genkitx hnsw
1.0.0

このリポジトリでこのプラグインに貢献できます。
HNSW は、ベクトル データベースです。 Hierarchical Navigable Small World (HNSW) グラフは、ベクトル類似性検索で最も優れたパフォーマンスを発揮するインデックスの 1 つです。 HNSW は非常に人気のあるテクノロジーであり、超高速の検索速度と素晴らしいリコールによる最先端のパフォーマンスを何度も生み出します。ニューサウスウェールズ州について詳しく学びましょう。
必要に応じて、このベクター データベースを使用することもできます。
これにより、Generative AI で高性能の検索拡張生成 (RAG) を実現できるため、独自の AI モデルを構築したり、より多くのコンテキストや知識を取得するために AI モデルを再トレーニングしたりする必要はなく、代わりに追加のコンテキスト層を追加して、 AI モデルは、ベース AI モデルが知っている知識よりも多くの知識を理解できます。これは、定義した特定の情報や知識に基づいて、より多くのコンテキストや知識を取得したい場合に便利です。
レストラン アプリケーションまたはウェブサイトをお持ちであれば、レストランに関する特定の情報、住所、料理メニューのリストとその価格、その他の特定の情報を追加できるため、顧客がレストランについて AI に何か質問したときに、AI が正確に答えることができます。 。これにより、チャットボットを構築する手間が省け、代わりに特定の知識で強化された Generative AI を使用できるようになります。
会話例:
You : スラバヤ市にある私のレストランの料金表はいくらですか?
AI :価格表:
プラグインをインストールする前に、次の前提条件がインストールされていることを確認してください。
npm install -g typescript )このプラグインをインストールするには、このコマンドを実行するか、お好みのパッケージ マネージャーを使用して実行できます。
npm install genkitx-hnswこのプラグインには以下のようないくつかの機能があります。
HNSW Indexer提供されたすべてのデータと情報に基づいてベクトル インデックスを作成するために使用されます。このベクトルインデックスは、HNSW レトリバーの知識リファレンスとして使用されます。HNSW Retrieverベクトル インデックスに基づく追加の知識とコンテキストで強化されたベースとして Gemini モデルを使用して生成 AI 応答を取得するために使用されます。 これは、HNSW Vector Store、Gemini Embedder、および Gemini LLM を使用してデータをベクター ストアに保存するための Genkit プラグイン フローの使用法です。
データまたはドキュメントをフォルダーに準備します
プラグインを Genkit プロジェクトにインポートする
