optuna
v4.1.0
?ウェブサイト| ?ドキュメント|インストールガイド|チュートリアル|例|ツイッター|リンクトイン|中くらい
Optunaは、特に機械学習用に設計された自動ハイパーパラメータ最適化ソフトウェア フレームワークです。これは、命令型の実行による定義スタイルのユーザー API を備えています。 Define-by-Run API のおかげで、Optuna で書かれたコードは高いモジュール性を享受し、Optuna のユーザーはハイパーパラメータの検索スペースを動的に構築できます。
Terminatorに関する記事を投稿しました。JournalStorageに関する記事を投稿しました。pip install -U optunaでインストールできます。ここで最新情報を見つけて記事を確認してください。 Optuna には次のような最新の機能があります。
研究とトライアルという用語を次のように使用します。
以下のサンプルコードを参照してください。研究の目標は、複数の試行(例: n_trials=100 ) を通じてハイパーパラメータ値の最適なセット (例: regressorとsvr_c ) を見つけることです。 Optuna は、最適化研究の自動化と高速化のために設計されたフレームワークです。
import ...
# Define an objective function to be minimized.
def objective ( trial ):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial . suggest_categorical ( 'regressor' , [ 'SVR' , 'RandomForest' ])
if regressor_name == 'SVR' :
svr_c = trial . suggest_float ( 'svr_c' , 1e-10 , 1e10 , log = True )
regressor_obj = sklearn . svm . SVR ( C = svr_c )
else :
rf_max_depth = trial . suggest_int ( 'rf_max_depth' , 2 , 32 )
regressor_obj = sklearn . ensemble . RandomForestRegressor ( max_depth = rf_max_depth )
X , y = sklearn . datasets . fetch_california_housing ( return_X_y = True )
X_train , X_val , y_train , y_val = sklearn . model_selection . train_test_split ( X , y , random_state = 0 )
regressor_obj . fit ( X_train , y_train )
y_pred = regressor_obj . predict ( X_val )
error = sklearn . metrics . mean_squared_error ( y_val , y_pred )
return error # An objective value linked with the Trial object.
study = optuna . create_study () # Create a new study.
study . optimize ( objective , n_trials = 100 ) # Invoke optimization of the objective function. 注記
その他の例は optuna/optuna-examples にあります。
この例では、多目的最適化、制約付き最適化、枝刈り、分散最適化などのさまざまな問題設定をカバーしています。
Optuna は、Python Package Index および Anaconda Cloud で入手できます。
# PyPI
$ pip install optuna # Anaconda Cloud
$ conda install -c conda-forge optuna重要
Optuna は Python 3.8 以降をサポートします。
また、Optuna Docker イメージを DockerHub で提供しています。
Optuna には、さまざまなサードパーティ ライブラリとの統合機能があります。統合については optuna/optuna-integration を参照してください。ドキュメントはここから入手できます。
Optuna ダッシュボードは、Optuna のリアルタイム Web ダッシュボードです。最適化履歴やハイパーパラメータの重要度などをグラフや表で確認できます。 Optuna の視覚化関数を呼び出すために Python スクリプトを作成する必要はありません。機能リクエストやバグレポートは大歓迎です!
