qwen2 in a lambda
1.0.0
2024 年 11 月 9 日に更新
(日付をマークしたのは、Python の LLM API が非常に高速に動作するためであり、他の誰かがこれを読む頃には重大な変更が導入される可能性があります。)
これは、Docker と SAM CLI を使用して Qwen GGUF モデル ファイルを AWS Lambda に配置する方法に関する小規模な研究です。
https://makit.net/blog/llm-in-a-lambda-function/ から引用
Lambda + Bedrock ではなく、Lambda の機能のみを活用することで、AWS の支出を削減できるかどうかを知りたかったのです。どちらのサービスも長期的にはより多くのコストが発生するためです。
このアイデアは、比較的リソースを多く消費しない小規模な言語モデルを適合させ、できれば 128 ~ 256 MB のメモリ構成で 1 秒未満から 2 秒のレイテンシーを実現するというものでした。
GGUF モデルも使用して、さまざまなレベルの量子化を使用して、メモリにロードされる最適なパフォーマンス/ファイル サイズを調べたいと思いました。
qwen2-1_5b-instruct-q5_k_m.ggufをqwen_fuction/function/にダウンロードします。app.y / LOCAL_PATHのモデル パスを変更します。 qwen_function/function/requirements.txtにインストールします (できれば venv/conda env に)sam build / sam validate実行するsam local start-api実行してローカルでテストしますcurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate実行して、LLM にプロンプトを表示しますsam deploy --guided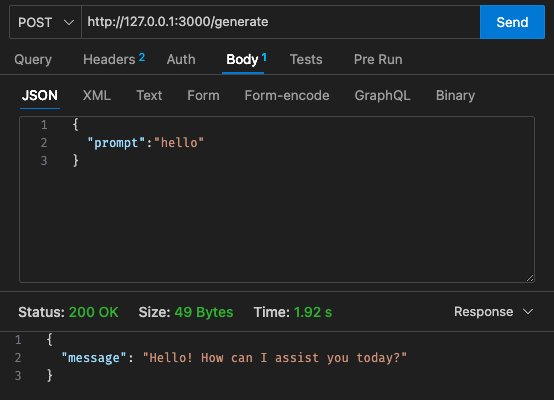
AWS
初期設定 - 128MB、30秒のタイムアウト
調整された構成 #1 - 512MB、30 秒のタイムアウト
調整された構成 #2 - 512MB、30 秒のタイムアウト
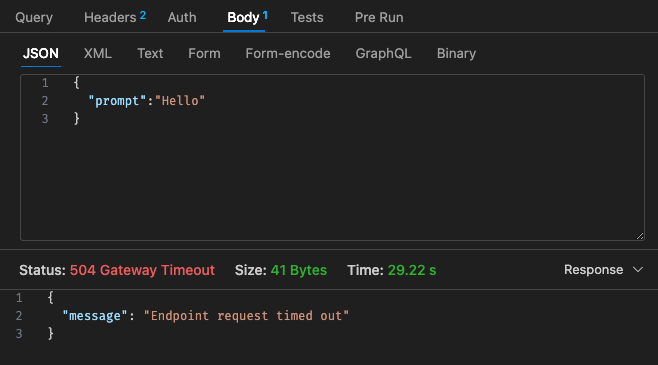
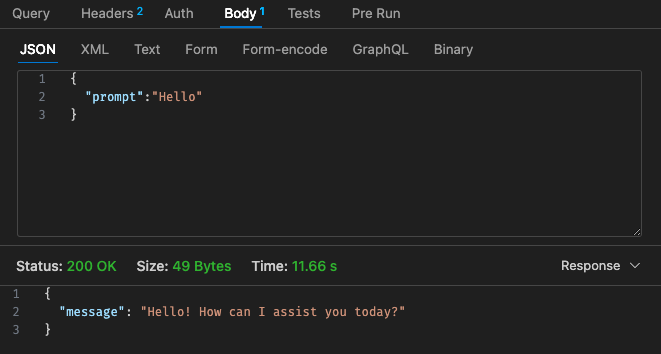
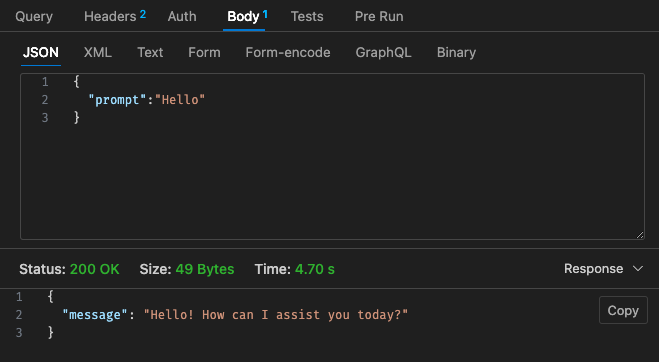
Lambda の料金体系に戻ると、
Qwen を使用した Lambda の料金体系は Claude 3 Haiku と比べて競争力が低いように見えるため、クラウド上で AWS Bedrock などを使用してホスト型 LLM を使用する方が安価になる可能性があります。
さらに、API ゲートウェイのタイムアウトは 30 秒のタイムアウトを超えて簡単に構成できません。ユースケースによっては、これはあまり理想的ではない可能性があります。
ローカル経由の結果はマシンの仕様に依存します。あなたの認識、期待と現実を大きく歪める可能性があります
ユースケースによっては、ラムダの呼び出しと応答ごとのレイテンシにより、ユーザー エクスペリエンスが低下する可能性があります。
全体として、私のサイド プロジェクトの Qwen 1.5b による予算とレイテンシの要件を十分に満たすことはできませんでしたが、これは楽しい小さな実験だったと思います。 @makit のガイドに改めて感謝します。


