GenAI GeoGuesser
AIが生成したヒットから国名を推測します
このプロジェクトは、Google マップ上のランダムな世界の場所に配置され、時間のカウントダウン中にその場所を推測する人気の GeoGuessr ゲームの別の解釈です。ここでは、AI モデルによって生成されたマルチモーダルなヒントに基づいて国名を推測する必要があります。国の説明をテキストで提供するテキスト、国に似た画像を提供する画像、およびその国に似た画像を提供する音声の 3 つのモダリティから選択できます。その国に関連した音声サンプルです。
このアプリのオンライン デモは、HuggingFace スペースで確認できます。このデモは、パフォーマンス上の理由から画像ヒントのみの生成に制限されていました。
このプロジェクトがどのように機能するか、どのように作成されたかについてもう少し詳しく知りたい場合は、「生成 AI ベースの GeoGuesser の構築」という記事をチェックしてください。
ワークフロー
- 必要なヒントのモダリティを選択します。
- 各モダリティのヒントの数を選択します。
- 「ゲームを開始」ボタンをクリックします。
- すべてのヒントを見て、「国推測」フィールドに推測を入力します。
- 「推測する」ボタンをクリックします。
デモ
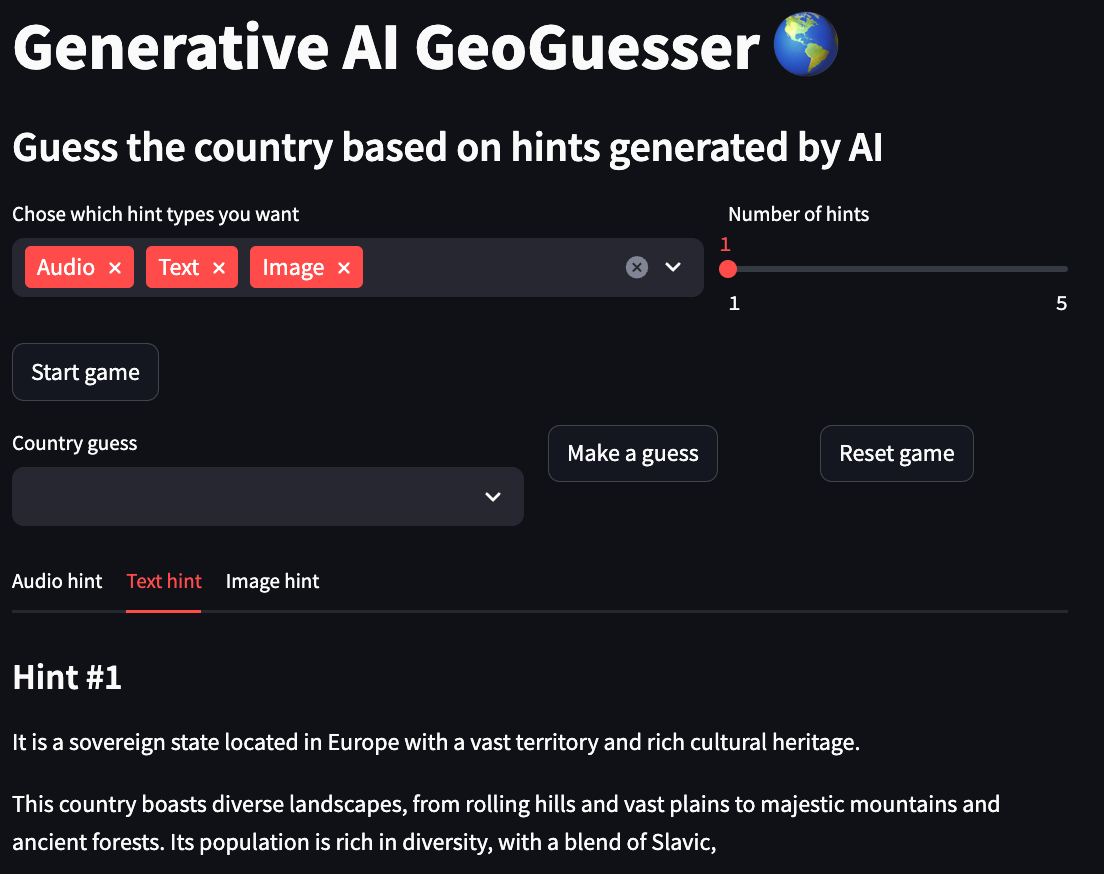
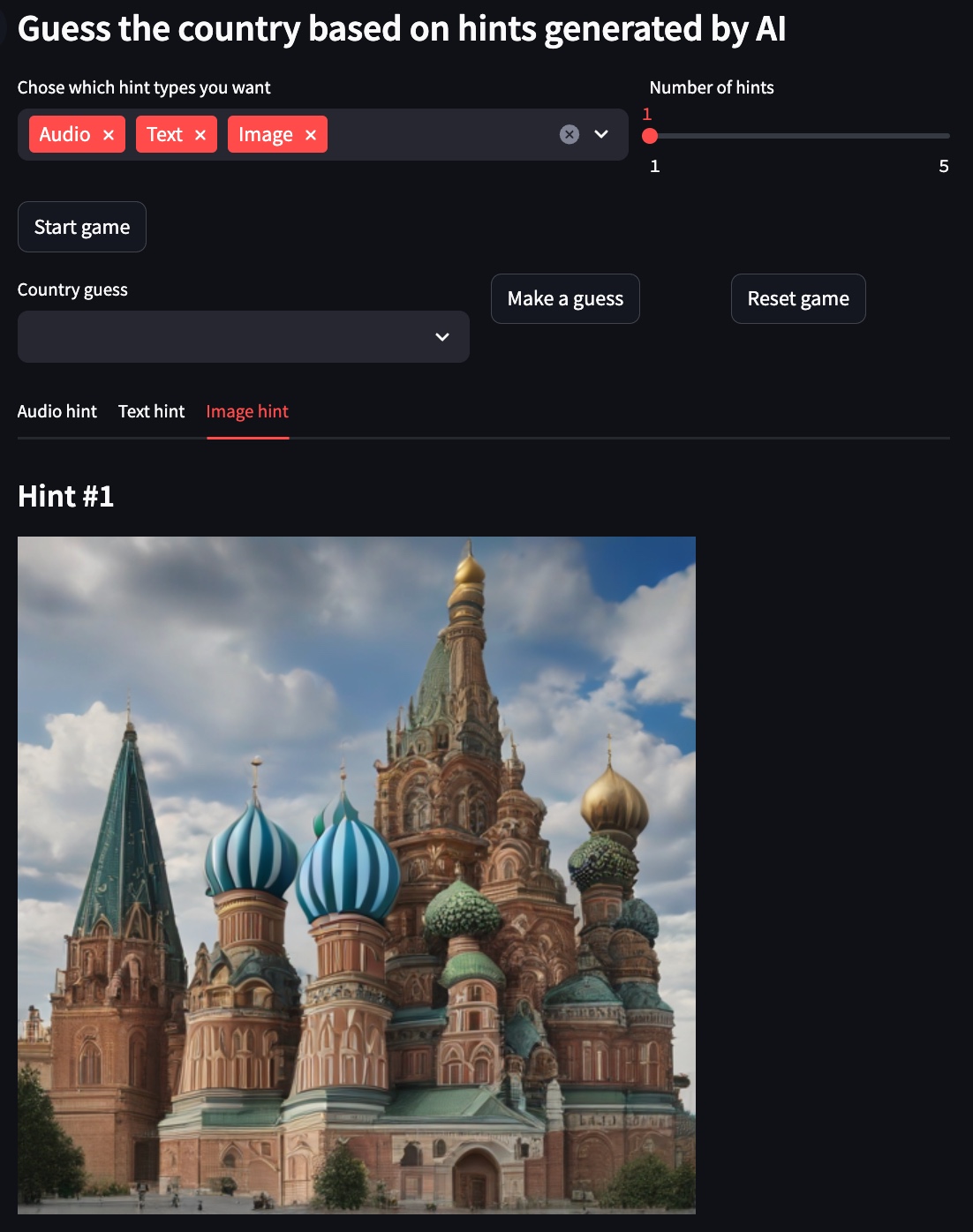
以下の例では、選択された国はロシアです。
テキストヒント
画像のヒント
音声ヒント
使用法
このリポジトリを使用するための推奨されるアプローチは Docker を使用することですが、カスタム venv を使用することもできます。ただし、すべての依存関係を必ずインストールしてください。
構成
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- 地元
- to_use:プロジェクトがこのセットアップ構成を使用する必要があるかどうか
