XHS Downloader
XHS-Downloader V2.3

簡体字中国語 |
小紅書リンク抽出・作品収集ツール: アカウント投稿、コレクション、いいね、アルバムの作品リンクを抽出; 小紅書作品のダウンロードアドレスを抽出; 小紅書作品ファイルをダウンロード;
このプロジェクトは完全に無料でオープンソースであり、有料機能はありません。騙されないでください。
XHS-Downloader の開発計画と進捗状況はプロジェクトで確認できます。
? 画像をクリックするとデモビデオがご覧いただけます。
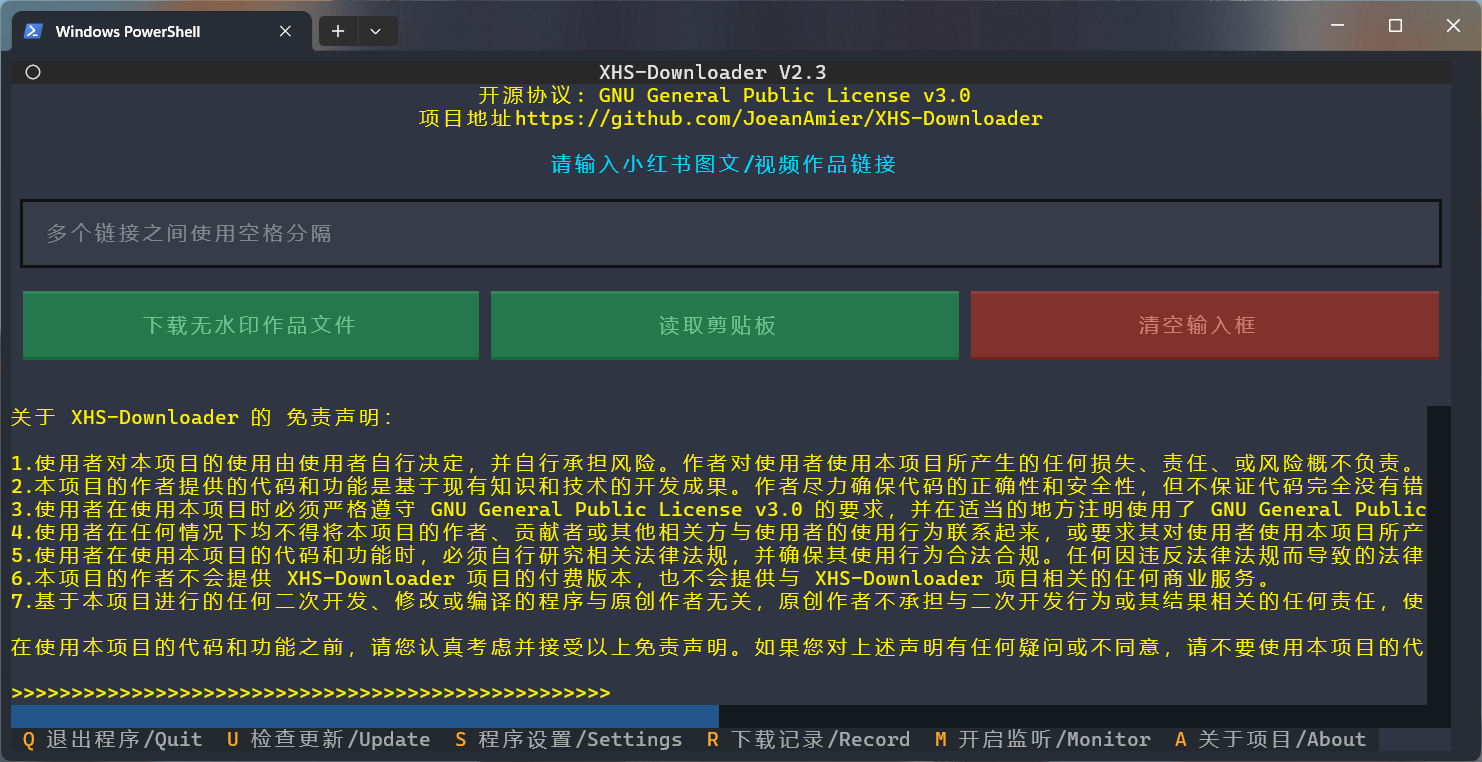
https://www.xiaohongshu.com/explore/作品ID?xsec_token=XXXhttps://www.xiaohongshu.com/discovery/item/作品ID?xsec_token=XXXhttps://xhslink.com/分享码スペースを使用してリンクを区切ることで、一度に複数の作業リンクを入力できます。プログラムは追加の処理を行わずに有効なリンクを自動的に抽出します。
最適な表示効果を得るには、Windows ターミナル (Windows 11 のデフォルトのターミナル) を使用してプログラムを実行することをお勧めします。
ウォーターマークなしの作業ファイルをダウンロードするだけの場合は、 「プログラムの実行」または「Docker の実行」を選択することをお勧めします。他のニーズがある場合は、 「ソースコードの実行」を選択することをお勧めします。
バージョン2.2からは、プロジェクト機能に異常がなければ、追加で Cookie を処理する必要はありません。
Mac OS、Windows 10 以降のユーザーは、「リリース」に移動してプログラムの圧縮パッケージをダウンロードし、解凍してプログラム フォルダーを開き、ダブルクリックしてmainを実行して使用できます。
注: Mac OS プラットフォームの実行可能ファイルmain 、デバイスの制限により、ターミナル コマンド ラインから起動する必要がある場合があります。Mac OS プラットフォームの実行可能ファイルはテストされていないため、可用性は保証できません。
