーターなどのデータを使用してOSによって初期化されました
- メモリは、データ構造リンクリストやハッシュテーブルなどの動的に割り当てられたデータに必要なプログラムのヒープに割り当てられます
- I/O初期化タスクは、各プロセスが3つのファイル記述子(入力、出力、エラー)のように、実行されます。
- OSはMain()から始まるプログラムを実行しています
本当か嘘か?メモリへのプログラムの読み込みは熱心に行われます(一度に)
間違い。過去には当てはまりましたが、今日のオペレーティングシステムは怠zyなロードを実行します。つまり、プロセスが実行されるのに必要な関連部のみが最初にロードされます。
プロセスのさまざまな状態は何ですか?
ランニング - 指示を実行しています- 準備ができました - 実行する準備ができていますが、さまざまな理由で保留中です
- ブロックされている - たとえばI/Oディスクリクエストなど、いくつかの操作が完了するのを待っています
プロセスがブロックされる理由は何ですか?
I/O操作(例:ディスクからの読み取り)- ネットワークからパケットを待っています
インタープロセス通信(IPC)とは何ですか?
インタープロセス通信(IPC)は、プロセスが共有データを管理できるようにするオペレーティングシステムによって提供されるメカニズムを指します。
「時間共有」とは何ですか?
1つの物理CPUを使用してシステムを使用する場合でも、複数のユーザーがプログラムに取り組んで実行できるようにすることができます。これは、コンピューティングリソースがユーザーに見える方法で共有される時間共有で可能です。システムには複数のCPUがありますが、実際にはマルチプログラミングとマルチタスクを適用することで共有されるCPUだけです。
「スペース共有」とは何ですか?
時間共有の逆です。時間内にリソースの共有はしばらくの間1つのエンティティによって使用され、その後、同じリソースを別のリソースで使用できます。スペースでは、スペースを共有することは複数のエンティティによって共有されますが、それらの間に転送されない方法で共有されます。
このエンティティがそれを取り除くことを決定するまで、1つのエンティティによって使用されます。たとえば、ストレージをご覧ください。ストレージでは、ファイルが自分のものであり、削除することにします。
特定の瞬間に実行されるプロセスを決定するコンポーネントは何ですか?
CPUスケジューラ
オペレーティングシステム - メモリ
「仮想メモリ」とは何ですか?また、どのような目的に役立ちますか?
仮想メモリは、コンピューターのRAMとハードディスクの一時的なスペースを組み合わせています。 RAMが低く実行されると、仮想メモリはデータをRAMからページングファイルと呼ばれるスペースに移動するのに役立ちます。データをページングファイルに移動すると、RAMが解放されるため、コンピューターは作業を完了できます。一般に、コンピューターのRAMが多いほど、プログラムの実行が速くなります。 https://www.minitool.com/lib/virtual-memory.html
デマンドページングとは何ですか?
需要ページングは、プロセスによってアクセスされた場合にのみ、ページが物理メモリにロードされるメモリ管理手法です。ページをオンデマンドで読み込んで、スタートアップの遅延とスペースのオーバーヘッドを削減することにより、メモリの使用量を最適化します。ただし、ページに初めてアクセスするときにレイテンシが導入されます。全体として、これはオペレーティングシステムでメモリリソースを管理するための費用対効果の高いアプローチです。
コピーオンワイトとは何ですか?
コピーオンワイト(COW)は、情報の不必要なコピーを減らすことを目標とするリソース管理の概念です。これは、たとえばPOSIXフォークSyscall内で実装される概念であり、呼び出しプロセスの重複プロセスを作成します。アイデア:
リソースが2つ以上のエンティティ(たとえば、2つのプロセス間の共有メモリセグメントなど)間で共有されている場合、リソースはすべてのエンティティにコピーする必要はありませんが、すべてのエンティティには共有リソースの読み取りオペレーションアクセス許可があります。 (共有セグメントは読み取り専用としてマークされています)(すべてのエンティティが共有リソースの場所へのポインターを持っていることを考えてください。- 1つのエンティティが共有リソースで書き込み操作を実行する場合、リソースもそれを共有する他のすべてのエンティティに対して永久に変更されるため、問題が発生します。 (スタック上のいくつかの変数を変更するプロセス、またはヒープにいくつかのデータを動的に割り当てるプロセスを考えてください。これらの共有リソースへのこれらの変更は、他のすべてのプロセスにも適用されます。これは間違いなく望ましくない動作です)
- ソリューションとしてのみ、共有リソースで書き込み操作を実行しようとしている場合、このリソースは最初にコピーされ、次に変更が適用されます。
カーネルとは何ですか、そしてそれは何をしますか?
