Python 外れ値検出 (PyOD)
導入、ドキュメント、統計、ライセンス

最初にお読みください
PyOD へようこそ。これは、多変量データの異常を検出するための包括的でありながら使いやすい Python ライブラリです。小規模プロジェクトに取り組む場合でも、大規模なデータセットに取り組む場合でも、PyOD はニーズに合わせたさまざまなアルゴリズムを提供します。
- 時系列の外れ値検出にはTODS をご利用ください。
- グラフの外れ値検出にはPyGODをご利用ください。
- パフォーマンスの比較とデータセット: 45 ページの包括的な異常検出ベンチマーク ペーパーがあります。完全にオープンソースの ADBench は、57 のベンチマーク データセットで 30 の異常検出アルゴリズムを比較します。
- 異常検出の詳細については、異常検出リソースをご覧ください。
- 分散システム上の PyOD : データブリック上で PyOD を実行することもできます。
PyODについて
2017 年に確立された PyOD は、多変量データ内の異常/外れオブジェクトを検出するための頼りになるPython ライブラリになりました。この刺激的でありながら挑戦的な分野は、一般に外れ値検出または異常検出と呼ばれます。
PyOD には、古典的な LOF (SIGMOD 2000) から最先端の ECOD および DIF (TKDE 2022 および 2023) まで、50 を超える検出アルゴリズムが含まれています。 2017 年以来、PyOD は数多くの学術研究プロジェクトや商用製品で使用され、2,200 万件以上ダウンロードされ、成功を収めてきました。また、Analytics Vidhya、KDnuggets、Towards Data Science などのさまざまな専用の投稿/チュートリアルにより、機械学習コミュニティでもよく認められています。
PyOD の特徴は次のとおりです。
- さまざまなアルゴリズムにわたる統一されたユーザーフレンドリーなインターフェイス。
- PyTorchの古典的な手法から最新の深層学習手法まで、幅広いモデル。
- 高いパフォーマンスと効率。JIT コンパイルと並列処理に numba と joblib を活用します。
- 高速トレーニングと予測、SUOD フレームワークを通じて実現 [50]。
5 行のコードによる外れ値の検出:
# Example: Training an ECOD detector
from pyod . models . ecod import ECOD
clf = ECOD ()
clf . fit ( X_train )
y_train_scores = clf . decision_scores_ # Outlier scores for training data
y_test_scores = clf . decision_function ( X_test ) # Outlier scores for test data
適切なアルゴリズムの選択:どこから始めればよいかわかりませんか?次の堅牢で解釈可能なオプションを検討してください。
- ECOD: 外れ値検出に ECOD を使用する例
- Isolation Forest: 外れ値の検出に Isolation Forest を使用する例
あるいは、データ駆動型のアプローチとして MetaOD を検討してください。
PyODを引用:
PyOD の論文は Journal of Machine Learning Research (JMLR) (MLOSS トラック) に掲載されています。科学出版物で PyOD を使用する場合は、次の論文を引用していただければ幸いです。
@article{zhao2019pyod,
著者 = {Zhao、Yue、Nasrullah、Zain、Li、Zheng}、
title = {PyOD: スケーラブルな外れ値検出のための Python ツールボックス},
ジャーナル = {機械学習研究ジャーナル}、
年 = {2019}、
ボリューム = {20}、
番号 = {96}、
ページ = {1-7}、
URL = {http://jmlr.org/papers/v20/19-011.html}
}
または:
Zhao, Y.、Nasrullah, Z.、Li, Z.、2019 年。PyOD: スケーラブルな外れ値検出のための Python ツールボックス。機械学習研究ジャーナル (JMLR)、20(96)、1-7 ページ。
異常検出に関するより広い視点については、NeurIPS の論文「ADBench: Anomaly Detection Benchmark Paper」および「ADGym: Design Choices for Deep Anomaly Detection」を参照してください。
@article{han2022adbench,
title={Adbench: 異常検出ベンチマーク},
author={ハン、ソンチャオと胡、西陽と黄、海良と江、ミンチーと趙、越}、
Journal={神経情報処理システムの進歩},
ボリューム={35}、
ページ={32142--32159}、
年={2022}
}
@article{jiang2023adgym、
title={ADGym: 深い異常検出のための設計の選択},
author={江、民斉と侯、朝川と鄭、蒼と漢、松橋と黄、海良と温、青松と胡、西陽と趙、岳}、
Journal={神経情報処理システムの進歩},
ボリューム={36}、
年={2023}
}
目次:
- インストール
- API チートシートとリファレンス
- ADBench ベンチマークとデータセット
- モデルの保存とロード
- SUOD による高速列車
- 異常値スコアのしきい値
- 実装されたアルゴリズム
- 外れ値検出のクイックスタート
- 貢献方法
- 包含基準
インストール
PyOD は、 pipまたはconda を使用して簡単にインストールできるように設計されています。更新と機能強化が頻繁に行われるため、PyOD の最新バージョンを使用することをお勧めします。
pip install pyod # normal install
pip install --upgrade pyod # or update if needed
conda install -c conda-forge pyod
あるいは、setup.py ファイルのクローンを作成して実行することもできます。
git clone https://github.com/yzhao062/pyod.git
cd pyod
pip install .