この方法でプログラムを使用する場合、デフォルトのファイル ダウンロード パスは._internalDownload 、構成ファイル パスは._internalsettings.jsonです。
Dockerfileを使用してイメージを構築するdocker pull joeanamier/xhs-downloaderコマンドを使用してイメージをプルするdocker run -it joeanamier/xhs-downloaderdocker run -it joeanamier/xhs-downloader python main.py serverdocker start -i 容器名称/容器IDdocker restart -i 容器名称/容器IDDocker はプロジェクト実行時にコマンド ライン呼び出しモードをサポートしていません。クリップボードの読み取りとクリップボードの監視機能は正常に使用できません。その他の機能に異常がある場合は、報告してください。
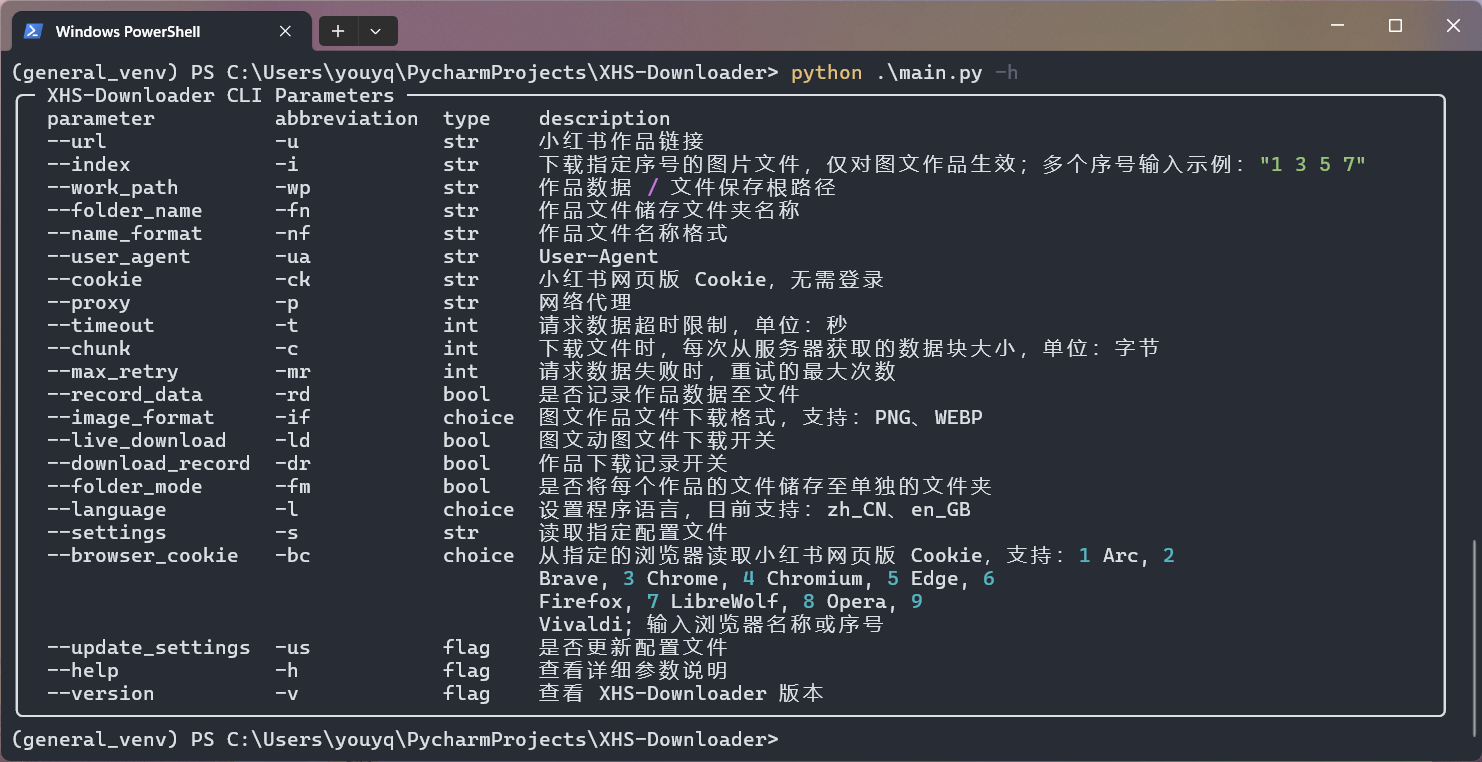
3.12以上の Python インタープリターをインストールします。pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txtコマンドを実行して、プログラムに必要なモジュールをインストールします。main.py実行して使用しますプロジェクトはコマンドライン操作モードをサポートしており、グラフィック作品の画像をダウンロードしたい場合は、このモードを使用してダウンロードする画像のシリアル番号を設定できます。
Cookie はブラウザから読み取ったり、コマンド ラインを使用して設定ファイルに書き込んだりできます。
コマンド例: python .main.py --browser_cookie Chrome --update_settings