カーネルはオペレーティングシステムの一部であり、次のようなタスクを担当しています。
メモリの割り当て- スケジュールプロセス
- CPUを制御します
本当か嘘か?カーネル内のコードの一部は、メモリの保護領域にロードされているため、アプリケーションが上書きできません。
真実
Posixとは何ですか?
POSIX(ポータブルオペレーティングシステムインターフェイス)は、UNIXのようなオペレーティングシステムとアプリケーションプログラムの間のインターフェイスを定義する一連の標準です。
セマフォとは何か、オペレーティングシステムにおけるその役割を説明してください。
セマフォは、共有リソースへのアクセスを制御するためのオペレーティングシステムと同時プログラミングで使用される同期プリミティブです。これは、複数のプロセスまたはスレッドでリソースへのアクセスを管理するためのカウンターまたはシグナル伝達メカニズムとして機能する変数または抽象データ型です。
キャッシュとは何ですか?バッファとは何ですか?
キャッシュ:通常、キャッシュは、プロセスがディスクに読み書きされているときに使用され、さまざまなプログラムで使用される同様のデータを簡単にアクセスできるようにすることで、プロセスを高速化します。バッファ:RAMの予約場所。一時的な目的でデータを保持するために使用されます。
仮想化
仮想化とは何ですか?
仮想化は、ソフトウェアを使用してコンピューターハードウェア上に抽象化レイヤーを作成するため、単一のコンピューター(メモリ、ストレージなど)のハードウェア要素を、一般的に仮想マシン(VM)と呼ばれる複数の仮想コンピューターに分割できます。
ハイパーバイザーとは何ですか?
Red Hat:「ハイパーバイザーは、仮想マシン(VM)を作成および実行するソフトウェアです。仮想マシンモニター(VMM)と呼ばれるハイパーバイザーは、仮想マシンからハイパーバイザーオペレーティングシステムとリソースを分離し、それらの作成と管理を可能にします。 VM。」
詳細はこちらをご覧ください
どんな種類のハイパーバイザーがありますか?
ホストされたハイパーバイザーとベアメタルハイパーバイザー。
ホストされたハイパーバイザー上のベアメタルハイパーバイザーの利点と短所は何ですか?
独自のドライバーとハードウェアコンポーネントに直接アクセスできるため、Baremetal Hypervisorは、安定性とスケーラビリティとともに、より良いパフォーマンスを持つことがよくあります。
一方、ロード(任意の)ドライバーに関するいくつかの制限がおそらくあるため、ホストされたハイパーバイザーは通常、ハードウェアの互換性を高めることで利益を得ます。
どのような種類の仮想化がありますか?
オペレーティングシステム仮想化ネットワーク機能仮想化デスクトップ仮想化
コンテナ化は仮想化の一種ですか?
はい、これは運用システムレベルの仮想化であり、カーネルが共有され、複数の分離ユーザースペースインスタンスを使用できるようにします。
仮想マシンの導入は、業界をどのように変え、アプリケーションの展開方法を変更しましたか?
仮想マシンの導入により、企業は同じハードウェアに複数のビジネスアプリケーションを展開することができましたが、各アプリケーションは、それぞれが独自のオペレーティングシステムで実行されている安全な方法で互いに分離されています。
仮想マシン
容器の時代に仮想マシンが必要ですか?それらはまだ関連していますか?
はい、仮想マシンは容器の時代でも関連性があります。コンテナは仮想マシンの軽量でポータブルな代替品を提供しますが、特定の制限があります。仮想マシンは、分離とセキュリティを提供し、異なるオペレーティングシステムを実行でき、レガシーアプリに適しているため、依然として重要です。たとえば、コンテナの制限はホストカーネルを共有しています。
プロメテウス
プロメテウスとは何ですか?プロメテウスの主な機能は何ですか?
Prometheusは、SoundCloudで元々開発された人気のあるオープンソースシステムの監視とアラートツールキットです。時系列データを収集および保存し、PROMQLと呼ばれる強力なクエリ言語を使用してそのデータのクエリと分析を可能にするように設計されています。プロメテウスは、クラウドネイティブアプリケーション、マイクロサービス、およびその他の最新のインフラストラクチャを監視するために頻繁に使用されます。
プロメテウスの主な機能には次のものがあります。
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
全体として、プロメテウスは、システムとアプリケーションを監視および分析するための強力で柔軟なツールであり、クラウドネイティブの監視と観察性のために業界で広く使用されています。
どのシナリオでは、プロメテウスを使用しない方が良いかもしれませんか?
