cleanrl
v1.0.0 CleanRL Release ?
CleanRL は、研究に適した機能を備えた高品質の単一ファイル実装を提供する深層強化学習ライブラリです。実装はクリーンでシンプルですが、AWS Batch を使用して何千もの実験を実行できるように拡張できます。 CleanRL の主な機能は次のとおりです。
ppo_atari.pyのコードは 340 行しかありませんが、PPO が Atari ゲームでどのように動作するかに関する実装の詳細がすべて含まれているため、モジュラー ライブラリ全体を読みたくない人が読むのに最適なリファレンス実装です。CleanRL の詳細については、JMLR の論文とドキュメントを参照してください。
注目すべき CleanRL 関連プロジェクト:
Gymnasium のサポート: Farama-Foundation/Gymnasium は、継続的にメンテナンスされ、新しい機能が導入される次世代の
openai/gymです。詳細については、発表をご覧ください。私たちはgymnasiumに移行しており、進捗状況は vwxyzjn/cleanrl#277 で追跡できます。
️ 注: CleanRL はモジュール型ライブラリではないため、インポートすることは意図されていません。コードが重複する代わりに、DRL アルゴリズムのバリアントの実装の詳細をすべて理解しやすくするため、CleanRL には独自の長所と短所が伴います。 1) アルゴリズムの可変長のすべての実装詳細を理解する、または 2) 他のモジュラー DRL ライブラリがサポートしていない高度な機能のプロトタイプを作成したい場合は、CleanRL の使用を検討してください (CleanRL のコード行は最小限であるため、優れたデバッグ エクスペリエンスが得られます)。モジュラー DRL ライブラリのように多くのサブクラス化を行う必要はありません)。
前提条件:
実験をローカルで実行するには、次のことを試してください。
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runswandb で実験追跡を使用するには、次を実行します。
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest poetry使用していない場合は、 requirements.txtを使用して CleanRL をインストールできます。