bool型パラメーターは、 true 、 false 、 1 、 0 、 yes 、 no 、 onまたはoff (大文字と小文字は区別されません) を使用した設定をサポートします。
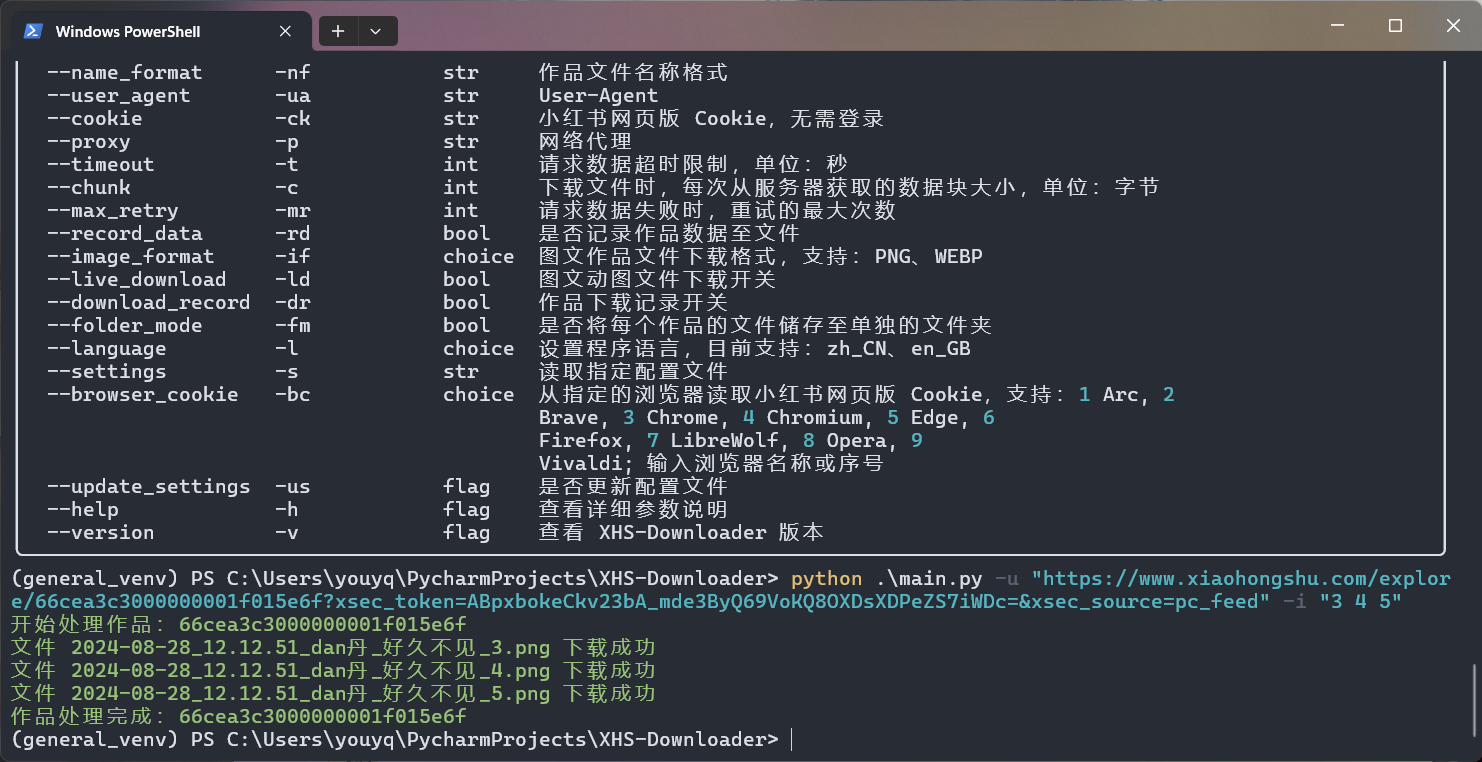
開始:コマンドを実行: python .main.py server
シャットダウン: Ctrl + C押してサーバーをシャットダウンします。
リクエストインターフェイス: /xhs/
リクエストメソッド: POST
リクエスト形式: JSON
リクエストパラメータ:
| パラメータ | タイプ | 意味 | デフォルト値 |
|---|---|---|---|
| URL | str | 小紅書作品へのリンクは自動的に抽出され、複数のリンクはサポートされていません。 | なし |
| ダウンロード | ブール | 作業ファイルをダウンロードするかどうかをtrueに設定すると、さらに時間がかかります。 | 間違い |
| 索引 | リスト[int] | 指定されたシリアル番号を持つ画像ファイルのダウンロードはグラフィック作品に対してのみ有効であり、 downloadパラメータがfalse | ヌル |
| スキップ | ブール | ダウンロード レコードのある作品をスキップするかどうかをtrueに設定すると、ダウンロード レコードのある作品のデータは返されません。 | 間違い |
コード例:
def api_demo():
サーバー = "http://127.0.0.1:8000/xhs/"
データ = {
"url": "https://www.xiaohonshu.com/explore/123456789",
「ダウンロード」: True、
"索引": [
3、
6、
9、
]、
}
応答 = リクエスト.ポスト(サーバー、json=データ)
print(response.json())
ブラウザに Tampermonkey ブラウザ拡張機能がインストールされている場合は、ダウンロードしてインストールしなくても、ユーザー スクリプトを追加してプロジェクトの機能を体験できます。
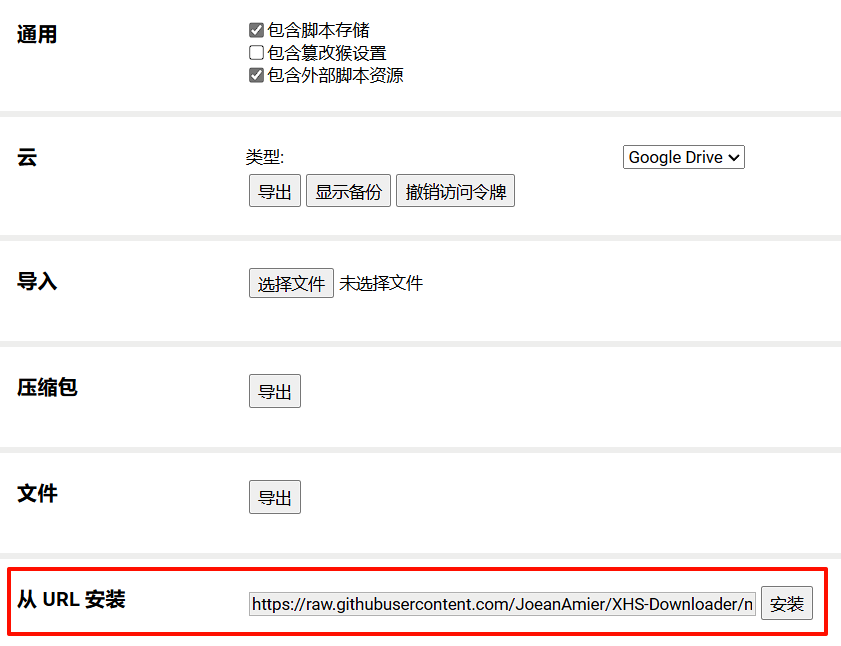
