similarity
1.1.6
類似性、テキスト文字列間の類似性スコアを計算します。Java で書かれています。
類似度計算ツールキットである類似度は、Java で記述されたテキスト類似度計算、感情分析などに使用できます。
類似度は、一連のアルゴリズムから構成される Java 版の類似度計算ツールキットであり、自然言語処理における類似度計算手法の普及を目的としています。類似性には、実用的なツール、効率的なパフォーマンス、明確な構造、最新のコーパス、およびカスタマイズ可能性という特徴があります。
類似性は次の機能を提供します。
単語類似度計算
フレーズ類似度計算
文類似度計算
段落類似度の計算
CNKIイーユアン
感情分析
近似的な単語
豊富な機能を提供する一方で、 Similarity の内部モジュールは低結合を重視し、モデルは遅延読み込みを重視し、辞書はプレーン テキストでの公開を重視します。これらは使いやすく、ユーザーが独自のコーパスをトレーニングするのに役立ちます。
Jarパッケージの導入
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >グラドルの紹介:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}テキストの長さ: 単語の粒度
シノニム Cilin に基づく類似度計算方法である Cilin 類似度: org.xm.Similarity.cilinSimilarityを使用することをお勧めします。
例: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
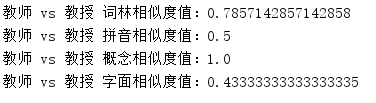
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
テキストの長さ: フレーズの粒度
フレーズ類似度: org.xm.Similarity.phraseSimilarityを使用することをお勧めします。これは本質的に、同じ文字と同じ文字の位置を通じて 2 つのフレーズの類似性を計算する方法です。
例: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
テキストの長さ: 文の粒度
語形と語順の文の類似性: org.xm.similarity.morphoSimilarityを使用することをお勧めします。これは、2 つの文の同じテキスト リテラルを考慮するだけでなく、同じテキストが出現する順序も考慮する類似性メソッドです。
例: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
テキストの長さ: 段落の粒度 (段落、25 文字 < 長さ (テキスト) < 500 文字)
単語形式の語順文の類似性: org.xm.similarity.text.CosineSimilarityを使用することをお勧めします。これは、2 つの段落内の同じテキストを考慮し、単語の分割、単語の頻度、品詞の重み付けを通じて重み付けを行う方法です。コサインを使用して類似度を計算します。
例: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875例: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}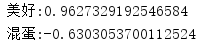
この例は、セメム ツリーに基づく単語単位のセンチメント極性分析です。テキストセンチメント分析に関しては、ディープ ニューラル ネットワーク モデルと SVM 分類アルゴリズムを使用して、より良い結果を達成する pytextclassifier があります。
例: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Word2vec 単語ベクトル トレーニングは、word2vec トレーニング ツール Word2VEC_java の Java バージョンであり、トレーニング コーパスは新しい Tian Long Ba Bu であり、同義語は単語ベクトルを通じて取得されます。 ユーザーはカスタム コーパスをトレーニングしたり、中国語の Wikipedia を使用してユニバーサル単語ベクトルをトレーニングしたりできます。
テキストの類似性の尺度

ライセンス契約は Apache License 2.0 で、商用利用は無料です。類似リンクとライセンス契約を製品説明に添付してください。
プロジェクトのコードはまだ非常にラフです。コードに改善点があれば、このプロジェクトに提出してください。提出する前に、次の 2 つの点に注意してください。
testに追加しますその後、PR を送信できます。