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txt他のゲームでトレーニング スクリプトを実行するには:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Gitpod でホストされている事前構築済みの開発環境を使用することもできます。
| アルゴリズム | 実装されたバリアント |
|---|---|
| ✅ 近接ポリシー勾配 (PPO) | ppo.py 、ドキュメント |
ppo_atari.py 、ドキュメント | |
ppo_continuous_action.py 、ドキュメント | |
ppo_atari_lstm.py 、ドキュメント | |
ppo_atari_envpool.py 、ドキュメント | |
ppo_atari_envpool_xla_jax.py 、ドキュメント | |
ppo_atari_envpool_xla_jax_scan.py 、ドキュメント) | |
ppo_procgen.py 、ドキュメント | |
ppo_atari_multigpu.py 、ドキュメント | |
ppo_pettingzoo_ma_atari.py 、ドキュメント | |
ppo_continuous_action_isaacgym.py 、ドキュメント | |
ppo_trxl.py 、ドキュメント | |
| ✅ ディープ Q ラーニング (DQN) | dqn.py 、ドキュメント |
dqn_atari.py 、ドキュメント | |
dqn_jax.py 、ドキュメント | |
dqn_atari_jax.py 、ドキュメント | |
| ✅ カテゴリカルな DQN (C51) | c51.py 、ドキュメント |
c51_atari.py 、ドキュメント | |
c51_jax.py 、ドキュメント | |
c51_atari_jax.py 、ドキュメント | |
| ✅ ソフトアクター批評家 (SAC) | sac_continuous_action.py 、ドキュメント |
sac_atari.py 、ドキュメント | |
| ✅ 深い決定論的ポリシー勾配 (DDPG) | ddpg_continuous_action.py 、ドキュメント |