Prometheusのドキュメントから:「リケストごとの請求など、100%の精度が必要な場合」。
プロメテウスの建築とコンポーネントを説明してください
プロメテウスアーキテクチャは、4つの主要なコンポーネントで構成されています。
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
全体として、プロメテウスアーキテクチャは、非常にスケーラブルで回復力があるように設計されています。サーバーとクライアントのライブラリは、大規模で非常に動的な環境全体の監視をサポートするために、分散型ファッションで展開できます。
PrometheusをInfluxDBなどの他のソリューションと比較できますか?
InfluxDBなどの他の監視ソリューションと比較して、Prometheusはその高性能とスケーラビリティで知られています。大量のデータを処理でき、監視エコシステムの他のツールと簡単に統合できます。一方、InfluxDBは、使いやすさとシンプルさで知られています。ユーザーフレンドリーなインターフェイスがあり、データを収集およびクエリするための使いやすいAPIを提供します。
もう1つの一般的なソリューションであるNagiosは、データを収集するためのプッシュベースのモデルに依存する、より伝統的な監視システムです。ナギオスは長い間存在しており、その安定性と信頼性で知られています。ただし、Prometheusと比較して、Nagiosには、多次元データモデルや強力なクエリ言語など、より高度な機能の一部が欠けています。
全体として、監視ソリューションの選択は、組織の特定のニーズと要件に依存します。 Prometheusは大規模な監視と警告に最適ですが、InfluxDBは、使いやすさとシンプルさを必要とする小さな環境に適している可能性があります。 Nagiosは、高度な機能よりも安定性と信頼性を優先する組織にとって依然として確かな選択肢です。
アラートとは何ですか?
プロメテウスでは、アラートは、特定の条件またはしきい値が満たされたときにトリガーされる通知です。アラートは、特定のメトリックが特定のしきい値を超えたり、特定のイベントが発生したときにトリガーするように構成できます。アラートがトリガーされると、電子メール、ポケットベル、チャットなどのさまざまなチャネルにルーティングして、関連するチームや個人に適切なアクションを実行するように通知できます。アラートは、チームがユーザーに影響を与えたり、システムのダウンタイムを引き起こす前に問題を積極的に検出したり応答したりできるため、監視システムの重要なコンポーネントです。インスタンスとは何ですか?仕事とは何ですか?
Prometheusでは、監視されている単一のターゲットを指します。たとえば、単一のサーバーまたはサービス。ジョブとは、同じアプリケーションを提供するWebサーバーのセットなど、同じ関数を実行する一連のインスタンスです。ジョブを使用すると、ターゲットのグループを一緒に定義および管理できます。
本質的に、インスタンスはプロメテウスがメトリックを収集する個別のターゲットですが、ジョブはグループとして管理できる同様のインスタンスのコレクションです。
プロメテウスがサポートするコアメトリックタイプは何ですか?
プロメテウスは、次のようないくつかのタイプのメトリックをサポートしています1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prometheusはまた、Sum、Max、Min、Rateなどのメトリックを集約および操作するためのさまざまな機能と演算子をサポートしています。これらの機能により、システムメトリックを監視および警告するための強力なツールになります。
輸出業者とは何ですか?何に使われますか?
輸出業者は、サードパーティのシステムまたはアプリケーションとプロメテウスの間の橋渡しとして機能し、プロメテウスがそのシステムまたはアプリケーションからデータを監視および収集することを可能にします。輸出業者はサーバーとして機能し、Prometheusからのリクエストのために特定のネットワークポートでメトリックをこすります。サードパーティのシステムまたはアプリケーションからメトリックを収集し、プロメテウスが理解できる形式に変換します。輸出国は、これらのメトリックをHTTPエンドポイントを介してプロメテウスに公開し、収集と分析に利用できるようにします。
輸出業者は、一般に、データベース、Webサーバー、ストレージシステムなどのさまざまなタイプのインフラストラクチャコンポーネントを監視するために使用されます。たとえば、MySQLやPostgreSQLなどの一般的なデータベースや、ApacheやNginxなどのWebサーバーを監視するために利用できる輸出業者がいます。
全体として、輸出業者はプロメテウスエコシステムの重要なコンポーネントであり、幅広いシステムとアプリケーションの監視を可能にし、プラットフォームに高度な柔軟性と拡張性を提供します。
どのプロメテウスのベストプラクティス?