必要な依存関係:
- Python 3.8以降
- ジョブリブ
- マットプロットライブラリ
- numpy>=1.19
- 数値>=0.51
- scipy>=1.5.1
- scikit_learn>=0.22.0
オプションの依存関係 (詳細は以下を参照) :
- combo (オプション、models/combination.py および FeatureBagging には必須)
- pytorch (オプション、AutoEncoder およびその他の深層学習モデルに必要)
- suod (オプション、SUOD モデルの実行に必要)
- xgboost (オプション、XGBOD には必須)
- pythresh (オプション、しきい値処理に必要)
API チートシートとリファレンス
完全な API リファレンスは PyOD ドキュメントで入手できます。以下は、すべての検出器の簡単なチートシートです。
- fit(X) : 検出器をフィットさせます。パラメータ y は教師なしメソッドでは無視されます。
- Decision_function(X) : 適合した検出器を使用して、X の生の異常スコアを予測します。
- detect(X) : 近似検出器を使用して、サンプルが外れ値であるかどうかをバイナリ ラベルとして判断します。
- detect_proba(X) : 近似された検出器を使用して、サンプルが外れ値である確率を推定します。
- detect_confidence(X) : サンプルごとにモデルの信頼度を評価します (predict および detect_proba に適用可能) [35]。
適合モデルの主な属性:
- Decision_scores_ : トレーニング データの異常値スコア。通常、スコアが高いほど、異常な動作が多いことを示します。通常、外れ値のスコアは高くなります。
- label_ : トレーニング データのバイナリ ラベル。0 は内部値を示し、1 は外れ値/異常を示します。
ADBench ベンチマークとデータセット
私たちは、45 ページの最も包括的な ADBench: Anomaly Detection Benchmark [15] をリリースしました。完全にオープンソースの ADBench は、57 のベンチマーク データセットで 30 の異常検出アルゴリズムを比較します。
ADBenchの構成は次のとおりです。

より簡単に視覚化するために、compare_all_models.py を介して選択したモデルを比較します。
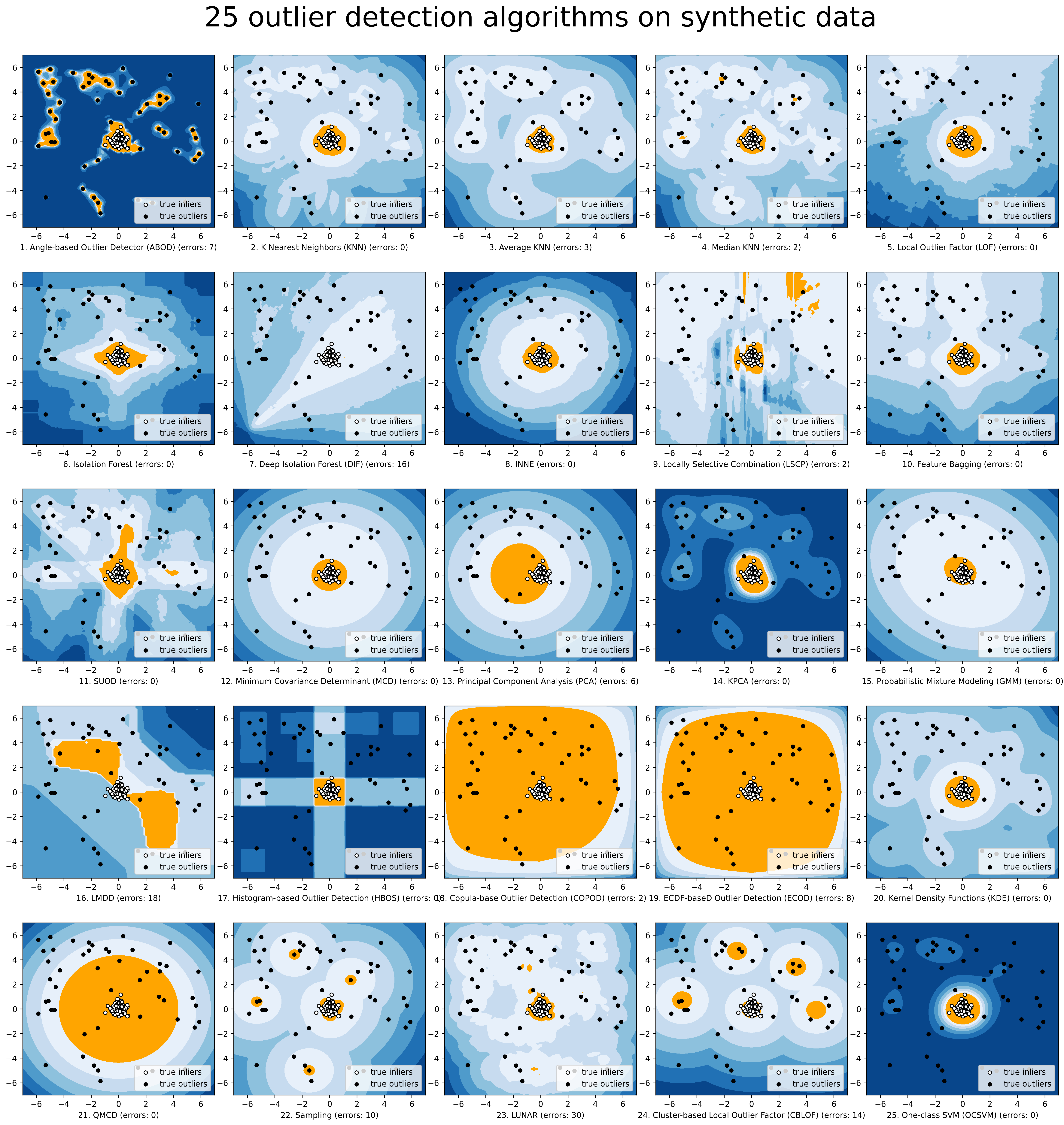
モデルの保存とロード
PyOD は、モデルの永続性に関して sklearn と同様のアプローチを採用しています。詳細については、「モデルの永続性」を参照してください。
つまり、PyOD モデルの保存と読み込みには joblib または pickle を使用することをお勧めします。例については、「examples/save_load_model_example.py」を参照してください。簡単に言うと以下のように簡単です。
from joblib import dump , load
# save the model
dump ( clf , 'clf.joblib' )
# load the model
clf = load ( 'clf.joblib' )
ニューラル ネットワーク モデルの保存には課題があることが知られています。一時的な回避策については、#328 と #88 を確認してください。
SUOD による高速列車
高速トレーニングと予測: SUOD フレームワーク [50] を活用することで、PyOD の多数の検出モデルを使用してトレーニングと予測を行うことが可能です。 SUOD ペーパーと SUOD の例を参照してください。
from pyod . models . suod import SUOD
# initialized a group of outlier detectors for acceleration
detector_list = [ LOF ( n_neighbors = 15 ), LOF ( n_neighbors = 20 ),
LOF ( n_neighbors = 25 ), LOF ( n_neighbors = 35 ),
COPOD (), IForest ( n_estimators = 100 ),
IForest ( n_estimators = 200 )]
