textgenrnn
T
数行のコードを使用して、テキスト データセット上で任意のサイズと複雑さの独自のテキスト生成ニューラル ネットワークを簡単にトレーニングしたり、事前トレーニングされたモデルを使用してテキストをすばやくトレーニングしたりできます。
textgenrnn は、char-rnn を作成するための Keras/TensorFlow 上の Python 3 モジュールであり、多くの優れた機能を備えています。
この Colaboratory Notebook では、textgenrnn で遊んだり、GPU を使用してテキスト ファイルを無料でトレーニングしたりできます。詳細については、このブログ投稿を読むか、このビデオをご覧ください。
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
含まれているモデルは、新しいテキストで簡単にトレーニングでき、入力データを 1 回パスした後でも適切なテキストを生成できます。
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
モデルの重みは比較的小さく (ディスク上で 2 MB)、簡単に保存して新しい textgenrnn インスタンスにロードできます。その結果、データを介して何百ものパスでトレーニングされたモデルを操作できます。 (実際、textgenrnn は非常によく学習するため、クリエイティブな出力を行うには温度を大幅に上げる必要があります。)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
new_model=True任意のトレーニング関数に追加することで、ワード レベルの埋め込みと双方向 RNN 層をサポートして、新しいモデルをトレーニングすることもできます。
出力がどのように展開されるかに段階的に関与することも可能です。インタラクティブ モードでは、次の文字/単語の上位 N個のオプションが提案され、1 つを選択できます。
ターミナルで textgenrnn を実行するときは、 interactive=Trueとtop=Nを渡して をgenerateます。 N のデフォルトは 3 です。
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
これにより、出力に人間味を加えることができます。あなたが作家になったような気分です! (参照)
textgenrnn はpip経由で pypi からインストールできます。
pip3 install textgenrnn最新の textgenrnn の場合は、 TensorFlow バージョン 2.1.0 以降が必要です。
この Jupyter Notebook では、一般的な機能とモデル構成オプションのデモを表示できます。
/datasets textgenrnn のトレーニングに Hacker News/Reddit データを使用したサンプル データセットが含まれています。
/weights textgenrnn にロードできる前述のデータセットでさらに事前トレーニングされたモデルが含まれています。
