full stack on prem cv mlops
1.0.0
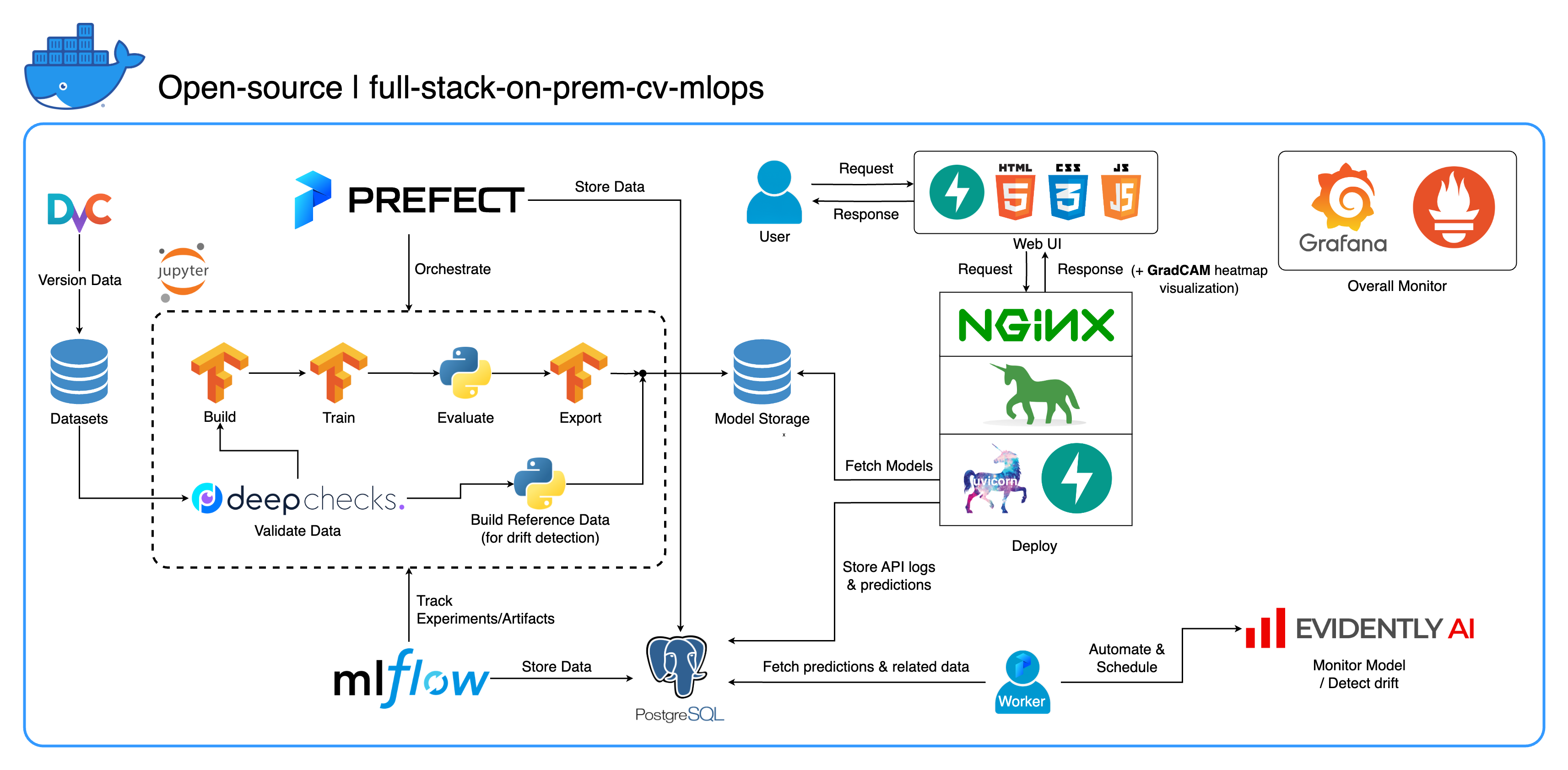
画像分類に重点を置き、コンピューター ビジョン タスク専用に設計された包括的なオンプレミス MLOps エコシステムへようこそ。このリポジトリには、Jupyter Lab/Notebook の開発ワークスペースから運用レベルのサービスまで、必要なものがすべて用意されています。一番いいところは? 「1 つの設定と 1 つのコマンド」だけで、モデルの構築からデプロイまでシステム全体を実行できます。柔軟性を維持しながら拡張性と信頼性を確保するために、多数のベスト プラクティスを統合しました。私たちの主なユースケースは画像分類を中心に展開していますが、私たちのプロジェクト構造は、オンプレミスからクラウドへの移行も含め、幅広い ML/DL 開発に簡単に適応できます。
もう 1 つの目標は、これらすべてのツールを統合し、1 つの完全なシステムで連携して動作させる方法を示すことです。特定のコンポーネントやツールに興味がある場合は、プロジェクトのニーズに合ったものを自由に選んでください。
システム全体が単一の Docker Compose ファイルにコンテナ化されます。これを設定するには、 docker-compose up実行するだけです。これは完全なオンプレミス システムであるため、クラウド アカウントは必要なく、システム全体を使用するのに一銭もかかりません。
包括的な概要を取得し、このシステムをプロジェクトに適用する方法を理解するには、 「デモ ビデオ」セクションのデモ ビデオを視聴することを強くお勧めします。これらのビデオには重要な詳細が含まれていますが、長すぎてここで説明するには十分に明確ではない可能性があります。
デモ: https://youtu.be/NKil4uzmmQc
詳細な技術ウォークスルー: https://youtu.be/l1S5tHuGBA8
ビデオ内のリソース:
このリポジトリを使用するには、Docker のみが必要です。参考までに、Mac M1 ではDocker バージョン 24.0.6、ビルド ed223bcおよびDocker Compose バージョン v2.21.0-desktop.1を使用します。
このプロジェクトでは、いくつかのベスト プラクティスを実装しました。
tf.dataを使用した効率的なデータ ローダー/パイプラインimgaug lib による画像拡張os.envを使用するprintの代わりにloggingモジュールを使用したロギングdocker-compose.yml内の変数の.envによる動的構成default.conf.templateを使用して、Nginx config で環境変数をエレガントに適用する (Nginx 1.19 の新機能)ほとんどのポートは、このリポジトリのルートにある .env ファイルでカスタマイズできます。デフォルトは次のとおりです。
123456789 )[email protected] 、パスワード: SuperSecurePwdHere )admin 、pw: admin )ARM ベースのコンピュータを使用していない場合 (開発には Mac M1 を使用しています)、 docker-compose.ymlのplatform: linux/arm64行をコメントすることを検討する必要があります。そうでなければ、このシステムは機能しません。