# decide the number of parallel process, and the combination method
# then clf can be used as any outlier detection model
clf = SUOD ( base_estimators = detector_list , n_jobs = 2 , combination = 'average' ,
verbose = False )
異常値スコアのしきい値
汚染レベルを設定する際には、よりデータに基づいたアプローチを採用できます。しきい値処理方法を使用すると、任意の値の推測を、内値と外れ値を分離するためのテスト済みの手法に置き換えることができます。しきい値処理の詳細については、PyThresh を参照してください。
from pyod . models . knn import KNN
from pyod . models . thresholds import FILTER
# Set the outlier detection and thresholding methods
clf = KNN ( contamination = FILTER ())
しきい値処理でサポートされているしきい値処理方法を参照してください。
実装されたアルゴリズム
PyOD ツールキットは 4 つの主要な機能グループで構成されます。
(i) 個別の検出アルゴリズム:
| タイプ | 略称 | アルゴリズム | 年 | 参照 |
|---|
| 確率的 | エコッド | 経験的累積分布関数を使用した教師なし外れ値の検出 | 2022年 | [28] |
| 確率的 | アボード | 角度ベースの外れ値の検出 | 2008年 | [22] |
| 確率的 | 速いABOD | 近似を使用した角度ベースの高速外れ値検出 | 2008年 | [22] |
| 確率的 | コポッド | COPOD: コピュラベースの外れ値検出 | 2020年 | [27] |
| 確率的 | 狂った | 中央値絶対偏差 (MAD) | 1993年 | [19] |
| 確率的 | SOS | 確率的外れ値の選択 | 2012年 | [20] |
| 確率的 | QMCD | 準モンテカルロ不一致の外れ値の検出 | 2001年 | [11] |
| 確率的 | KDE | カーネル密度関数による外れ値の検出 | 2007年 | [24] |
| 確率的 | サンプリング | サンプリングによる距離ベースの外れ値の迅速な検出 | 2013年 | [42] |
| 確率的 | GMM | 外れ値分析のための確率的混合モデリング | | [1] [第2章] |
| 線形モデル | PCA | 主成分分析 (固有ベクトル超平面までの重み付き投影距離の合計) | 2003年 | [41] |
| 線形モデル | KPCA | カーネル主成分分析 | 2007年 | [18] |
| 線形モデル | MCD | 最小共分散行列式 (外れ値スコアとしてマハラノビス距離を使用) | 1999年 | [16] [37] |
| 線形モデル | CD | 外れ値の検出にクック距離を使用する | 1977年 | [10] |
| 線形モデル | OCSVM | 1 クラスのサポート ベクター マシン | 2001年 | [40] |
| 線形モデル | LMDD | 偏差ベースの外れ値検出 (LMDD) | 1996年 | [6] |
| 近接ベース | LOF | 局所外れ値係数 | 2000年 | [8] |
| 近接ベース | COF | 接続ベースの外れ値係数 | 2002年 | [43] |
| 近接ベース | (増分) COF | メモリ効率の高い接続ベースの異常値係数 (速度は遅くなりますが、ストレージの複雑さは軽減されます) | 2002年 | [43] |
| 近接ベース | CBLOF | クラスタリングベースのローカル外れ値係数 | 2003年 | [17] |
| 近接ベース | LOCI | LOCI: 局所相関積分を使用した高速外れ値検出 | 2003年 | [33] |
| 近接ベース | HBOS | ヒストグラムベースの異常値スコア | 2012年 | [12] |
| 近接ベース | kNN | k 最近傍 (k 番目の最近傍までの距離を外れ値スコアとして使用) | 2000年 | [36] |
| 近接ベース | 平均KNN | 平均 kNN (k 個の最近傍までの平均距離を外れ値スコアとして使用) | 2002年 | [5] |
| 近接ベース | MedKNN | 中央値 kNN (外れ値スコアとして k 個の最近傍までの距離の中央値を使用) | 2002年 | [5] |
| 近接ベース | SOD | 部分空間外れ値の検出 | 2009年 | [23] |
