paper tips and tricks
1.0.0
このリポジトリには、科学論文を執筆する際に役立つ/重要であると考えられたツール、ベスト プラクティス、ヒント、その他のガイドラインのリストが含まれています。スタイルの問題もあり (私たちはシカゴ スタイルマニュアルのガイドラインに従う傾向があります)、他の人が異なるやり方を好むことも承知していますが、一貫したガイドを提供するためにとにかくリストに挙げています。私たちが書いたことすべてに自由に適応、変更、無視、さらには異議を唱えることもできます。
植字とは、活字、つまり文字や記号を配置してテキストを構成することです。これは主に美学の問題ですが、美しいタイポグラフィーは文書をより読みやすく快適にし、読者がメッセージを理解するのに役立ちます。
以下に、文書を作成する際に役立つ植字のヒントとツールをいくつか示します。一部のヒントは LaTeX に固有のものですが、その他のヒントは使用しているものに関係なく適用されます。
LaTeX 文書を作成するときは、ソース ファイルに 1 行に 1 つの文を記述します。書く:
This is my first sentence.
This is the second one.
そしてそうではありません:
This is my first sentence. This is the second one.
この主な理由は、ソース管理とコラボレーションです。コミットの変更を確認するとき、それぞれが別の行にあると、どの文が変更されたかを特定するのがはるかに簡単になります。これにより、同僚は変更をより簡単に確認できるようになります。
もう 1 つの利点は、LaTeX コンパイラによって行番号が与えられるだけで、エラーをより適切に特定できることです。
以下では 2 つのタイプの大文字化について説明します。
すべてのセクション、サブセクションなどのタイトルにタイトル形式を使用します。適切な単語を大文字にするには、capitalizemytitle.com という便利な Web サイトがあります。
場合によっては、オブジェクトの名前 (図、表、グラフ、アルゴリズムなど) とその参照番号が 2 行に分割されることがあります。たとえば、オブジェクトの名前が 1 行に表示され、参照番号が次の行に表示される場合があります。
LaTeX がオブジェクトの名前とその参照の両方を同じ行に保持するようにするには、オブジェクトと参照の間に文字~を使用できます。このようにチルダ文字~使用すると、不自然な改行を避け、LaTeX 文書内のオブジェクト名と参照番号の一貫した書式を維持できます。
Figure~ ref { fig:example } displays that the project ...チルダ文字の使用を忘れないようにするために、自動化用のカスタム コマンドを作成してプロセスを簡素化できます。以下に例を示します。
newcommand { refalg }[1]{Algorithm~ ref {# 1 }}
newcommand { refapp }[1]{Appendix~ ref {# 1 }}
newcommand { refchap }[1]{Chapter~ ref {# 1 }}
newcommand { refeq }[1]{Equation~ ref {# 1 }}
newcommand { reffig }[1]{Figure~ ref {# 1 }}
newcommand { refsec }[1]{Section~ ref {# 1 }}
newcommand { reftab }[1]{Table~ ref {# 1 }}これらのコマンドを定義したら、次のように記述する代わりに、次のようにします。
Figure~ ref { fig:example }次のように入力するだけです。
reffig {fig:example}(完全な例)
booktabs は、すっきりとした見栄えの良いテーブルを作成するのに役立ちます。
usepackage { booktabs }
% --
begin { table }
centering
begin { tabular }{lcc}
toprule
& multicolumn {2}{c}{Data} \ cmidrule (lr){2-3}
Name & Column 1 & Another column \
midrule
Some data & 10 & 95 \
Other data & 30 & 49 \
addlinespace
Different stuff & 99 & 12 \
bottomrule
end { tabular }
caption {My caption.}
label { tab-label }
end { table }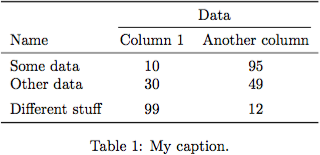
一般に、表に垂直線を使用することは避けてください。代わりに、列をグループ化したい場合は、 cmidrule使用してヘッダー内でグループ化を行います。 addlinespaceを使用して、水平線をスペースに置き換えることもできます。
列見出しでは、文形式の大文字を使用する必要があります (http://www.chicagomanualofstyle.org/15/ch13/ch13_sec019.html を参照)。
テーブルの書式設定に関する詳細なアドバイスは、http://www.inf.ethz.ch/personal/markusp/teaching/guides/guide-tables.pdf でご覧いただけます。これらのルールの一部を説明する素晴らしい GIF を次に示します。
(完全な例)
siunitx パッケージを使用して、すべての数値、通貨、単位などをフォーマットします。
usepackage { siunitx }
% ---
This thing costs SI {123456}{ $ }.