--recurse-submodulesフラグを使用することを検討してください: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdocker-compose.ymlのjupyterサービスの下のdeployセクションのコメントを解除し、 services/jupyter/Dockerfileのベース イメージをubuntu:18.04からnvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04に変更できます。 nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (テキストはファイル内にあります。コメントする必要があるのは、コメントを解除してください) GPU を活用します。 nvidia-container-toolkit を機能させるには、ホスト マシンにnvidia-container-toolkitインストールする必要がある場合もあります。 Windows/WSL2 ユーザーにとって、この記事は非常に役立ちます。docker-compose upまたはdocker-compose up -dを実行してターミナルを切断します。datasets/animals10-dvcにある DvC サブモジュールに移動し、 「使用方法」セクションの手順に従います。 http://localhost:8888/labcd ~/workspace/に移動します。docker-compose.ymlで構成可能です) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamlを実行します。tasksディレクトリ内に作成する必要がありますflowsディレクトリ内に作成されたフローから呼び出されることになっています。run_flow.pyを使用して呼び出す必要があります。start(config)関数を実装する必要があります。この関数は、構成を Python dict として受け入れ、基本的にそのファイル内の特定のフローを呼び出します。datasetsディレクトリ内に存在する必要があり、それらはすべてこのリポジトリ内のディレクトリ構造と同じである必要があります。~/ariya/のcentral_storageには、 modelsとref_dataという名前のサブディレクトリが少なくとも 2 つ含まれている必要があります。このcentral_storage開発およびデプロイ環境全体で使用されるすべてのステージングされたファイルを保存するというオブジェクト・ストレージの目的を果たします。 (これは、クラウド上に展開して拡張性を高めたい場合に、クラウド ストレージ サービスへの変更を検討できるものの 1 つです)重要規則を変更する場合は、特に注意してください(これらの規則はシステムのさまざまな部分で結び付けられ、使用されているため)。
central_storageパス -> 内部にはmodels/ ref_data/サブディレクトリがあるはずです<model_name>.yaml 、 <model_name>_uae 、 <model_name>_bbsd 、 <model_name>_ref_data.parquetcurrent_model_metadata_fileおよびmonitor_pool_namecomputer-viz-dl (デフォルト値) という名前のプレインストールされた Conda 環境と、このリポジトリに必要なすべてのパッケージが含まれています。すべての Python コマンド/コードは、この Jupyter 内で実行されることになっています。central_storageボリュームは、開発および展開全体を通じて使用される中央ファイル ストレージとして機能します。これには主にモデル ファイル (ドリフト検出器を含む) と Parquet 形式の参照データが含まれています。モデルのトレーニング ステップの最後に、新しいモデルがここに保存され、デプロイメント サービスがこの場所からモデルをプルします。 (注: これは、拡張性を確保するためにクラウド ストレージ サービスに置き換えるのに理想的な場所です。)modelセクションを使用して、分類子モデルを構築します。モデルはTensorFlowで構築され、そのアーキテクチャはtasks/model.py:build_modelでハードコードされています。datasetセクションを使用して、トレーニング用のデータセットを準備します。このステップではDvC を使用して、構成で指定されたバージョンと比較してディスク内のデータの整合性をチェックします。