スクリプトが正常にインストールされたら、Xiaohongshu ページを開き、スクリプトの説明を表示し、プロンプトに従います。
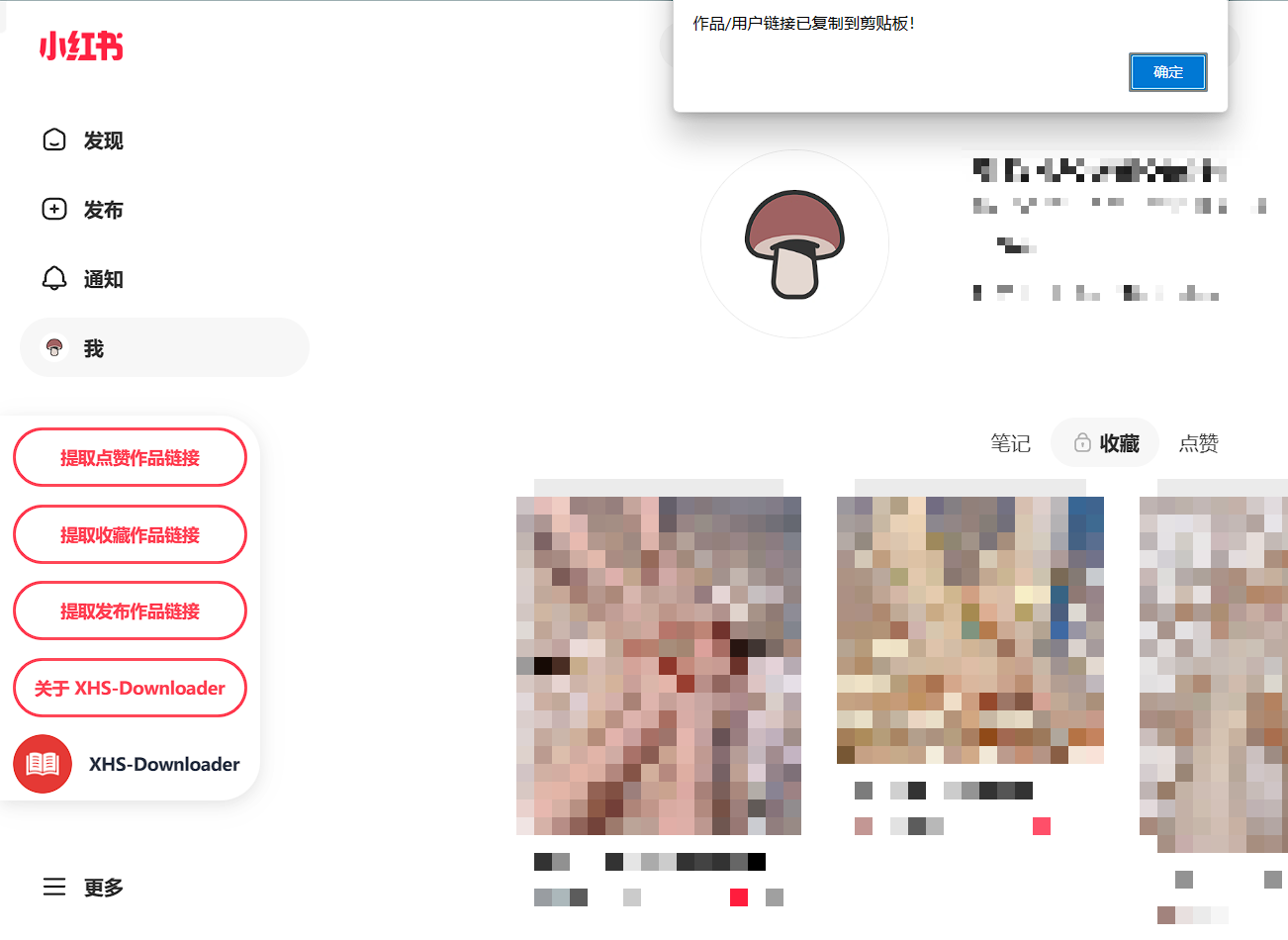
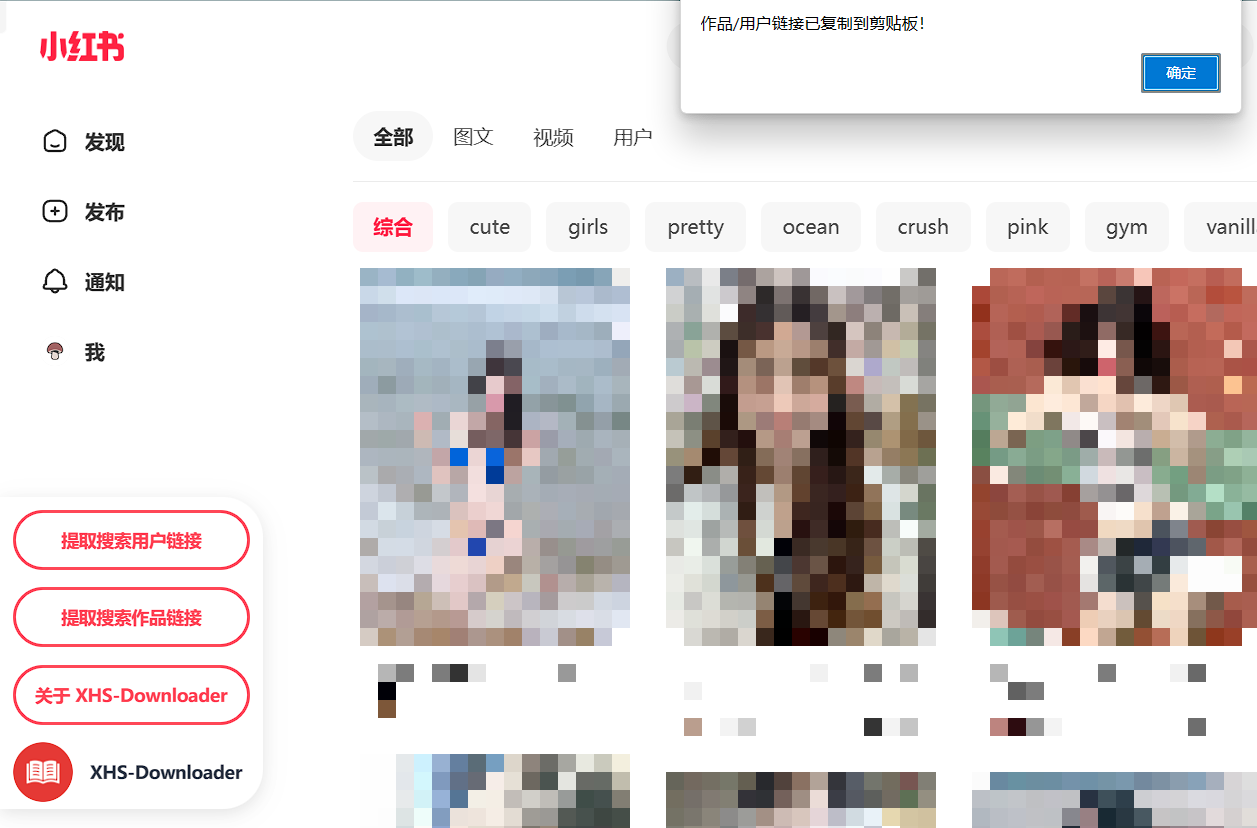
ヒント: XHS-Downloader ユーザー スクリプトを使用して作業リンクをバッチで抽出し、XHS-Downloader プログラムを使用してウォーターマークなしで作業ファイルをバッチ ダウンロードします。
他に必要な場合は、 main.pyのコメント プロンプトに従ってコードを呼び出したり変更したりできます。
非同期デフォルトの例():
"""コードを通じてパラメータを設定するため、二次開発に適しています"""
# サンプルリンク error_link = "https://github.com/JoeanAmier/XHS_Downloader"
デモリンク = "https://www.xiaohonshu.com/explore/xxxxxxxxxx"
multiple_links = f"{demo_link} {demo_link} {demo_link}"
# インスタンスオブジェクト work_path = "D:\" # 作業データ/ファイルを保存するルートパス、デフォルト値: プロジェクトルートパスfolder_name = "Download" # 作業ファイル格納フォルダ名(自動作成)、デフォルト値:ダウンロード
name_format = "作品名 作品概要"
user_agent = "" # ユーザーエージェント
cookie = "" # Xiaohonshu Web バージョンの Cookie、ログインは不要、オプションのパラメータ、ログイン ステータスはデータ収集に影響を与える proxy = None # ネットワーク プロキシ タイムアウト = 5 # リクエスト データのタイムアウト制限、単位: 秒、デフォルト値: 10