There are num {987654} people in this room, SI {38}{ percent } of which are male.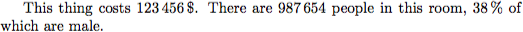
数値を四捨五入するためにも使用できます。
usepackage { siunitx }
% ---
sisetup {
round-mode = places,
round-precision = 3
} %
You can also round numbers, for example num {1.23456}.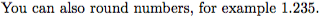
最後に、表内の数値をより適切に配置するのに役立ちます。
usepackage { booktabs }
usepackage { siunitx }
% ---
begin { table }
centering
begin { tabular }{lS}
toprule
Name & {Value} \ % headers of S columns have to be in {}
midrule
Test & 2.3456 \
Blah & 34.2345 \
Foo & -6.7835 \
Bar & 5642.5 \
bottomrule
end { tabular }
caption {Numbers alignment with texttt { siunitx }.}
end { table }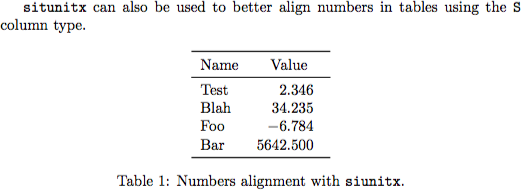
(完全な例)
方程式を書くとき、変数、ベクトル、行列などを首尾一貫した一貫した方法で書くと役立ちます。これは、読者が何について話しているのかを特定し、各記号の意味を思い出すのに役立ちます。
数学を記述するために次のルールを提案します。
$x$ )$mathbold{x}$ )$mathbold{X}$ )$X$ ) mathboldコマンドはfixmathパッケージに由来しており、 boldmathまたはbmに似ていますが、すべての記号がギリシャ文字も含めて斜体になっている点が異なります (他のパッケージはギリシャ文字を斜体にしません)。
変数にインデックスまたは指数を追加するときは、変数のスタイルの外側に追加するようにしてください。つまり、 $mathbold{x_i}$ではなく$mathbold{x}_i$と書きます。
変数を参照することが多いため、次の 2 つのコマンドを定義することをお勧めします。
renewcommand { vec }[1]{ mathbold {#1}}
newcommand { mat }[1]{ mathbold {#1}}これで、文書内で$vec{x}$と$mat{X}$使用できるようになります。行列のフォーマット方法を変更する場合は、 matコマンドを変更するだけで文書全体が更新されます。
また、最もよく使用する変数のコマンドを定義することをお勧めします。たとえば、 vec{x}とmat{X}を頻繁に使用する場合は、次のコマンドを定義することを検討してください。
newcommand { vx }{ vec {x}}
newcommand { vX }{ mat {X}}その後、よりコンパクトな方程式$vx^T vy = vZ$を作成できます。
常に変数の型に応じてスタイルを設定する必要があることに注意してください。たとえば、ベクトルvxの $i$ 番目の要素はx_iであり、 vx_i (数値です) ではありません。同様に、行列vXがある場合、そのi番目の列vx_i (ベクトルなので太字) を呼び出すことができ、その要素x_{ij}の場合はvX_iとvX_{ij}ではなく呼び出すことができます。
インライン方程式を記述するには(...)を使用します。 $...$使用することもできますが、これは TeX コマンドであり、よりわかりにくいエラー メッセージが表示されます。
中央揃えの方程式を独自の行に記述するには、 $$...$$使用しないでください (これは LaTeX 使用の大罪の 1 つです)。機能しますが、間隔が間違っています。代わりにbegin{equation*}またはbegin{align*}を使用してください。
(完全な例)
修士論文や博士論文などの長い文書の場合、参考文献がどこで引用されたかを示すために参考文献に後方参照があると便利です。これを行うには、オプションbackref=page hyperrefパッケージに追加するだけです。
usepackage [ backref=page ]{ hyperref }次のコマンドを使用して、後方参照の表示方法をカスタマイズできます。
renewcommand *{ backref }[1]{}
renewcommand *{ backrefalt }[4]{{ footnotesize [ %
ifcase #1 Not cited. %
or Cited on page~#2 %
else Cited on pages #2 %
fi %
]}}
図は結果を読者に伝えることができるため、あらゆる論文にとって重要な要素です。各図の情報が読者に何を伝えるのか、メッセージを裏付けるのに十分な情報があり、それ以上ではないことを考慮する必要があります。たとえば、2 次元の点 (2 つのクラスターが十分に分離されている) でパターンを表示したい場合、軸に目盛や値を配置する必要はありません (スケールはあまり重要ではありません)。図はあまり複雑であってはなりません。 1 つまたは 2 つのメッセージを伝える複数の図がある方が、1 つの大きな乱雑な図よりも優れています (方法 A は B よりも優れていますが、収束が遅くなります)。
一部の図は、システムを説明したり、全体像を示したりするために手作りされていますが、他の図はデータ駆動型、つまり何らかのデータを図解するために作成されています。これらのデータ駆動型 Figure は、可能な限りスクリプト化する必要があります。理想的には、データが変更された場合、他の介入 (ビューの設定、ズーム、Figure の保存/トリミングなど) を行わずに、スクリプトを 1 回実行するだけで Figure を更新できるようにする必要があります。 、など)。同様に、図の生成に必要なデータの生成に数秒以上かかる場合は、データを計算して保存する最初のスクリプトと、それをプロットする 2 番目のスクリプトが必要です。こうすることで、プロットでの作業にかかる時間を大幅に節約できます。Figure に小さな変更を加えるたびに、その効果を確認するまで待つ必要がなくなります。
