cherche
2.2.1
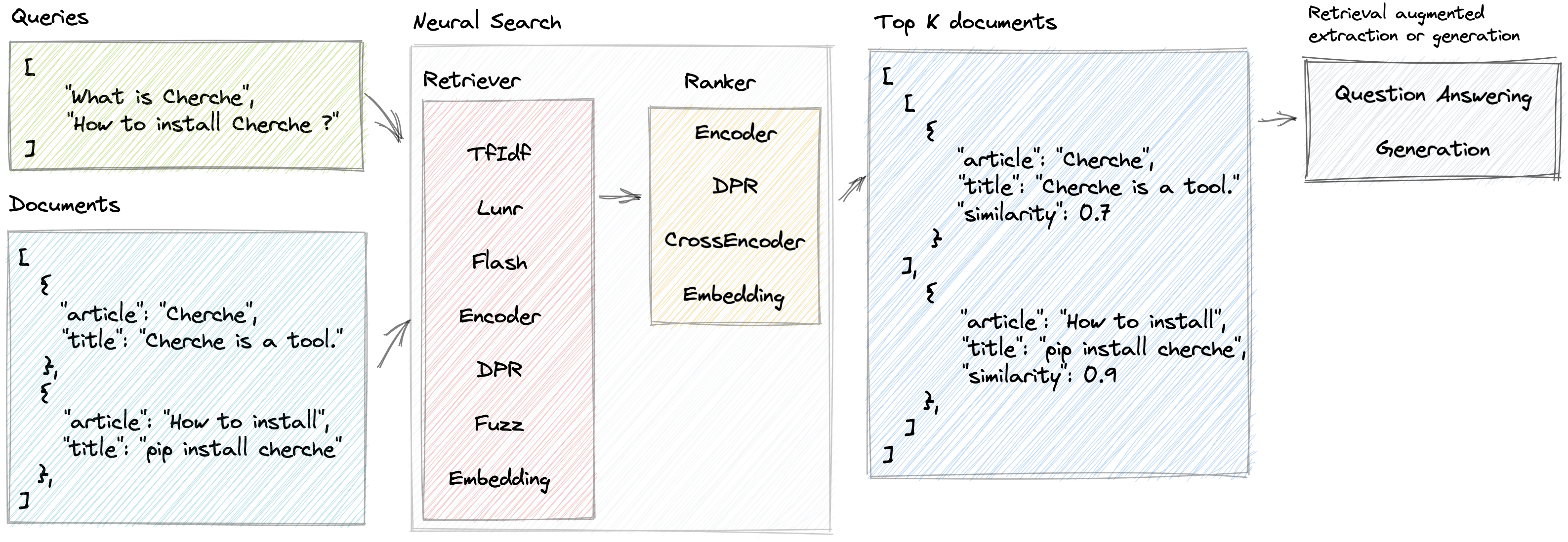
神経検索

Cherche を使用すると、レトリーバーと事前トレーニングされた言語モデルをレトリーバーとランカーの両方として使用するニューラル検索パイプラインの開発が可能になります。 Cherche の主な利点は、エンドツーエンドのパイプラインを構築できることにあります。さらに、Cherche はバッチ計算との互換性があるため、オフライン セマンティック検索に適しています。
Cherche が提供する機能の一部を次に示します。
Cherche を利用した NLP 検索エンジンのライブ デモ
TfIdf、Flash、Lunr、Fuzz などの CPU 上の単純な取得ツールで使用するために Cherche をインストールするには、次のコマンドを使用します。
pip install chercheCPU 上のセマンティック リトリーバーまたはランカーで使用するために Cherche をインストールするには、次のコマンドを使用します。
pip install " cherche[cpu] "最後に、GPU でセマンティック リトリーバーまたはランカーを使用する予定がある場合は、次のコマンドを使用します。
pip install " cherche[gpu] "これらのインストール手順に従うことで、ニーズに応じた適切な要件で Cherche を使用できるようになります。
ドキュメントはここから入手できます。レトリーバー、ランカー、パイプライン、および例について詳しく説明します。
Cherche を使用すると、オブジェクトのリスト内で適切なドキュメントを見つけることができます。以下はコーパスの例です。
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]以下は、ドキュメントを迅速に取得する TF-IDF とそれに続くランキング モデルで構成されるニューラル検索パイプラインの例です。ランキング モデルは、クエリとドキュメント間の意味上の類似性に基づいて、取得者によって生成されたドキュメントを並べ替えます。クエリのリストを使用してパイプラインを呼び出し、各クエリに関連するドキュメントを取得できます。
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]インデックスをドキュメントにマップし、パイプラインを使用してコンテンツにアクセスできます。
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche は、クエリに基づいて入力ドキュメントをフィルタリングする取得機能を提供します。
Cherche は、Retriever の出力でドキュメントをフィルター処理するランカーを提供します。
Cherche ランカーは、Hugging Face ハブで利用できる SentenceTransformers モデルと互換性があります。
Cherche は、質問応答専用のモジュールを提供します。これらのモジュールは、Hugging Face の事前トレーニング済みモデルと互換性があり、ニューラル検索パイプラインに完全に統合されています。
Cherche はルノーのために、またはルノーによって作成され、現在では誰でも利用できるようになりました。すべての貢献を歓迎します。

Lunrretriever は、Lunr.py のラッパーです。 Flash レトリバーは、FlashText のラッパーです。 DPR、Encode、および CrossEncoder ランカーは、ニューラル検索パイプラインでの SentenceTransformers の事前トレーニング済みモデルの使用専用のラッパーです。
cherche を使用して科学出版物の結果を生成する場合は、SIGIR の論文を参照してください。
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}Cherche 開発チームは、Raphaël Sourty、François-Paul Servant、Nicolas Bizzozzero、Jose G Moreno で構成されています。 ?