chunk = 1024 * 1024 * 10 # ファイルをダウンロードする際、毎回サーバーから取得するデータブロックのサイズ、単位: バイト max_retry = 2 # データのリクエストが失敗した場合の最大リトライ回数、単位: 秒、デフォルト値:5
Record_data = False # 作業データをファイルに保存するかどうか image_format = "WEBP" # グラフィックおよびテキストの作業ファイルのダウンロード形式、サポート: PNG、WEBP
folder_mode = False # 各作品のファイルを別のフォルダーに保存するかどうか # XHS() を xhs として非同期:
# pass # XHS と非同期でデフォルトのパラメータを使用(
ワークパス=ワークパス、
フォルダー名=フォルダー名、
名前の形式=名前の形式、
ユーザーエージェント=ユーザーエージェント、
クッキー=クッキー、
プロキシ=プロキシ、
タイムアウト=タイムアウト、
チャンク=チャンク、
max_retry=max_retry,
レコードデータ=レコードデータ、
画像フォーマット=画像フォーマット、
フォルダーモード=フォルダーモード、
) as xhs: # カスタムパラメータを使用します download = True # 作業ファイルをダウンロードするかどうか、デフォルト値: False
# ダウンロードアドレスを含む作品の詳細情報を返す # データの取得に失敗した場合は空の辞書を返す print(await xhs.extract(error_link, download, ))
print(await xhs.extract(demo_link, download,index=[1, 2]))
# 複数の作業リンクの受け渡しをサポート print(await xhs.extract(multiple_links, download, ))
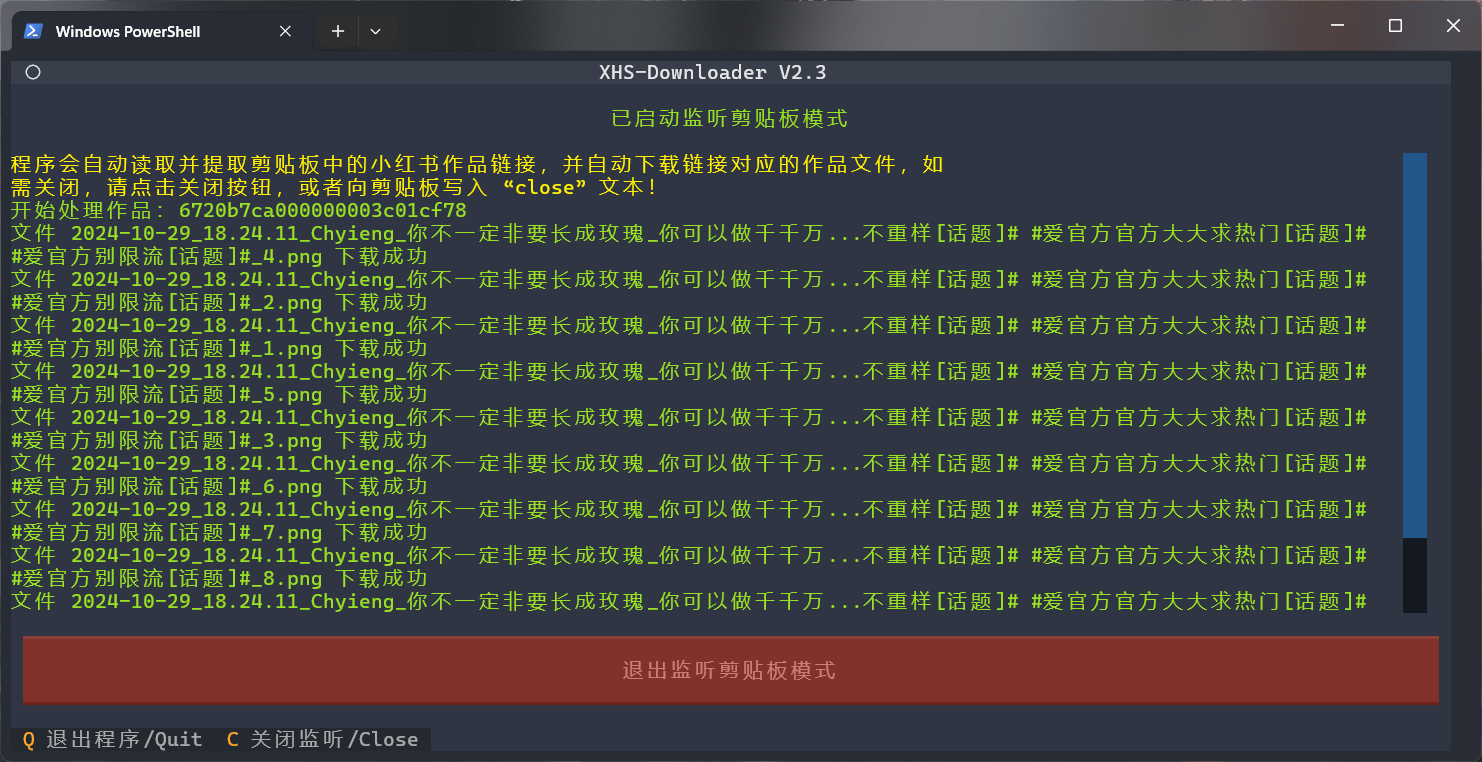
このプロジェクトはpyperclip使用してクリップボード読み取り機能を実装します。このモジュールはシステムによって異なります。