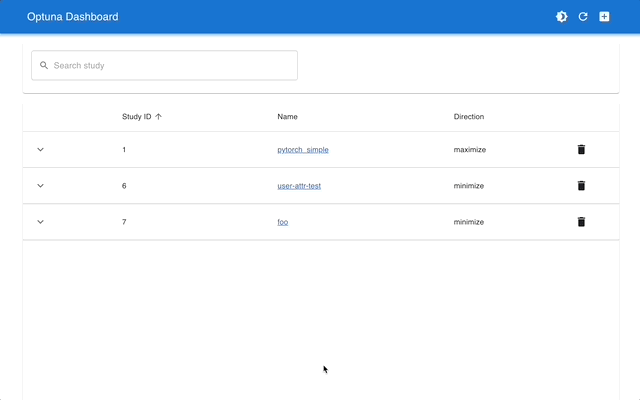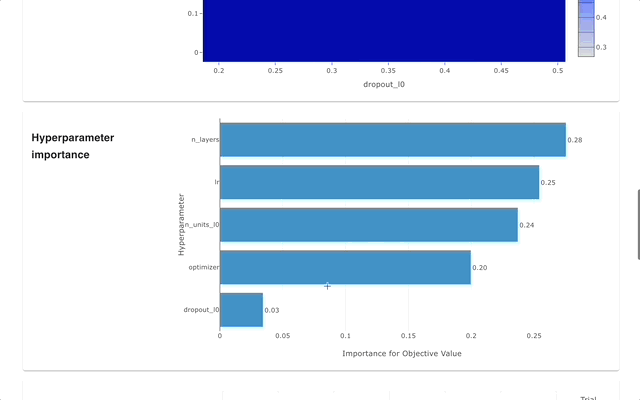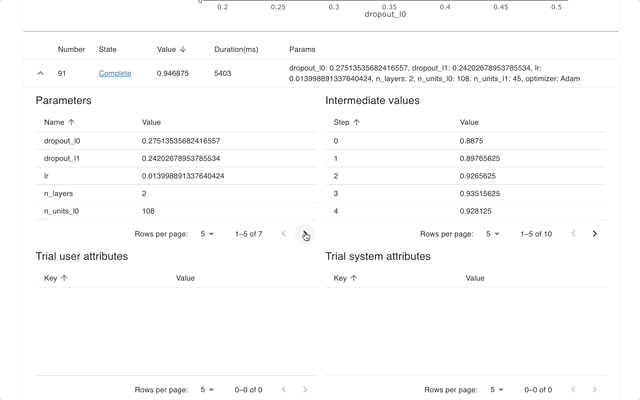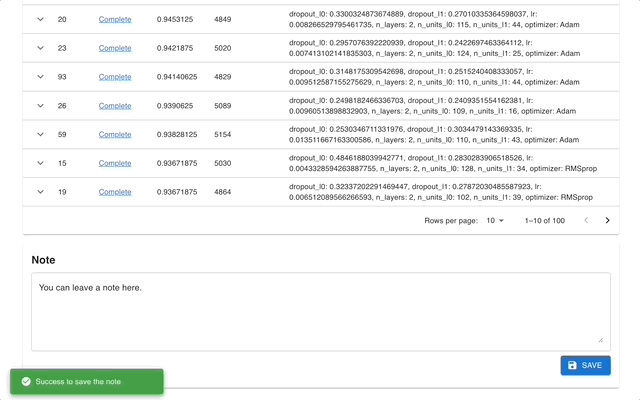
optuna-dashboard pip 経由でインストールできます。
$ pip install optuna-dashboardヒント
以下のサンプルコードを使用して、Optuna Dashboard の便利さを確認してください。
次のコードをoptimize_toy.pyとして保存します。
import optuna
def objective ( trial ):
x1 = trial . suggest_float ( "x1" , - 100 , 100 )
x2 = trial . suggest_float ( "x2" , - 100 , 100 )
return x1 ** 2 + 0.01 * x2 ** 2
study = optuna . create_study ( storage = "sqlite:///db.sqlite3" ) # Create a new study with database.
study . optimize ( objective , n_trials = 100 )次に、以下のコマンドを試してください。
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.OptunaHub は、Optuna の機能共有プラットフォームです。登録された機能を使用し、パッケージを公開できます。
optunahub pip 経由でインストールできます。
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu optunahub.load_moduleを使用して、登録されたモジュールをロードできます。
import optuna
import optunahub
def objective ( trial : optuna . Trial ) -> float :
x = trial . suggest_float ( "x" , - 5 , 5 )
y = trial . suggest_float ( "y" , - 5 , 5 )
return x ** 2 + y ** 2
module = optunahub . load_module ( package = "samplers/auto_sampler" )
study = optuna . create_study ( sampler = module . AutoSampler ())
study . optimize ( objective , n_trials = 10 )
print ( study . best_trial . value , study . best_trial . params )詳細については、optunahub のドキュメントを参照してください。
optunahub-registry を介してパッケージを公開できます。 OptunaHub チュートリアルを参照してください。
Optuna への貢献は大歓迎です!
Optuna を初めて使用する場合は、最初の優れた問題を確認してください。これらは比較的シンプルで明確に定義されており、多くの場合、コントリビューション ワークフローや他の開発者に慣れるための良い出発点となります。
すでに Optuna に貢献している場合は、他の貢献歓迎号をお勧めします。
プロジェクトに貢献する方法に関する一般的なガイドラインについては、CONTRIBUTING.md をご覧ください。
研究プロジェクトのいずれかで Optuna を使用する場合は、KDD の論文「Optuna: 次世代ハイパーパラメータ最適化フレームワーク」を引用してください。
@inproceedings { akiba2019optuna ,
title = { {O}ptuna: A Next-Generation Hyperparameter Optimization Framework } ,
author = { Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori } ,
booktitle = { The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
pages = { 2623--2631 } ,
year = { 2019 }
}MIT ライセンス (「ライセンス」を参照)。
Optuna は、SciPy および fdlibm プロジェクトのコードを使用します (LICENSE_THIRD_PARTY を参照)。