そのうちの3つは次のとおりです1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
特定の期間に合計リクエストを取得する方法は?
Prometheusを使用して特定の期間に合計リクエストを取得するには、 * sum *関数と *レート *関数を使用できます。これは、最後の1時間の総リクエスト数を与える例の例ですsum(rate(http_requests_total[1h]))
このクエリでは、 HTTP_REQUESTS_TOTALは、HTTP要求の総数を追跡するメトリックの名前であり、レート関数は過去1時間の秒ごとの要求レートを計算します。合計関数は、すべてのリクエストを追加して、最後の1時間で総リクエスト数を提供します。
レート関数の期間を変更することにより、時間範囲を調整できます。たとえば、最終日にリクエストの総数を取得したい場合は、関数をレートに変更できます(http_requests_total [1d]) 。
プロメテウスの何を意味するのでしょうか?
HAは高可用性を表しています。これは、システムが非常に信頼性が高く、失敗やその他の問題に直面しても常に利用可能になるように設計されていることを意味します。実際には、これには通常、プロメテウスの複数のインスタンスを設定し、それらがすべて同期され、シームレスに協力できるようにすることが含まれます。これは、負荷分散、複製、フェイルオーバーメカニズムなど、さまざまな手法を通じて実現できます。 PrometheusにHAを実装することにより、ユーザーは、ハードウェアやソフトウェアの障害、ネットワークの問題、またはダウンタイムやデータの損失を引き起こす可能性のあるその他の問題に直面しても、監視データが常に利用可能で最新の状態であることを確認できます。
2つのメトリックにどのように参加しますか?
Prometheusでは、 * Join() *関数を使用して2つのメトリックを達成できます。 * join() *関数は、ラベル値に基づいて2つ以上の時系列を組み合わせます。 2つの必須の引数が必要です。 *on *および *table *。上の引数は、 * on *に参加するラベルを指定し、 *テーブル *引数は、参加する時系列を指定します。 Join()関数を使用して2つのメトリックに参加する方法の例を次に示します。
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
この例では、 Join()関数は、サービスとインスタンスのラベル値に基づいて、 request_count_totalとerror_count_totalの時系列を組み合わせます。 sum_series()関数は、結果の時系列の合計を計算します
ラベルの値を返すクエリを書く方法は?
Prometheusのラベルの値を返すクエリを書くには、 * label_values *関数を使用できます。 * label_values *関数は、ラベルの名前とメトリックの名前の2つの引数を取ります。たとえば、メソッドと呼ばれるラベルを備えたhttp_requests_totalというメトリックがあり、メソッドラベルのすべての値を返す場合は、次のクエリを使用できます。
label_values(http_requests_total, method)
これにより、 http_requests_totalメトリックのメソッドラベルのすべての値のリストが返されます。その後、このリストをさらにクエリで使用したり、データをフィルタリングしたりできます。
CPU_USER_SECONDSをパーセンテージでCPU使用に変換するにはどうすればよいですか?
* CPU_USER_SECONDS *をパーセンテージのCPU使用に変換するには、合計経過時間とCPUコアの数で除算する必要があります。次に100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
ここ、あなたがクエリしたい仕事の名前です、クエリしたい時間範囲( 5m 、 1h )、およびクエリするマシン上のCPUコアの数です。
たとえば、4つのCPUコアを備えたマシンで実行されているMy-Jobという名前のジョブの最後の5分間のCPU使用率を取得するには、次のクエリを使用できます。
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
行く
GOプログラミング言語の特徴は何ですか?
- 強力で静的なタイピング - 変数のタイプは時間の経過とともに変更することはできず、コンパイル時間で定義
- する
- 必要
- が
- あり
- ます
- 。
- 1つのバイナリにコンパイルされます。実行時のバージョン管理に非常に便利です。
また、良いコミュニティもあります。
var x int = 2とx := 2の違いは何ですか?
結果は同じで、値2の変数です。
var x int = 2では、 x := 2では変数タイプを整数に設定します。
本当か嘘か? Goでは変数を再除去でき、宣言したら使用する必要があります。
間違い。変数を再取得することはできませんが、はい、宣言された変数を使用する必要があります。
どのライブラリを使用しましたか?