Windows では、追加のモジュールは必要ありません。
Mac では、このモジュールは pbcopy および pbpaste コマンドを使用します。これらのコマンドはオペレーティング システムに付属している必要があります。
Linux では、このモジュールは xclip または xsel コマンドを使用します。これらのコマンドはオペレーティング システムに付属している必要があります。それ以外の場合は、「sudo apt-get install xclip」または「sudo apt-get install xsel」を実行します(注: xsel は常に機能するとは限りません)。
他の Linux システムでは、qtpy または PyQT5 モジュールをインストールする必要があります。
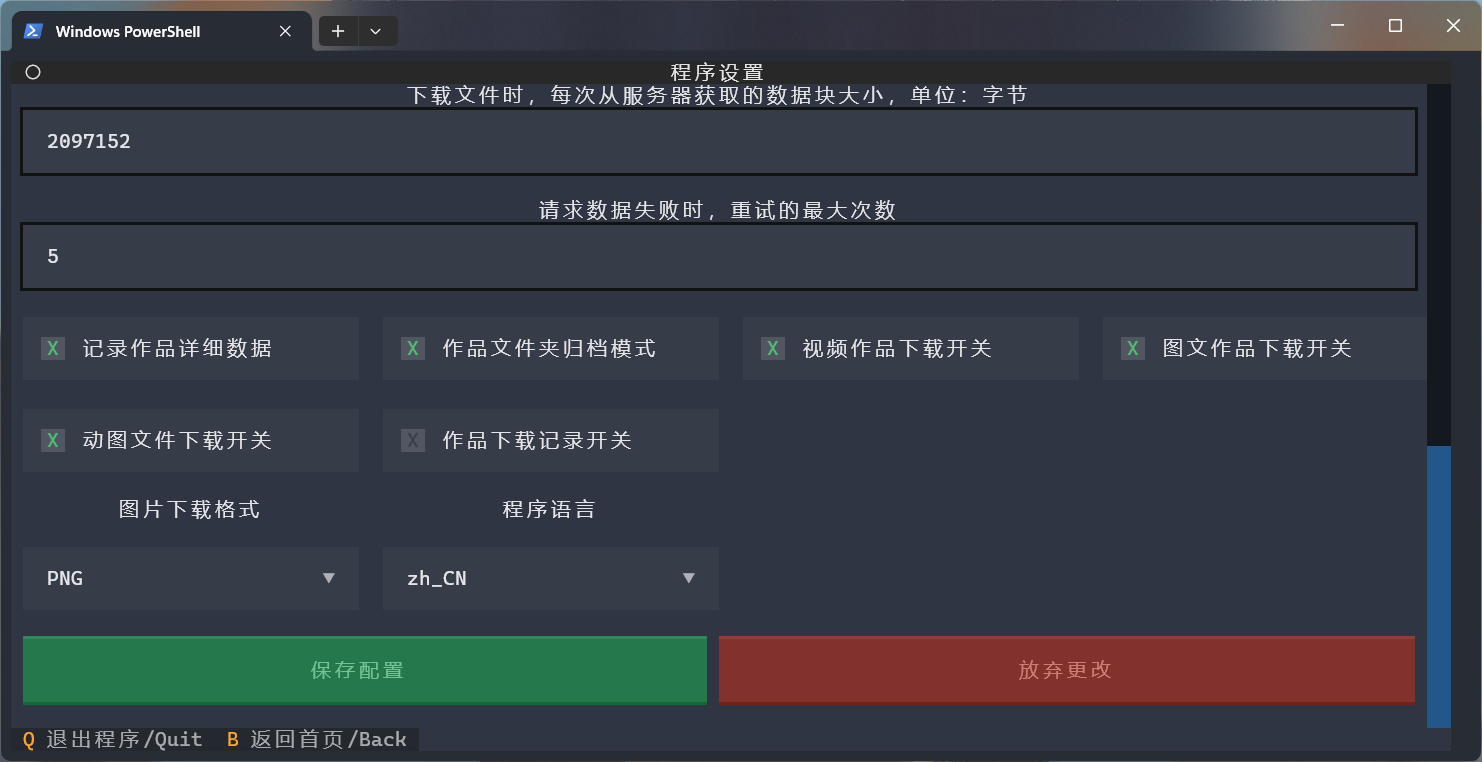
プロジェクトのルート ディレクトリ内のsettings.jsonファイルは、初回実行時に自動的に生成され、一部の実行パラメータはカスタマイズできます。
無効なパラメータ値が設定されている場合、プログラムはパラメータのデフォルト値を使用します。
| パラメータ | タイプ | 意味 | デフォルト値 |
|---|---|---|---|
| ワークパス | str | 作業データ/ファイル保存ルートパス | プロジェクトのルートパス |
| フォルダ名 | str | 作業ファイルが保存されているフォルダーの名前 | ダウンロード |
| 名前の形式 | str | 作品ファイル名の形式。スペースを使用してフィールドを区切ります。 サポートされるフィールド:收藏数量、评论数量、分享数量、点赞数量、作品标签、作品ID 、作品标题、作品描述、作品类型、发布时间、最后更新时间、作者昵称、作者ID | 发布时间作者昵称作品标题 |
| ユーザーエージェント | str | ブラウザユーザーエージェント | 組み込みの Chrome ユーザー エージェント |
| クッキー | str | 小紅書 Web バージョン Cookie、ログイン不要、必須パラメータなし! | なし |