また、特にスクリプトに引数が必要な場合は、図の生成に使用したコマンドを LaTeX ファイルに保存することをお勧めします。たとえば、図の上のコメントとして保存することをお勧めします。
documentclass { article }
usepackage { graphicx }
begin { document }
% python figure_example.py --save ../../examples/figure/figure.eps
begin { figure }
centering
includegraphics {figure.eps}
caption {Example of a sigmoid function}
end { figure }
end { document }可能であれば、すべての図のラベルや軸などに同じフォントを使用する必要があります。特に、ある図に大きなラベル/目盛があり、別の図に小さなラベル/目盛が付いていることは避けてください。これを実現する 1 つの解決策は、Figure を生成するスクリプトで Figure のサイズを定義し、ドキュメント内でサイズを変更しないことです (たとえば、LaTeX ドキュメントで Figure の幅をtextwidthに設定するのは変更しないでください)。
一貫した数値を得るには、 plot_utils.pyのようなヘルパー スクリプトを使用することをお勧めします。このスクリプトを使用すると、 figure_setup()関数を呼び出してすべてのサイズを定義し、必要なサイズの Figure を作成して保存するだけです。
import argparse
import matplotlib . pyplot as plt
import numpy as np
import plot_utils as pu
def main ( args ):
x = np . linspace ( - 6 , 6 , 200 )
y = 1 / ( 1 + np . exp ( - x ))
pu . figure_setup ()
fig_size = pu . get_fig_size ( 10 , 5 )
fig = plt . figure ( figsize = fig_size )
ax = fig . add_subplot ( 111 )
ax . plot ( x , y , c = 'b' , lw = pu . plot_lw ())
ax . set_xlabel ( '$x$' )
ax . set_ylabel ( '$ \ sigma(x)$' )
ax . set_axisbelow ( True )
plt . grid ()
plt . tight_layout ()
if args . save :
pu . save_fig ( fig , args . save )
else :
plt . show ()
if __name__ == '__main__' :
parser = argparse . ArgumentParser ()
parser . add_argument ( '-s' , '--save' )
args = parser . parse_args ()
main ( args )すべての図をEPS形式で保存することをお勧めします。このようにして、 latexとpdflatex両方を使用してドキュメントを生成し、美しいベクター グラフィックスとテキストを楽しむことができます。
2015 年 9 月の時点で、Mac OS X および Python、Matplotlib、TeX Live の最新バージョンでは、Matplotlib からPDFとして直接保存された図を印刷すると品質が低下します。実際の紙に印刷すると鮮明になります。自分で試してみてください。これは、Matplotlib で生成された画像をEPSで保存することを好むもう 1 つの理由です。本当に図の PDF バージョンのみを保持したい場合は、 epspdfコマンド ライン ツールを使用してください。結果として得られる PDF は、Matplotlib によって直接生成されたものよりも優れたものになります。
完全を期すために、わずかに優れた結果を生成する別の Matplotlib バックエンド PGF があることに注意してください。ただし、2015 年 9 月の時点では、結果として得られる PDF は、デフォルトのバックエンドとepspdfで取得した PDF の 2 倍の重さになります。
Matplotlib は、タイトなレイアウト機能を使用している場合でも、余白に余分な空白を追加することがあります。 PDF を最も狭い境界ボックスに合わせてトリミングする気の利いたコマンドライン ツールpdfcrop 。
プロット内に多くのデータ ポイントがある場合、生成される EPS ファイルは非常に大きくなる可能性があります。 Figure を PNG ファイルとして保存することもできますが、テキストがぼやけてしまいます。解決策は、Figure の一部をラスタライズすることです。つまり、データ ポイントを EPS ファイルのビットマップとしてレンダリングし、残りはベクター形式でレンダリングする必要があることをmatplotlib指示します。
matplotlibのほとんどのプロット関数にrasterized=Trueキーワードを渡すことができます。 zorder使用してさまざまなレイヤーを使用し、軸のset_rasterization_zorder()メソッドを使用して特定のzorderの下のすべてのレイヤーをラスタライズするようにmatplotlib指示することもできます。ラスタライズの例については、figure_rasterized_example.py および http://matplotlib.org/examples/misc/rasterization_demo.html を参照してください。