| 近接ベース | ロッド | 回転ベースの外れ値検出 | 2020年 | [4] |
| 外れ値アンサンブル | アイフォレスト | 孤立の森 | 2008年 | [29] |
| 外れ値アンサンブル | インネ | 最近傍アンサンブルを使用した分離ベースの異常検出 | 2018年 | [7] |
| 外れ値アンサンブル | ディフ | 異常検出のための深く隔離されたフォレスト | 2023年 | [45] |
| 外れ値アンサンブル | FB | 機能のバギング | 2005年 | [25] |
| 外れ値アンサンブル | LSCP | LSCP: 並列外れ値アンサンブルの局所的に選択的な組み合わせ | 2019年 | [49] |
| 外れ値アンサンブル | XGBOD | エクストリーム ブースティング ベースの異常値検出(監視あり) | 2018年 | [48] |
| 外れ値アンサンブル | ロダ | 軽量のオンライン異常検出器 | 2016年 | [34] |
| 外れ値アンサンブル | スオード | SUOD: 大規模な教師なし異種外れ値検出の高速化(高速化) | 2021年 | [50] |
| ニューラルネットワーク | オートエンコーダ | 完全に接続された AutoEncoder (再構成エラーを外れ値スコアとして使用) | | [1] [3章] |
| ニューラルネットワーク | VAE | 変分オートエンコーダ (外れ値スコアとして再構成誤差を使用) | 2013年 | [21] |
| ニューラルネットワーク | ベータVAE | 変分オートエンコーダー (ガンマと容量を変更することですべてカスタマイズされた損失項) | 2018年 | [9] |
| ニューラルネットワーク | SO_GAAL | 単一目的の敵対的生成アクティブ ラーニング | 2019年 | [30] |
| ニューラルネットワーク | MO_GAAL | 複数目的の敵対的生成アクティブ ラーニング | 2019年 | [30] |
| ニューラルネットワーク | ディープSVDD | 深い 1 クラス分類 | 2018年 | [38] |
| ニューラルネットワーク | アノガン | 敵対的生成ネットワークによる異常検出 | 2017年 | [39] |
| ニューラルネットワーク | アラド | 敵対的に学習された異常検出 | 2018年 | [47] |
| ニューラルネットワーク | AE1SVM | オートエンコーダベースの 1 クラス サポート ベクター マシン | 2019年 | [31] |
| ニューラルネットワーク | デヴネット | 偏差ネットワークによる詳細な異常検出 | 2019年 | [32] |
| グラフベース | Rグラフ | Rグラフによる外れ値検出 | 2017年 | [46] |
| グラフベース | 月 | LUNAR: グラフ ニューラル ネットワークを介したローカル外れ値検出方法の統合 | 2022年 | [13] |
(ii) 外れ値アンサンブルと外れ値検出器の組み合わせフレームワーク:
| タイプ | 略称 | アルゴリズム | 年 | 参照 |
|---|
| 外れ値アンサンブル | FB | 機能のバギング | 2005年 | [25] |
| 外れ値アンサンブル | LSCP | LSCP: 並列外れ値アンサンブルの局所的に選択的な組み合わせ | 2019年 | [49] |
| 外れ値アンサンブル | XGBOD | エクストリーム ブースティング ベースの異常値検出(監視あり) | 2018年 | [48] |
| 外れ値アンサンブル | ロダ | 軽量のオンライン異常検出器 | 2016年 | [34] |
| 外れ値アンサンブル | スオード | SUOD: 大規模な教師なし異種外れ値検出の高速化(高速化) | 2021年 | [50] |
| 外れ値アンサンブル | インネ | 最近傍アンサンブルを使用した分離ベースの異常検出 | 2018年 | [7] |
| 組み合わせ | 平均 | スコアの平均による単純な組み合わせ | 2015年 | [2] |
| 組み合わせ | 加重平均 | 検出器の重みを使用してスコアを平均することによる単純な組み合わせ | 2015年 | [2] |
| 組み合わせ | 最大化 | 最大スコアを取るだけの簡単な組み合わせ | 2015年 | [2] |
| 組み合わせ | AOM | 平均値と最大値 | 2015年 | [2] |
| 組み合わせ | MOA | 平均値の最大化 | 2015年 | [2] |
| 組み合わせ | 中央値 | スコアの中央値を取る単純な組み合わせ | 2015年 | [2] |