- 文章
- model_id:テキストヒントの作成に使用されるモデル
- device:モデルによって使用されるデバイス、通常は (cpu、cuda、mps) のいずれか
- max_output_tokens:モデルによって生成されるトークンの最大数
- 温度:温度は、トークン選択のランダム性の程度を制御します。温度が低いと、真実または正しい応答を期待するプロンプトに適していますが、温度が高いと、より多様な結果や予期しない結果が生じる可能性があります。温度が 0 の場合、最も確率の高いトークンが常に選択されます。
- top_p: Top-p は、モデルが出力用のトークンを選択する方法を変更します。トークンは、確率の合計が上位 p 値と等しくなるまで、最も確率の高いものから最も低いものまで選択されます。たとえば、トークン A、B、および C の確率が 0.3、0.2、および 0.1 で、top-p 値が 0.5 の場合、モデルは (温度を使用して) 次のトークンとして A または B のいずれかを選択します。 )
- top_k: Top-k は、モデルが出力用のトークンを選択する方法を変更します。 top-k が 1 の場合は、選択されたトークンがモデルの語彙内のすべてのトークンの中で最も可能性が高いことを意味します (貪欲デコードとも呼ばれます)。一方、top-k が 3 の場合は、最も可能性の高い 3 つのトークンの中から次のトークンが選択されることを意味します (温度を使用)
- 画像
- model_id:画像ヒントの作成に使用されたモデル
- device:モデルによって使用されるデバイス、通常は (cpu、cuda、mps) のいずれか
- num_inference_steps:モデルの推論ステップ数
- guide_scale:画質や多様性を犠牲にして、生成をプロンプトとよりよく一致させるように強制します。
- オーディオ
- model_id:音声ヒントの作成に使用されるモデル
- device:モデルによって使用されるデバイス、通常は (cpu、cuda、mps) のいずれか