ddpg_continuous_action_jax.py 、ドキュメント | |
| ✅ ツイン遅延ディープ決定論的ポリシー勾配 (TD3) | td3_continuous_action.py 、ドキュメント |
td3_continuous_action_jax.py 、ドキュメント | |
| ✅ 段階的ポリシー勾配 (PPG) | ppg_procgen.py 、ドキュメント |
| ✅ ランダムネットワーク蒸留 (RND) | ppo_rnd_envpool.py 、ドキュメント |
| ✅ Qダガー | qdagger_dqn_atari_impalacnn.py 、ドキュメント |
qdagger_dqn_atari_jax_impalacnn.py 、ドキュメント |
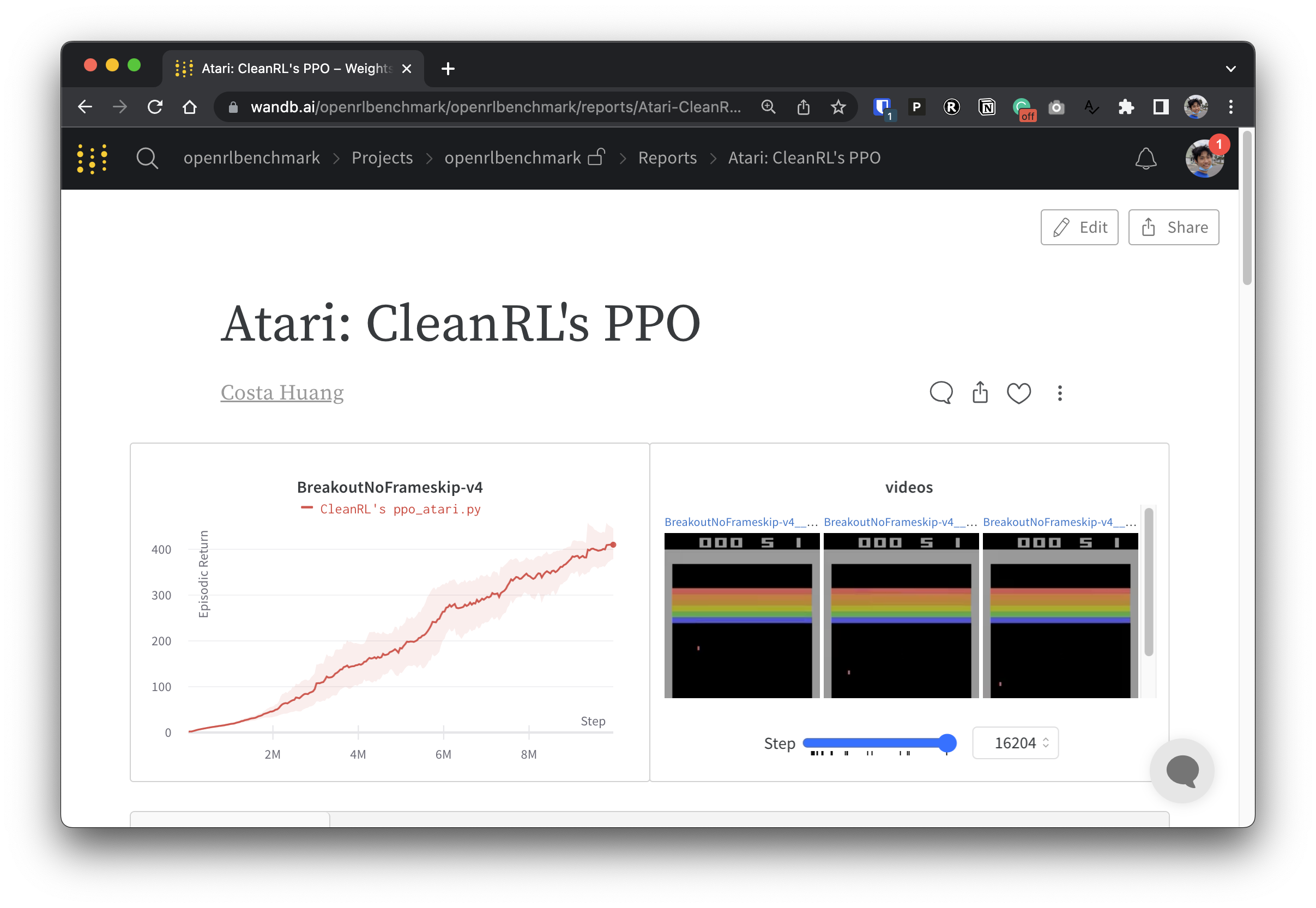
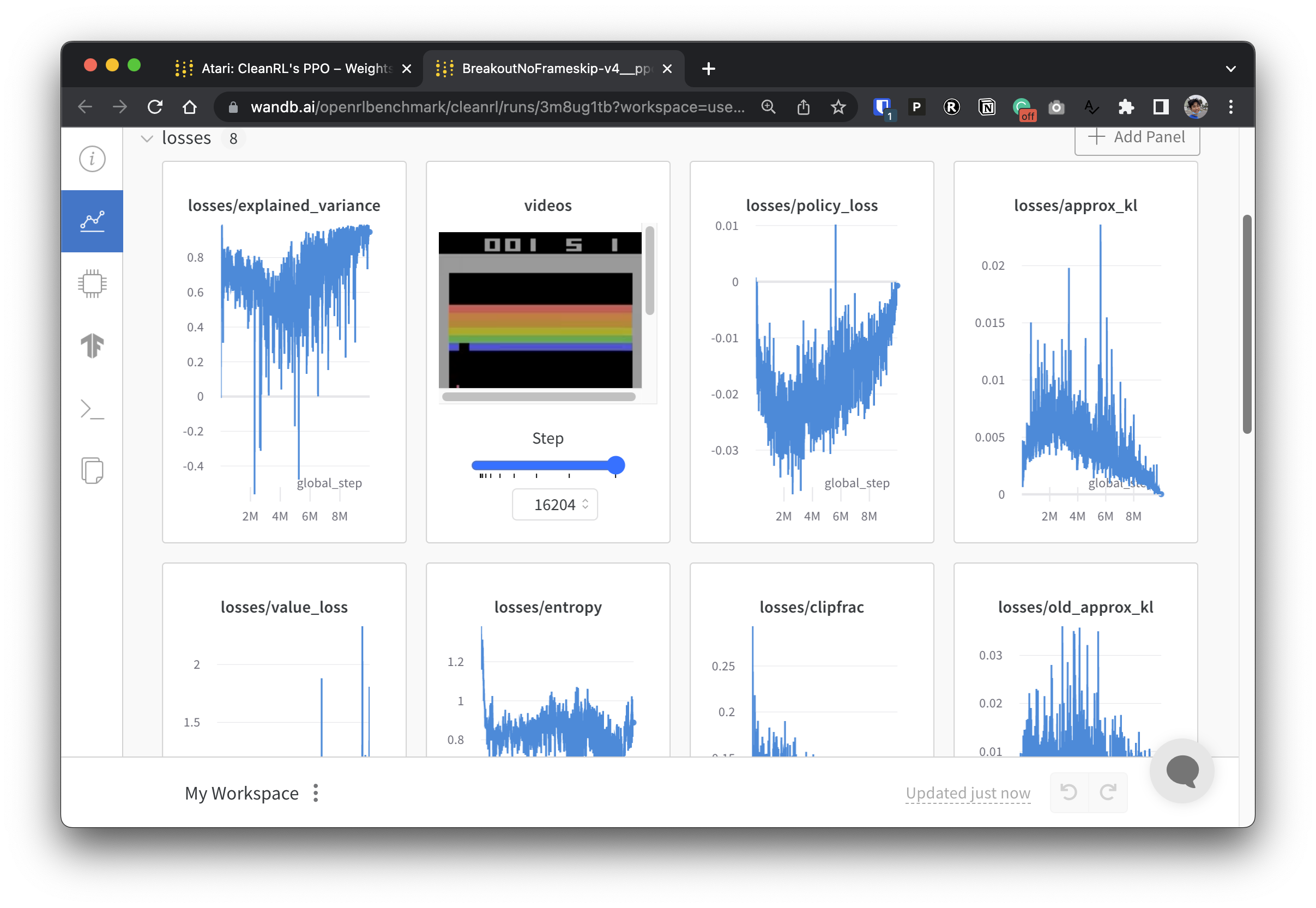
実験データを透過的にするために、CleanRL は Open RL Benchmark と呼ばれる関連プロジェクトに参加しています。このプロジェクトには、Stable-baselines3、openai/baselines、jaxrl などの人気のある DRL ライブラリからの追跡された実験が含まれています。
追跡された DRL 実験を紹介する重みとバイアスのレポートのコレクションについては、https://benchmark.cleanrl.dev/ をチェックしてください。レポートはインタラクティブであり、研究者は、GPU 使用率やエージェントのゲームプレイのビデオなど、他の RL ベンチマークでは通常取得が難しい情報を簡単にクエリできます。将来的には、Open RL Benchmark は研究者がデータに簡単にアクセスできるデータセット API を提供する予定です (リポジトリを参照)。
サポートのための Discord コミュニティがあります。お気軽にご質問ください。 Github Issue や PR への投稿も歓迎です。過去のビデオ録画も YouTube でご覧いただけます
仕事で CleanRL を使用する場合は、次の技術文書を引用してください。
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL はコミュニティ主導のプロジェクトであり、貢献者はさまざまなハードウェアで実験を実行しています。