| 組み合わせ | 過半数の投票 | ラベルの多数決を取るだけの簡単な組み合わせ(重み付けも可能) | 2015年 | [2] |
(iii) ユーティリティ関数:
| タイプ | 名前 | 関数 | ドキュメント |
|---|
| データ | データの生成 | 合成データの生成。正規データは多変量ガウス分布によって生成され、外れ値は一様分布によって生成されます。 | データの生成 |
| データ | 生成_データ_クラスター | クラスター内での合成データの生成。複数のクラスターを使用して、より複雑なデータ パターンを作成できます。 | 生成_データ_クラスター |
| ステータス | wピアソン | 2 つのサンプルの加重ピアソン相関を計算します。 | wピアソン |
| ユーティリティ | get_label_n | 上位 n 個の外れ値スコアに 1 を割り当てることで、生の外れ値スコアをバイナリ ラベルに変換します | get_label_n |
| ユーティリティ | precision_n_scores | ランク n で精度を計算する | precision_n_scores |
外れ値検出のクイックスタート
PyOD は、いくつかの注目記事やチュートリアルによって機械学習コミュニティによく知られています。
Analytics Vidhya : PyOD ライブラリを使用して Python で外れ値検出を学ぶための素晴らしいチュートリアル
KDnuggets : 外れ値検出メソッドの直感的な視覚化、PyOD からの外れ値検出メソッドの概要
データ サイエンスに向けて: 初心者向けの異常検出
「examples/knn_example.py」は、kNN 検出器を使用する基本的な API を示します。他のすべてのアルゴリズムの API は一貫性がある/類似していることに注意してください。
サンプルを実行するための詳細な手順は、examples ディレクトリにあります。
kNN 検出器を初期化し、モデルを適合させて、予測を行います。
from pyod . models . knn import KNN # kNN detector
# train kNN detector
clf_name = 'KNN'
clf = KNN ()
clf . fit ( X_train )
# get the prediction label and outlier scores of the training data
y_train_pred = clf . labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf . decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf . predict ( X_test ) # outlier labels (0 or 1)
y_test_scores = clf . decision_function ( X_test ) # outlier scores
# it is possible to get the prediction confidence as well
y_test_pred , y_test_pred_confidence = clf . predict ( X_test , return_confidence = True ) # outlier labels (0 or 1) and confidence in the range of [0,1]
ROC および Precision @ Rank n (p@n) によって予測を評価します。
from pyod . utils . data import evaluate_print
# evaluate and print the results
print ( " n On Training Data:" )
evaluate_print ( clf_name , y_train , y_train_scores )
print ( " n On Test Data:" )
evaluate_print ( clf_name , y_test , y_test_scores )
サンプル出力と視覚化を参照してください。
On Training Data :
KNN ROC : 1.0 , precision @ rank n : 1.0
On Test Data :
KNN ROC : 0.9989 , precision @ rank n : 0.9
visualize ( clf_name , X_train , y_train , X_test , y_test , y_train_pred ,