- num_inference_steps:モデルの推論ステップ数
- audio_length_in_s:オーディオヒントの継続時間の長さ
- 頂点
- to_use:プロジェクトがこのセットアップ構成を使用する必要があるかどうか
- project: Vertex AI で使用されるプロジェクト名
- location: Vertex AI によって使用されるプロジェクトの場所
- 文章
- model_id:テキストヒントの作成に使用されるモデル
- max_output_tokens:モデルによって生成されるトークンの最大数
- 温度:温度は、トークン選択のランダム性の程度を制御します。温度が低いと、真実または正しい応答を期待するプロンプトに適していますが、温度が高いと、より多様な結果や予期しない結果が生じる可能性があります。温度が 0 の場合、最も確率の高いトークンが常に選択されます。
- top_p: Top-p は、モデルが出力用のトークンを選択する方法を変更します。トークンは、確率の合計が上位 p 値と等しくなるまで、最も確率の高いものから最も低いものまで選択されます。たとえば、トークン A、B、および C の確率が 0.3、0.2、および 0.1 で、top-p 値が 0.5 の場合、モデルは (温度を使用して) 次のトークンとして A または B のいずれかを選択します。 )
- top_k: Top-k は、モデルが出力用のトークンを選択する方法を変更します。 top-k が 1 の場合は、選択されたトークンがモデルの語彙内のすべてのトークンの中で最も可能性が高いことを意味します (貪欲デコードとも呼ばれます)。一方、top-k が 3 の場合は、最も可能性の高い 3 つのトークンの中から次のトークンが選択されることを意味します (温度を使用)
コマンド
ゲームアプリを起動します。
Docker イメージをビルドします。
コードに lint と書式設定を適用します (開発の場合のみ必要)。