これは使用法に基づいて回答する必要がありますが、いくつかの例は次のとおりです。
次のコードブロックの問題は何ですか?どうすれば修正できますか? func main() {
var x float32 = 13.5
var y int
y = x
}
次のコードブロックは、Integer 101を文字列に変換しようとしますが、代わりに「e」を取得します。何故ですか?どうすれば修正できますか? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Unicode値が101に設定されているものに見え、整数を文字列に変換するために使用します。 「101」を取得する場合は、パッケージ「strconv」を使用し、 y = string(x)をy = strconv.Itoa(x)に置き換える必要があります。
次のコードの何が問題になっていますか?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
GOの定数は、定数式を使用してのみ宣言できます。しかし、 x 、 yおよびそれらの合計は変動します。
const initializer x + y is not a constant
次のコードブロックの出力はどうなりますか?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
GoのIOTA識別子は、増分数の定義を簡素化するためにconst宣言で使用されます。表現で使用できるため、単純な列挙の一般性を超えて提供します。
xおよびy first iotaグループのz、2番目のz 。
Go WikiのIotaページ
_ goで何に使用されますか?
返品値のすべての変数を宣言する必要がありません。ブランク識別子と呼ばれます。
SOに答えてください
次のコードブロックの出力はどうなりますか?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
最初のIOTAは値3 ( + 3 )で宣言されているため、次のIOTAには値4があります
次のコードブロックの出力はどうなりますか?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
出力:2 1 3
同期/waitgroupについてのaritcle
Golangパッケージの同期
次のコードブロックの出力はどうなりますか?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
出力:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
mod1 aはリンクであり、 a[i]使用している場合、 s1値を変更します。ただし、 mod2では、 append新しいスライスを作成し、 s2ではなくaのみを変更します。
アレイに関するaritcle、 appendに関するブログ投稿
次のコードブロックの出力はどうなりますか?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
出力:3
Golang Container/Heapパッケージ
モンゴ
Mongodbの利点は何ですか?または、言い換えれば、なぜNOSQLの他の実装ではなくMongoDBを選択するのですか?
mongodbの利点は次のとおりです。
- スキーマレス
- 簡単にスケールアウトします
- 複雑な結合はありません
- 単一のオブジェクトの構造は明らかです
SQLとNOSQLの違いは何ですか?
主な違いは、SQLデータベースが構造化されていることです(データは、Excelスプレッドシートテーブルのように行と列のあるテーブルの形で保存されます)が、NOSQLは構造化されていないことであり、データストレージはNOSQL DBのセットアップ方法によって異なる場合があります。キー価値ペア、ドキュメント指向など
どのシナリオで、SQLを介してNOSQL/Mongoを使用したいと思いますか?
頻繁に変化する不均一なデータ- データの一貫性と整合性は最優先事項ではありません
- データベースが迅速にスケーリングする必要がある場合が最適です
ドキュメントとは何ですか?コレクションとは何ですか?
ドキュメントはMongoDBのレコードであり、BSON(Binary JSON)形式に保存され、MongoDBのデータの基本単位です。- コレクションは、Mongodbの単一のデータベースに保存されている関連ドキュメントのグループです。
アグリゲーターとは何ですか?
- アグリゲーターは、MongoDBのフレームワークであり、データセットで操作を実行して、単一の計算結果を返します。
何が良いですか?埋め込まれたドキュメントまたは参照?
- 優れた決定的な答えはありません。特定のユースケースと要件に依存します。いくつかの説明:埋め込まれたドキュメントはアトミックアップデートを提供しますが、参照されたドキュメントにより、より良い正規化が可能になります。
Mongoでデータ検索の最適化を実行しましたか?そうでない場合は、遅いデータ取得を最適化する方法について考えることができますか?
- MongoDBのデータ検索を最適化するいくつかの方法は、インデックス作成、適切なスキーマ設計、クエリ最適化、データベースの負荷分散です。
クエリ
このクエリを説明する: db.books.find({"name": /abc/})
このクエリを説明してください: db.books.find().sort({x:1})
find()とfind_one()の違いは何ですか?
find()クエリ条件に一致するすべてのドキュメントを返します。- find_one()は、クエリ条件に一致するドキュメント(または一致しない場合はnull)のみを返します。
Mongo DBからデータをエクスポートするにはどうすればよいですか?