/outputs上記の事前トレーニング済みモデルから生成されたテキストの例が含まれています。
textgenrnn は、Andrej Karpathy による char-rnn プロジェクトに基づいており、非常に小さなテキスト シーケンスを処理する機能など、いくつかの最新の最適化が施されています。
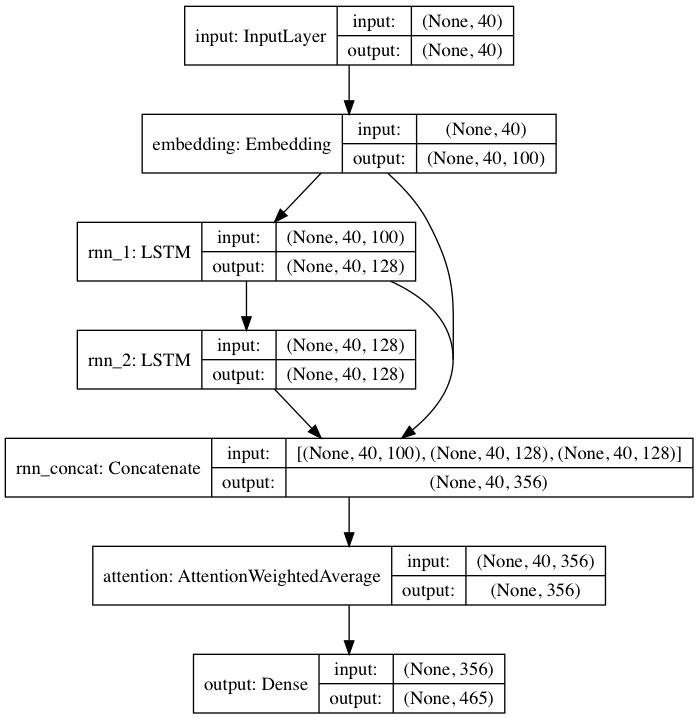
含まれている事前トレーニング済みモデルは、DeepMoji からインスピレーションを得たニューラル ネットワーク アーキテクチャに従っています。デフォルト モデルの場合、textgenrnn は最大 40 文字の入力を受け取り、各文字を 100 次元の文字埋め込みベクトルに変換し、それらを 128 セルの長期短期メモリ (LSTM) 再帰層に供給します。これらの出力は、別の128 セル LSTM に供給されます。次に、3 つのレイヤーすべてがアテンション レイヤーに入力され、最も重要な時間的特徴に重み付けが行われ、それらが一緒に平均化されます (エンベディング + 1 番目の LSTM がアテンション レイヤーにスキップ接続されているため、モデルの更新がより簡単にそれらに逆伝播され、消失を防ぐことができます)グラデーション)。その出力は、大文字、小文字、句読点、絵文字を含む、最大 394 個の異なる文字がシーケンス内の次の文字である確率にマッピングされます。 (新しいデータセットで新しいモデルをトレーニングする場合、上記のすべての数値パラメーターを構成できます)
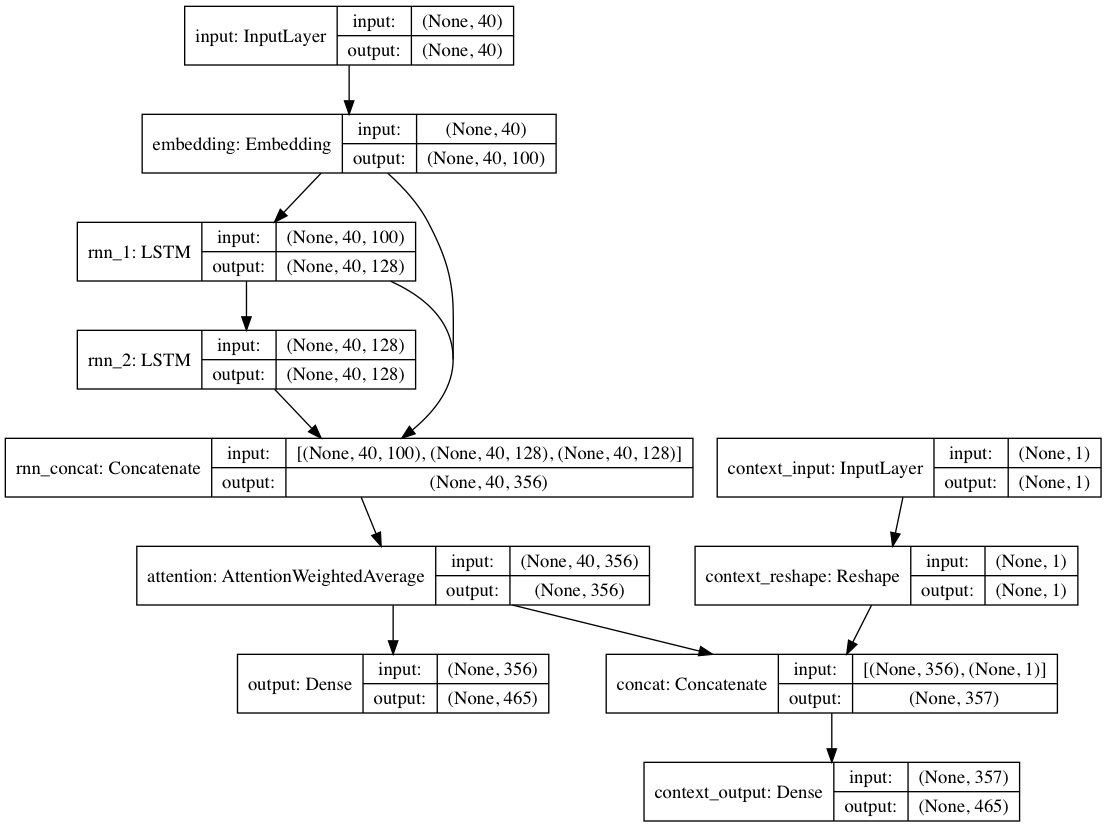
あるいは、各テキスト ドキュメントにコンテキスト ラベルが提供されている場合、モデルをコンテキスト モードでトレーニングすることもできます。このモードでは、モデルがコンテキストを与えられたテキストを学習するため、リカレント レイヤーは非コンテキスト化された言語を学習します。テキストのみのパスは、非文脈化されたレイヤーに便乗できます。全体として、これにより、テキストだけでモデルをトレーニングするよりもはるかに高速なトレーニングと、量的および定性的なモデルのパフォーマンスが向上します。
パッケージに含まれるモデルの重みは、非常に多様なサブレディットからの Reddit の投稿 (BigQuery 経由) からの数十万のテキスト ドキュメントでトレーニングされています。ネットワークは、トレーニング パフォーマンスの向上と著者によるバイアスの軽減の両方を目的として、上記の脱文脈アプローチを使用してトレーニングも行われました。
textgenrnn を使用してテキストの新しいデータセットでモデルを微調整すると、すべてのレイヤーが再トレーニングされます。ただし、元の事前トレーニング済みネットワークは最初はより堅牢な「知識」を持っているため、新しい textgenrnn は最終的にはより高速かつ正確にトレーニングし、元のデータセットには存在しない新しい関係を学習できる可能性があります (たとえば、事前トレーニング済みの文字埋め込みにはコンテキストが含まれています)現代のインターネット文法で考えられるすべてのタイプの文字)。