| プロキシ | str | プログラムプロキシのセットアップ | ヌル |
| タイムアウト | 整数 | リクエストデータのタイムアウト制限、単位: 秒 | 10 |
| かたまり | 整数 | ファイルをダウンロードする際、毎回サーバーから取得するデータブロックのサイズ、単位:バイト | 2097152(2MB) |
| max_retry | 整数 | データのリクエストが失敗した場合の最大リトライ回数、単位:秒 | 5 |
| レコードデータ | ブール | 作業データをファイルに保存するかどうか、保存形式: SQLite | 間違い |
| 画像形式 | str | グラフィックおよびテキストの作品ファイルのダウンロード形式、サポート: PNG 、 WEBPこのパラメータは、画像をダウンロードするときに使用されるインターフェイスに影響し、固定された画像形式ではありません。 | PNG |
| 画像_ダウンロード | ブール | グラフィックワークファイルダウンロードスイッチ | 真実 |
| ビデオ_ダウンロード | ブール | 動画作品ファイルダウンロードスイッチ | 真実 |
| ライブダウンロード | ブール | グラフィック、テキスト、アニメーション ファイルのダウンロード スイッチ | 間違い |
| フォルダーモード | ブール | 各作品のファイルを別のフォルダーに保存するかどうか。フォルダー名はファイル名と一致する必要があります。 | 間違い |
| ダウンロード_レコード | ブール | ダウンロードに成功した作品のIDを記録するかどうか。 オンにすると、既存の記録を持つ作品のダウンロードは自動的にスキップされます。 | 真実 |
| 言語 | str | 現在サポートされているプログラム言語を設定します: zh_CN 、 en_GB | zh_CN |
その他の手順: user_agentパラメータを取得する例。実際のブラウザ情報に従って設定することを強くお勧めします。
バージョン2.2からは、プロジェクト機能に異常がなければ、追加で Cookie を処理する必要はありません。