SQL
SQLエクササイズ
| 名前 | トピック | 目的と指示 | 解決 | コメント |
|---|
| 関数対比較 | クエリの改善 | エクササイズ | 解決 | |
SQL自己評価
SQLとは何ですか?
SQL(Structured Query Language)は、リレーショナルデータベース(MySQL、Mariadbなど)の標準言語です。
リレーショナルデータベースでデータの読み取り、更新、削除、作成に使用されます。
SQLはNOSQLとどのように違いますか
主な違いは、SQLデータベースが構造化されていることです(データは、Excelスプレッドシートテーブルのように行と列のあるテーブルの形で保存されます)が、NOSQLは構造化されていないことであり、データストレージはNOSQL DBのセットアップ方法によって異なる場合があります。キー価値ペア、ドキュメント指向など
SQLを使用するのがいつ最善ですか? nosql?
SQL-データの整合性が非常に重要な場合に使用するのが最適です。 SQLは通常、酸のコンプライアンスのため、多くの企業や金融分野内の分野で実装されます。
NOSQL-迅速にスケーリングする必要がある場合は素晴らしい。 NOSQLはWebアプリケーションを念頭に置いて設計されているため、同じ情報を複数のサーバーにすばやく広める必要がある場合に最適です。
さらに、NOSQLは、リレーショナルデータベースが必要とする列と行構造を備えた厳格なテーブルに付着していないため、異なるデータ型を一緒に保存できます。
実用的なSQL-基本
これらの質問では、以下に示す顧客と注文表を使用します。
お客様
| customer_id | customer_name | items_in_cart | cash_spent_to_date |
|---|
| 100204 | ジョン・スミス | 0 | 20.00 |
| 100205 | ジェーン・スミス | 3 | 40.00 |
| 100206 | ボビー・フランク | 1 | 100.20 |
注文
| customer_id | order_id | アイテム | 価格 | date_sold |
|---|
| 100206 | A123 | ラバーダッキー | 2.20 | 2019-09-18 |
| 100206 | A123 | バブルバス | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80パックTP | 90.00 | 2019-09-20 |
| 100205 | Z001 | キャットフード - マグロの魚 | 10.00 | 2019-08-05 |
| 100205 | Z001 | キャットフード - チキン | 10.00 | 2019-08-05 |
| 100205 | Z001 | キャットフード - 牛肉 | 10.00 | 2019-08-05 |
| 100205 | Z001 | キャットフード - キティケサディーラ | 10.00 | 2019-08-05 |
| 100204 | X202 | コーヒー | 20.00 | 2019-04-29 |
このテーブルからすべてのフィールドを選択するにはどうすればよいですか?
select *
顧客から;
ジョンのカートにはいくつのアイテムがありますか?
items_in_cartを選択します
顧客から
customer_name = "John Smith";
すべての顧客に費やされたすべての現金の合計はいくらですか?
sum_cashとしてsum(cash_spent_to_date)を選択します
顧客から;
カートにアイテムを持っている人は何人いますか?
number_of_people_w_itemsとしてcount(1)を選択します
顧客から
ここでitems_in_cart> 0;
顧客テーブルを注文テーブルにどのように参加しますか?
ユニークなキーに参加します。この場合、一意のキーは顧客テーブルと注文テーブルの両方のcustomer_idです
どの顧客がどのアイテムを注文したかをどのように示しますか?
c.customer_name、o.itemを選択します
顧客からc
左結合注文o
c.customer_id = o.customer_id;
声明を使用して、キャットフードを注文した人と費やした金額の総額をどのように示しますか?
cat_foodをas(
customer_id、合計(価格)をtotal_priceとして選択します
注文から
「%キャットフード%」のようなアイテム
customer_idによるグループ
)
customer_name、total_priceを選択します
顧客からc
内側の結合cat_food f
c.customer_id = f.customer_id
ここで、c.customer_id in(cat_foodからcustomer_idを選択してください);
これは単純な声明でしたが、「with with」節は、別の人に結合する前に複雑なクエリをテーブルで実行する必要があるときに本当に輝いています。まったく新しいテーブルを作成するのではなく、クエリを実行するときに擬似温度を作成するため、ステートメント付きは素晴らしいです。
キャットフードのすべての購入の合計は容易に入手できなかったため、ステートメントを使用して擬似テーブルを作成して、各顧客が費やした価格の合計を取得し、通常はテーブルに参加しました。
次のクエリのどれを使用しますか? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
関数( YEAR(purchased_at) )を使用する場合、インデックスと基本的に列をその自然状態で使用するのではなく、データベース全体をスキャンする必要があります。
OpenStack
OpenStackのどのコンポーネント/プロジェクトがよく知っていますか?