変更があった場合は、プログラムによって指定されたバージョンに変換されます。データセットを実験する場合に備えて変更を保持したい場合は、設定のdvc_checkoutフィールドをfalseに設定して、DvC がその動作を行わないようにすることができます。trainセクションを使用してデータ ローダーを構築し、トレーニング プロセスを開始します。実験情報と成果物はMLflowで追跡および記録されます。注: DeepChecks からの結果レポート ( .htmlファイル) は、コンベンションの MLflow のトレーニング実験にもアップロードされます。modelセクションからモデル メタデータ ファイルを構築します。central_storageにアップロードします (この場合、 central_storage場所にコピーを作成するだけです。これは、ファイルをクラウド ストレージにアップロードする手順に変更できます)model/drift_detectionセクションに基づいてドリフト検出器を構築します。central_storageに保存してアップロードします。central_storageにアップロードします。central_storageから取得します。 (これはチュートリアルのデモビデオで説明されている懸念事項の 1 つです。詳細についてはビデオをご覧ください)current_model_metadata_fileと、Prefect ワーカーとフローをデプロイするためのワーク プール名を格納するmonitor_pool_nameの 2 つの変数です。deployments/prefect-deploymentsにcd 、構成のdeploy/prefectセクションからの入力を使用してprefect --no-prompt deploy --name {deploy_name}を実行します。このリポジトリではすべてがすでに Docker 化およびコンテナー化されているため、サービスをオンプレミスからオンクラウドに変換するのは非常に簡単です。サービス API の開発とテストが完了したら、Dockerfile からコンテナを構築してservices/dl_service をスピンオフし、それをクラウド コンテナ レジストリ サービス (AWS ECR など) にプッシュできます。それでおしまい!
注:サービス コードを実際の実稼働環境で使用する場合、サービス コードには潜在的な問題が 1 つあります。これについては詳細なビデオで説明していますので、時間をかけてビデオ全体を視聴することをお勧めします。 
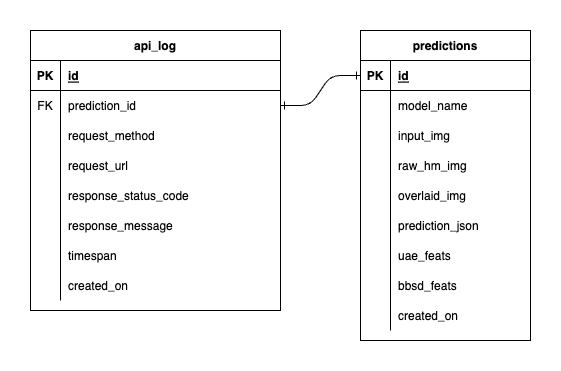
PostgreSQL 内には 3 つのデータベースがあります。1 つは MLflow 用、1 つは Prefect 用、そして 1 つは ML モデル サービス用に作成したものです。最初の 2 つはこれらのツールによって自己管理されるため、ここでは詳しく説明しません。 ML モデル サービスのデータベースは、私たちが独自に設計したものです。
圧倒的な複雑さを避けるため、テーブルを 2 つだけ使用してシンプルにしました。関係と属性を以下の ERD に示します。基本的に、受信したリクエストとサービスの応答に関する重要な詳細を保存することを目的としています。これらのテーブルはすべて自動的に作成および操作されるため、手動セットアップについて心配する必要はありません。
注目すべき点: input_img 、 raw_hm_img 、およびoverlaid_img文字列として保存される Base64 エンコードされたイメージです。 uae_featsとbbsd_featsドリフト検出アルゴリズムの埋め込み機能の配列です。
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS blockエラーが発生した場合は、 export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0を試してから、スクリプト。