y_test_pred , show_figure = True , save_figure = False )
視覚化 (knn_figure):
参照
| [1] | (1、2) Aggarwal、CC、2015 年。外れ値分析。データマイニング (pp. 237-263) において。スプリンガー、チャム。 |
| [2] | (1、2、3、4、5、6、7) Aggarwal, CC および Sathe, S.、2015 年。異常値アンサンブルの理論的基礎とアルゴリズム。 ACM SIGKDD Explorations ニュースレター、17(1)、24-47 ページ。 |
| [3] | Aggarwal, CC および Sathe, S.、2017 年。異常値アンサンブル: 概要。スプリンガー。 |
| [4] | Almardeny, Y.、Boujnah, N.、および Cleary, F.、2020 年。多変量データの新しい外れ値検出方法。知識およびデータエンジニアリングに関する IEEE トランザクション。 |
| [5] | (1, 2) Angiulli, F. および Pizzuti, C.、2002 年 8 月。高次元空間での高速な外れ値検出。データ マイニングと知識発見の原則に関する欧州会議において、15 ~ 27 ページ。 |
| [6] | Arning, A.、Agrawal, R.、Raghavan, P.、1996 年 8 月。大規模データベースにおける逸脱検出のための線形手法。 KDD (Vol. 1141、No. 50、pp. 972-981) において。 |
| [7] | (1, 2) Bandaragoda, TR、Ting, KM、Albrecht, D.、Liu, FT、Zhu, Y.、および Wells, JR、2018 年、最近傍アンサンブルを使用した分離ベースの異常検出。 Computational Intelligence 、34(4)、968-998 ページ。 |
| [8] | Breunig, MM、Kriegel, HP、Ng, RT および Sander, J.、2000 年 5 月。 LOF: 密度ベースのローカル外れ値を特定します。 ACM Sigmod Record 、29(2)、93-104 ページ。 |
| [9] | バージェス、クリストファー P.、他。 「ベータ VAE でのもつれの解除を理解する。」 arXiv プレプリント arXiv:1804.03599 (2018)。 |
| [10] | Cook、RD、1977 年。線形回帰における影響力のある観測値の検出。テクノメトリクス、19(1)、pp.15-18。 |
| [11] | Fang、KT および Ma、CX、2001 年。ランダム サンプリングのラップアラウンド L2 不一致、ラテン超立方体および均一設計。 Journal of Complexity、17(4)、608-624 ページ。 |
| [12] | Goldstein, M. および Dengel, A.、2012 年。ヒストグラムベースの異常値スコア (hbos): 教師なしの高速異常検出アルゴリズム。 KI-2012: ポスターとデモトラック、pp.59-63。 |
| [13] | Goodge, A.、Hooi, B.、Ng, SK、Ng, WS、2022 年 6 月。 Lunar: グラフ ニューラル ネットワークを介したローカル外れ値検出方法を統合します。人工知能に関する AAAI 会議の議事録。 |
| [14] | Gopalan, P.、Sharan, V.、Wieder, U.、2019 年。PIDForest: 部分識別による異常検出。 『神経情報処理システムの進歩』、15783 ~ 15793 ページ。 |
| [15] | Han, S.、Hu, X.、Huang, H.、Jiang, M.、Zhao, Y.、2022 年。ADBench: 異常検出ベンチマーク。 arXiv プレプリント arXiv:2206.09426。 |
| [16] | Hardin, J. および Rocke, DM、2004 年。最小共分散行列式推定量を使用した複数クラスター設定での外れ値の検出。計算統計とデータ分析、44(4)、pp.625-638。 |
| [17] | He, Z.、Xu, X.、Deng, S.、2003 年。クラスターベースのローカル外れ値の発見。パターン認識文字、24(9-10)、pp.1641-1650。 |
| [18] | Hoffmann, H.、2007 年。新規性検出のためのカーネル PCA。パターン認識、40(3)、pp.863-874。 |