次のサービス/プロジェクトのそれぞれが責任を負っていることを教えてください。:
Nova-仮想インスタンスを管理します- 中性子 - ネットワークをサービスとして提供してネットワーキングを管理する(NAAS)
- CINDER-ブロックストレージ
- 視線 - 仮想マシンとコンテナの画像を管理する(検索、取得、登録)
- Keystone-クラウド全体の認証サービス
以下のそれぞれに使用されるサービス/プロジェクトを特定します。- インスタンスをコピーまたはスナップショットします
- リソースを表示および変更するためのGUI
- ブロックストレージ
- 仮想インスタンスを管理します
視線 - 画像サービス。また、インスタンスのコピーまたはスナップショットに使用されます- Horizon-リソースを表示および変更するためのGUI
- CINDER-ブロックストレージ
- Nova-仮想インスタンスを管理します
テナント/プロジェクトとは何ですか?
真または偽を決定する:- OpenStackは無料で使用できます
- ネットワーキングを担当するサービスは一目です
- テナント/プロジェクトの目的は、異なるプロジェクトとOpenStackのユーザー間でリソースを共有することです
フローティングIPでインスタンスをどのように表示するかを詳細に説明してください
顧客から「インスタンスをpingすることはできますが、接続できません(SSH)」と言っています。何が問題なのでしょうか?
OpenStackがサポートするネットワークの種類は何ですか?
OpenStackストレージの問題をどのようにデバッグしますか? (ツール、ログ、...)
OpenStackの計算の問題をどのようにデバッグしますか? (ツール、ログ、...)
OpenStack Deployment&Tripleo
過去にOpenStackを展開しましたか?はいの場合、どのようにしたか説明できますか?
Tripleoに精通していますか? DevStackやPackStackとどう違うのですか?
トリプルーについてここで読むことができます
OpenStack Compute
Novaを詳細に説明できますか?
仮想インスタンスのプロビジョニングと管理に使用されます- ロギング、エンドユーザーコントロール、監査など、さまざまなレベルのマルチテナントをサポートします。
- 高度にスケーラブル
- 認証は、内部システムまたはLDAPを使用して実行できます
- 複数の種類のブロックストレージをサポートします
- ハードウェアとハイパーバイザーアグノーチスになろうとします
Novaアーキテクチャとコンポーネントについて何を知っていますか?
nova -api-メタデータを提供してAPIを計算するサーバー- さまざまなNOVAコンポーネントは、キュー(通常はrabbitmq)とデータベースを使用して通信します
- インスタンスを作成するためのリクエストは、インスタンスがどこに作成されて実行されるかを決定するNova-Schedulerによって検査されます
- Nova-Computeは、インスタンスを作成し、ライフサイクルを管理するためにハイパーバイザーと通信する責任のあるコンポーネントです
OpenStackネットワーキング(中性子)
中性子を詳細に説明します
OpenStackのコアコンポーネントとスタンドアロンプロジェクトの1つ- Neutronは、ネットワーキングをサービスとして提供することに焦点を合わせました
- Neutronを使用すると、ユーザーはクラウドにネットワークをセットアップし、さまざまなネットワークサービスを構成および管理できます
- Neutronは対話します:
- Nova -NovaはNICSをネットワークに接続するために中性子と通信します
- Horizon-ダッシュボード内のネットワーキングエンティティをサポートし、ネットワーキングの詳細を含むトポロジビューも提供します
次の各コンポーネントを説明します。- 中性子-DHCP-Agent
- 中性子-l3エージェント
- 中性子メタリングエージェント
- 中性子 - * - agtent
- 中性子サーバー
Neutron-L3-Agent-L3/NAT転送(たとえば、VMSに外部ネットワークアクセスを提供)- Neutron-DHCP-Agent-DHCPサービス
- Neutron-Metering-Agent-L3トラフィックメーター
- 中性子 - * - agtent-各計算でローカルvswitch構成を管理する(選択したプラグインに基づく)
- Neutron -Server-ネットワーキングAPIを公開し、必要に応じて他のプラグインにリクエストをパスします
これらのネットワークタイプを説明します:- 管理ネットワーク
- ゲストネットワーク
- APIネットワーク
- 外部ネットワーク
管理ネットワーク - OpenStackコンポーネント間の内部通信に使用されます。このネットワークのIPアドレスは、データセットナー内でのみアクセスできます- ゲストネットワーク - インスタンス/VM間の通信に使用されます
- APIネットワーク - サービスAPI通信に使用されます。このネットワーク内のIPアドレスは、公開されています
- 外部ネットワーク - パブリックコミュニケーションに使用されます。このネットワークのIPアドレスは、インターネット上の誰でもアクセスできます
次のエンティティを削除する必要があります。
それには多くの理由があります。たとえば、アクティブなポートが割り当てられている場合、ルーターを取り外すことはできません。
プロバイダーネットワークとは何ですか?