さらに、再トレーニングは運動量ベースのオプティマイザーと線形に減衰する学習率を使用して行われ、どちらも勾配の爆発を防ぎ、長時間のトレーニング後にモデルが発散する可能性を大幅に低くします。
高度にトレーニングされたニューラル ネットワークを使用したとしても、 100% の確率で高品質のテキストが生成されるわけではありません。これが、NN テキスト生成を利用したバイラルなブログ投稿や Twitter のツイートが多くの場合、大量のテキストを生成し、後で最適なものを厳選/編集する主な理由です。
結果はデータセット間で大きく異なります。事前学習済みのニューラル ネットワークは比較的小さいため、RNN が通常ブログ投稿で誇示しているほど多くのデータを保存できません。最良の結果を得るには、少なくとも 2,000 ~ 5,000 のドキュメントを含むデータセットを使用します。データセットが小さい場合は、トレーニング メソッドを呼び出すときや新しいモデルを最初からトレーニングするときにnum_epochs高く設定して、より長時間トレーニングする必要があります。それでも、現時点では「適切な」モデルを決定するための適切なヒューリスティックはありません。
textgenrnn を再トレーニングするのに GPU は必要ありませんが、CPU でトレーニングするとはるかに時間がかかります。 GPU を使用する場合は、ハードウェアの使用率を向上させるために、 batch_sizeパラメーターを増やすことをお勧めします。
より正式な文書化
tensorflow.js を使用した Web ベースの実装 (ネットワークのサイズが小さいため、特にうまく機能します)
アテンション層の出力を視覚化し、ネットワークがどのように「学習」するかを確認する方法。
モデル アーキテクチャをチャットボットの会話に使用できるようにするモード (別のプロジェクトとしてリリースされる可能性があります)
コンテキストに対するさらなる深さ (位置コンテキスト + 複数のコンテキスト ラベルの許可)
より長い文字シーケンスと言語のより深い理解に対応できる大規模な事前トレーニング済みネットワークにより、より適切に生成された文章を作成できます。
ワードレベル モデルの階層的ソフトマックス アクティベーション (Keras が適切にサポートすると)。
Volta/TPU での超高速トレーニング用の FP16 (Keras が適切にサポートされたら)。
マックス・ウルフ (@minimaxir)
Max のオープンソース プロジェクトは彼の Patreon によってサポートされています。このプロジェクトが役立つと思われた場合は、Patreon への金銭的な寄付は高く評価され、創造的に有効に活用されます。
Andrej Karpathy は、ブログ投稿「リカレント ニューラル ネットワークの不合理な効果」を通じて char-rnn の最初の提案に貢献してくれました。
Daniel Grijalva 氏、インタラクティブ モードに貢献してくれました。
マサチューセッツ工科大学
DeepMoji から使用されるアテンション層コード (MIT ライセンス)