| [19] | Iglewicz, B. および Hoaglin, DC、1993 年。外れ値を検出して処理する方法 (Vol. 16)。アスクプレス。 |
| [20] | Janssens、JHM、Huszár、F.、Postma、EO、および van den Herik、HJ、2012 年。確率的外れ値の選択。技術レポート TiCC TR 2012-001、ティルブルフ大学、ティルブルグ認知コミュニケーションセンター、ティルブルフ、オランダ。 |
| [21] | Kingma, DP および Welling, M.、2013 年。変分ベイの自動エンコーディング。 arXiv プレプリント arXiv:1312.6114。 |
| [22] | (1、2) Kriegel, HP および Zimek, A.、2008 年 8 月。高次元データにおける角度ベースの外れ値検出。 KDD '08 、444-452 ページ。 ACM。 |
| [23] | Kriegel, HP、Kröger, P.、Schubert, E.、Zimek, A.、2009 年 4 月。高次元データの軸平行部分空間における外れ値の検出。知識発見とデータ マイニングに関する太平洋アジア会議、831 ~ 838 ページ。スプリンガー、ベルリン、ハイデルベルク。 |
| [24] | LJ ラチェキ、A. ラザレビッチ、D. ポクラジャック、2007 年 7 月。カーネル密度関数による外れ値の検出。パターン認識における機械学習とデータマイニングに関する国際ワークショップにて (pp. 61-75)。スプリンガー、ベルリン、ハイデルベルク。 |
| [25] | (1, 2) Lazarevic, A. および Kumar, V.、2005 年 8 月。外れ値検出のための特徴のバギング。 KDD'05年。 2005年。 |
| [26] | Li, D.、Chen, D.、Jin, B.、Shi, L.、Goh, J.、Ng、SK、2019 年 9 月。 MAD-GAN: 敵対的生成ネットワークを使用した時系列データの多変量異常検出。人工ニューラルネットワークに関する国際会議にて (pp. 703-716)。スプリンガー、チャム。 |
| [27] | Li, Z.、Zhao, Y.、Botta, N.、Ionescu, C.、Hu, X. COPOD: コピュラベースの外れ値検出。 IEEE データマイニング国際会議 (ICDM) 、2020 年。 |
| [28] | Li, Z.、Zhao, Y.、Hu, X.、Botta, N.、Ionescu, C. および Chen, HG ECOD: 経験的累積分布関数を使用した教師なし外れ値検出。知識およびデータ エンジニアリングに関する IEEE トランザクション (TKDE) 、2022 年。 |
| [29] | Liu、FT、Ting、KM、Zhou、ZH、2008 年 12 月。孤立の森。データマイニングに関する国際会議、413 ~ 422 ページ。 IEEE。 |
| [30] | (1, 2) Liu, Y.、Li, Z.、Zhou, C.、Jiang, Y.、Sun, J.、Wang, M.、および He, X.、2019 年。教師なし外れ値検出のための敵対的生成アクティブ学習。知識およびデータエンジニアリングに関する IEEE トランザクション。 |
| [31] | ミネソタ州グエンおよびノースカロライナ州ヴィエン、2019 年。深層学習とランダム フーリエ機能を備えた、スケーラブルで解釈可能な 1 クラス SVMS。データベースにおける機械学習と知識発見: 欧州会議、ECML PKDD、2018 年。 |
| [32] | パン、グアンソン、沈春華、アントン・ヴァン・デン・ヘンゲル。 「偏差ネットワークによる詳細な異常検出」。 KDD 、353-362 ページ。 2019年。 |
| [33] | パパディミトリウ、S.、北川、H.、ギボンズ、PB、ファルウソス、C.、2003 年 3 月。 LOCI: 局所相関積分を使用した高速外れ値検出。 ICDE '03 、315 ~ 326 ページ。 IEEE。 |
| [34] | (1, 2) Pevný, T.、2016。Loda: 異常の軽量オンライン検出器。機械学習、102(2)、pp.275-304。 |
| [35] | Perini, L.、Vercruyssen, V.、Davis, J. 例ごとの予測における異常検出器の信頼度を定量化します。データベースにおける機械学習と知識発見に関する欧州共同会議 (ECML-PKDD) 、2020 年。 |