https://www.xiaohongshu.com/exploreにアクセスします。F12を押して開発者ツールを開きます网络タブを選択します保留日志チェックを入れます过滤入力ボックスにcookie-name:web_sessionと入力します。Fetch/XHRフィルターを選択します网络タブで任意のパケットを選択します (パケットがない場合は、手順 7 を繰り返します)。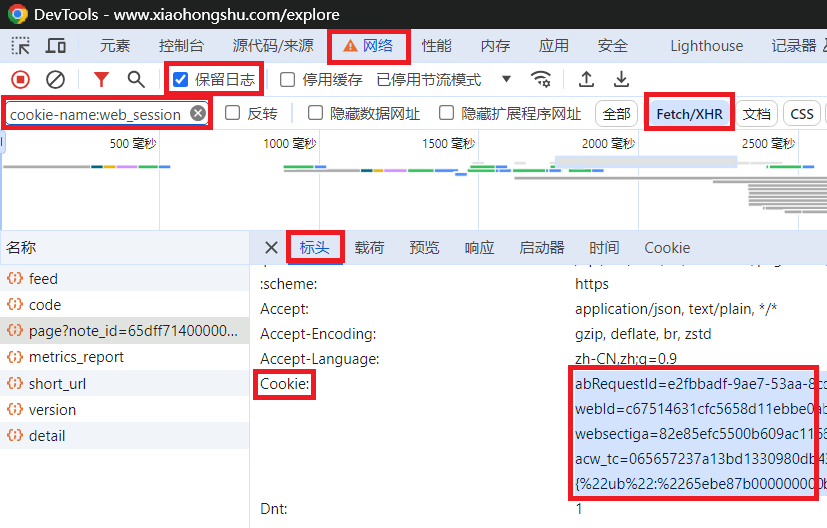
XHS-Downloaderは、ダウンロードした作品のIDをデータベースに保存します。同じ作品を繰り返しダウンロードする場合、(作品ファイルが存在しない場合でも)XHS-Downloaderは自動的にその作品のファイルダウンロードをスキップします。作品ファイルを再度ダウンロードしてください。まずデータベース内の該当する作品IDを削除してから、XHS-Downloaderを使用して作品ファイルをダウンロードしてください。
この機能はデフォルトで有効になっており、無効になっている場合、XHS-Downloader はファイルが存在するかどうかを確認し、ファイルが存在する場合はダウンロードをスキップします。
XHS-Downloaderが役に立った場合は、スターを付けることを検討してください。ご支援ありがとうございます。
| 微信 | アリペイ |
|---|---|
 |  |
ご希望であれば、 XHS-Downloaderの追加サポートに資金を提供することを検討してください。
注: QQ グループ チャットは、プロジェクトの使用上の問題について話し合うことに限定されています。広告を掲載することは固く禁じられています。また、アカウントの取引、アカウントのトラフィック、トラフィックの収益化、グレーな業界、その他の関連コンテンツについて話し合うことも固く禁じられています。
著者の他のオープンソース プロジェクト:
JetBrains は、世界的なオープンソース コミュニティによって認められたアクティブなプロジェクトをサポートし、非営利開発用の無料ライセンスを提供します。