L2およびL3にはどのようなコンポーネントとサービスが存在しますか?
ML2プラグインとは何ですか?そのアーキテクチャを説明してください
L2エージェントとは何ですか?それはどのように機能し、何に責任がありますか?
L3エージェントとは何ですか?それはどのように機能し、何に責任がありますか?
Explain what the Metadata agent is responsible for
What networking entities Neutron supports?
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
本当か嘘か? there can be two objects with the same name in the same container but not in two different containers
間違い。 Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- 役割
- Tenant/Project
- サービス
- 終点
- トークン
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
Using:
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- 迅速
- サハラ
- 皮肉な
- トローブ
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- パム
- Memcached
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
人形
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
弾性のある
What is the Elastic Stack?
The Elastic Stack consists of:
- Elasticsearch
- キバナ
- ログスタッシュ
- ビート
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Elasticsearch
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red.それはどういう意味ですか? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
本当か嘘か? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
間違い。 From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot".それはどういう意味ですか?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? What would you use it for?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
ログスタッシュ
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
キバナ
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits".それはどういう意味ですか?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Read here
本当か嘘か? a single harvester harvest multiple files, according to the limits set in filebeat.yml
間違い。 One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Elastic Stack
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Distributed
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
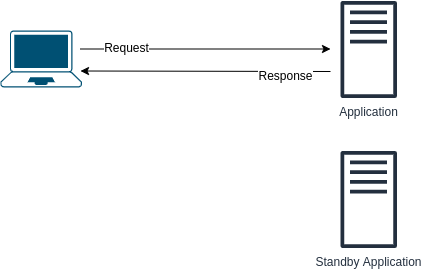
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
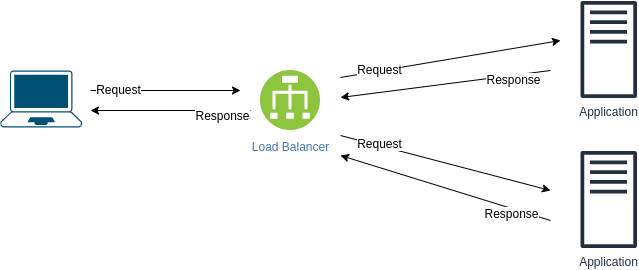
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage 、 メモリ、 ...)。
Explain the Sidecar Pattern (Or sidecar proxy)
Misc
| 名前 | トピック | Objective & Instructions | 解決 | コメント |
|---|
| Highly Available "Hello World" | エクササイズ | 解決 | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
本当か嘘か? API Definition is the same as API Specification
間違い。 From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
利点:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
認可- ロギング
- 認証
- Ordering
- フロントエンド
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use?なぜ?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
本当か嘘か? Any valid JSON file is also a valid YAML file
真実。 Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
ファームウェア
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
カサンドラ
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
本当か嘘か? HTTP is stateful
間違い。 It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server.それはどういう意味ですか?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Round Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
短所:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Cookies. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
ライセンス
Are you familiar with "Creative Commons"?それについて何を知っていますか?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
ランダム
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache.ソース
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
ストレージ
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
長所:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
長所:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
テスト
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
正規表現
Given a text file, perform the following exercises
抽出する
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
交換する
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Scalability
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
キャッシュ
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
ここを見てください
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

ハードウェア
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
外部の- Machine check
- I/O
- プログラム
- 再起動
- Supervisor call (SVC)
ビッグデータ
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers.本当か嘘か? Ceph favor consistency and correctness over performances
真実Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
モニター- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- マネージャー
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server?仕組みは?
Packer
What is Packer?何に使われますか?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
リリース
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
証明書
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam.幸運を :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
アズール
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




クレジット
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
ライセンス