| [36] | Ramaswamy, S.、Rastogi, R.、Shim, K.、2000 年 5 月。大規模なデータセットから外れ値をマイニングするための効率的なアルゴリズム。 ACM Sigmod Record 、29(2)、427-438 ページ。 |
| [37] | Rousseeuw、PJ および Driessen、KV、1999 年。最小共分散行列式推定量の高速アルゴリズム。テクノメトリクス、41(3)、pp.212-223。 |
| [38] | Ruff, L.、Vandermeulen, R.、Goernitz, N.、Deecke, L.、Siddiqui, SA、Binder, A.、Müller, E.、Kloft, M.、2018 年 7 月。深い 1 クラス分類。機械学習に関する国際会議にて (pp. 4393-4402)。 PMLR。 |
| [39] | Schlegl, T.、Seeböck, P.、Waldstein, SM、Schmidt-Erfurth, U.、Langs, G.、2017 年 6 月。マーカー発見をガイドする敵対的生成ネットワークによる教師なし異常検出。医用画像処理における情報処理に関する国際会議にて (pp. 146-157)。スプリンガー、チャム。 |
| [40] | Scholkopf, B.、Platt, JC、Shawe-Taylor, J.、Smola, AJ、および Williamson, RC、2001 年。高次元分布のサポートの推定。ニューラル コンピューティング、13(7)、pp.1443-1471。 |
| [41] | Shyu, ML、Chen, SC、Sarinnapakorn, K.、Chang, L.、2003 年。主成分分類器に基づく新しい異常検出スキーム。マイアミ大学コーラルゲーブルズフロリダ州電気・コンピュータ工学科。 |
| [42] | 杉山 M. および Borgwardt, K.、2013 年。サンプリングによる距離ベースの迅速な外れ値検出。神経情報処理システムの進歩、26. |
| [43] | (1、2) Tang、J.、Chen、Z.、Fu、AWC、および Cheung、DW、2002 年 5 月。低密度パターンの外れ値検出の有効性を強化します。知識発見とデータ マイニングに関する太平洋アジア会議、535 ~ 548 ページ。スプリンガー、ベルリン、ハイデルベルク。 |
| [44] | Wang, X.、Du, Y.、Lin, S.、Cui, P.、Shen, Y.、Yang, Y.、2019。 adVAE: 異常検出のためのガウス異常事前知識を備えた自己敵対的変分オートエンコーダー。知識ベースのシステム。 |
| [45] | Xu, H.、Pang, G.、Wang, Y.、Wang, Y.、2023。異常検出のための深く隔離されたフォレスト。知識およびデータエンジニアリングに関する IEEE トランザクション。 |
| [46] | You, C.、Robinson, DP、Vidal, R.、2017 年。部分空間の結合における証明可能な自己表現に基づく外れ値検出。コンピューター ビジョンとパターン認識に関する IEEE 会議の議事録。 |
| [47] | Zenati, H.、Romain, M.、Foo, CS、Lecouat, B.、Chandrasekhar, V.、2018 年 11 月。敵対的に学習された異常検出。 2018 年のデータ マイニングに関する IEEE 国際会議 (ICDM) (pp. 727-736)。 IEEE。 |
| [48] | (1, 2) Zhao, Y. および Hryniewicki, MK XGBOD: 教師なし表現学習による教師あり外れ値検出の改善。ニューラルネットワークに関するIEEE国際共同会議、2018年。 |
| [49] | (1, 2) Zhao, Y.、Nasrullah, Z.、Hryniewicki, MK、Li, Z.、2019 年 5 月。 LSCP: 並列外れ値アンサンブルにおける局所的に選択的な組み合わせ。 2019 SIAM International Conference on Data Mining (SDM) の議事録、585 ~ 593 ページ。工業および応用数学協会。 |
| [50] | (1, 2, 3, 4) Zhao, Y.、Hu, X.、Cheng, C.、Wang, C.、Wan, C.、Wang, W.、Yang, J.、Bai, H.、Li 、Z.、Xiao, C.、Wang, Y.、Qiao, Z.、Sun, J.、Akoglu, L. (2021)。 SUOD: 大規模な教師なし異種異常値検出の高速化。機械学習とシステムに関する会議 (MLSys) 。 |