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Genkit UI を開き、登録されているプラグインHNSW Indexer選択します。
入力と出力の必須パラメータを使用してフローを実行します
dataPath : AI が学習するデータおよびその他のドキュメントのパスindexOutputPath : 提供されたデータとドキュメントに基づいて処理される Vector Store インデックスの予想される出力パス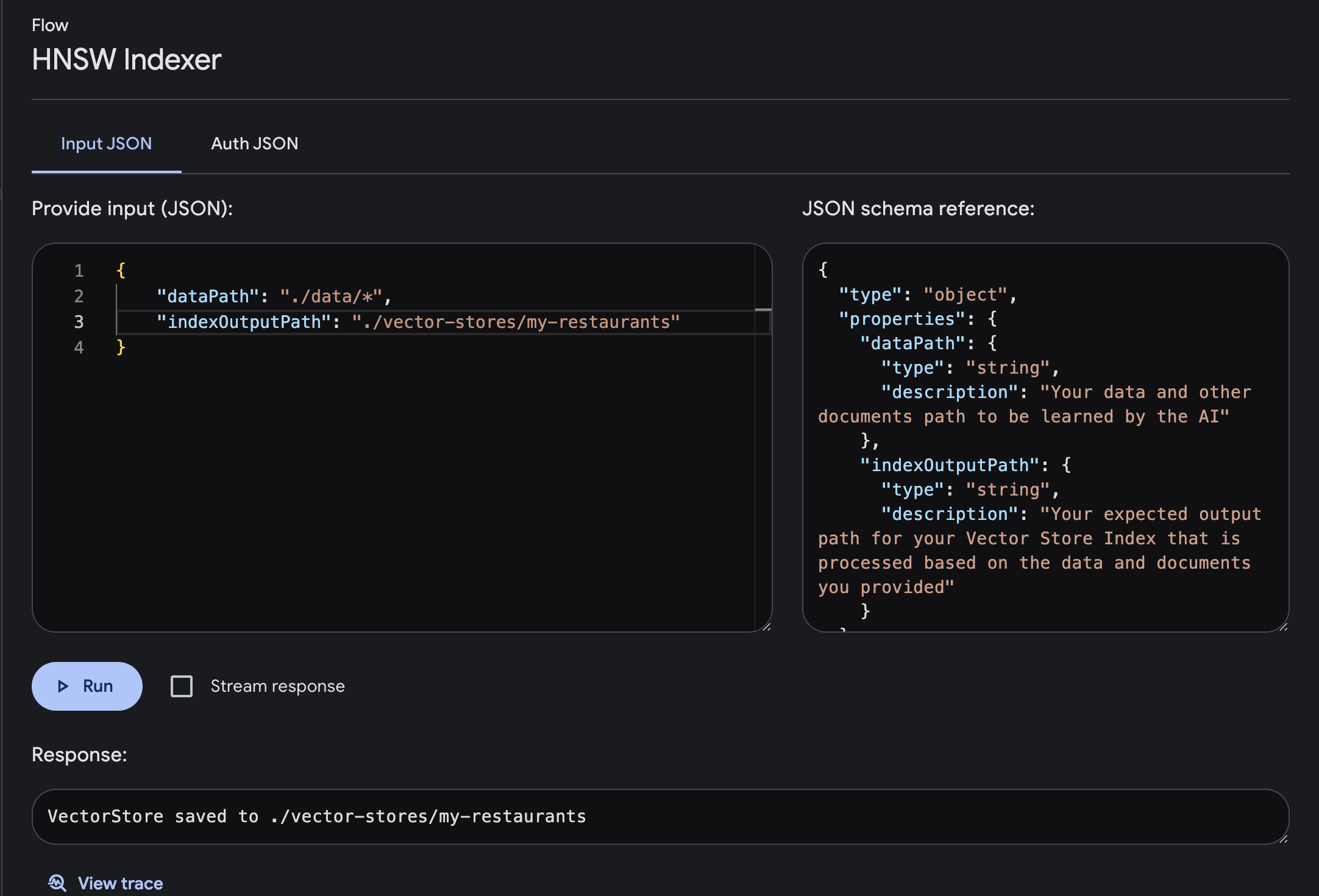
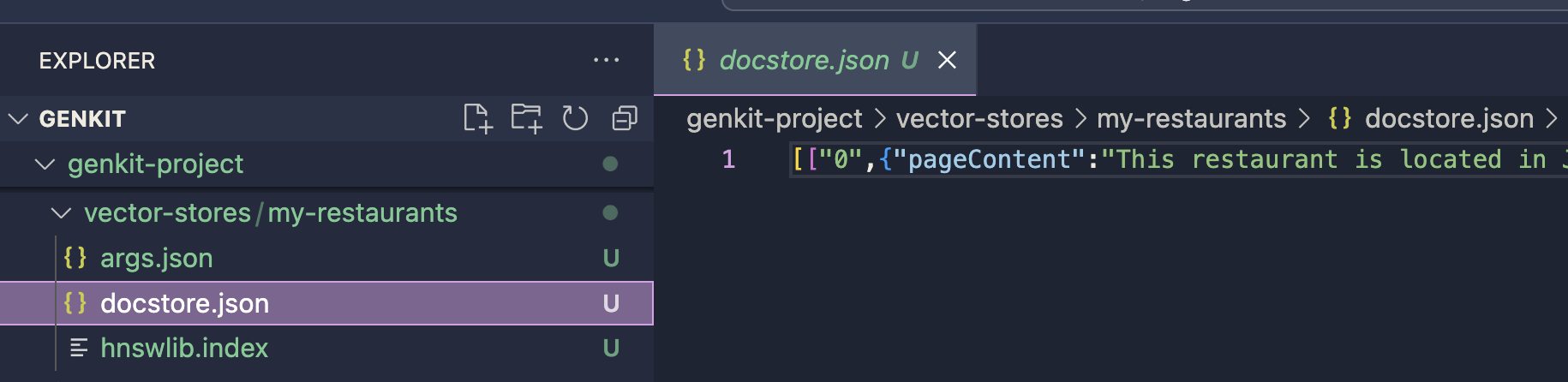 ベクター ストアは、定義された出力パスに保存されます。このインデックスは、HNSW Retriever プラグインによるプロンプト生成プロセスに使用されます。 HNSW Retriever プラグインを使用して実装を続行できます。
ベクター ストアは、定義された出力パスに保存されます。このインデックスは、HNSW Retriever プラグインによるプロンプト生成プロセスに使用されます。 HNSW Retriever プラグインを使用して実装を続行できます。
chunkSize: number一度に処理されるデータの量。それは、大きなタスクをより小さな部分に分割して、管理しやすくするようなものです。チャンク サイズを設定することで、AI が一度に処理する情報の量が決定され、AI の学習プロセスの速度と精度の両方に影響を与える可能性があります。
default value : 12720
separator: stringベクトルインデックスの作成中に、入力データ内のさまざまな情報を区切るために使用される記号または文字。これにより、AI がデータの 1 つの単位がどこで終わり、別の単位が始まるのかを理解できるようになり、データをより効果的に処理して学習できるようになります。
default value : "n"
これは、Genkit プラグイン フローを使用して、提供された HNSW ベクトル データベース内の追加の特定の情報または知識で強化された Gemini LLM モデルを使用してプロンプトを処理する方法です。このプラグインを使用すると、追加の特定のコンテキストを含む LLM 応答を取得できます。
プラグインを Genkit プロジェクトにインポートする
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Gemini LLM モデル プロバイダー用の GoogleAI プラグインをインポートしていることを確認してください。現在、このプラグインは Gemini のみをサポートしていますが、すぐにさらに多くのモデルが提供される予定です。
Genkit UI を開き、登録されているプラグインHNSW Retriever選択します。 必要なパラメータを指定してフローを実行します。
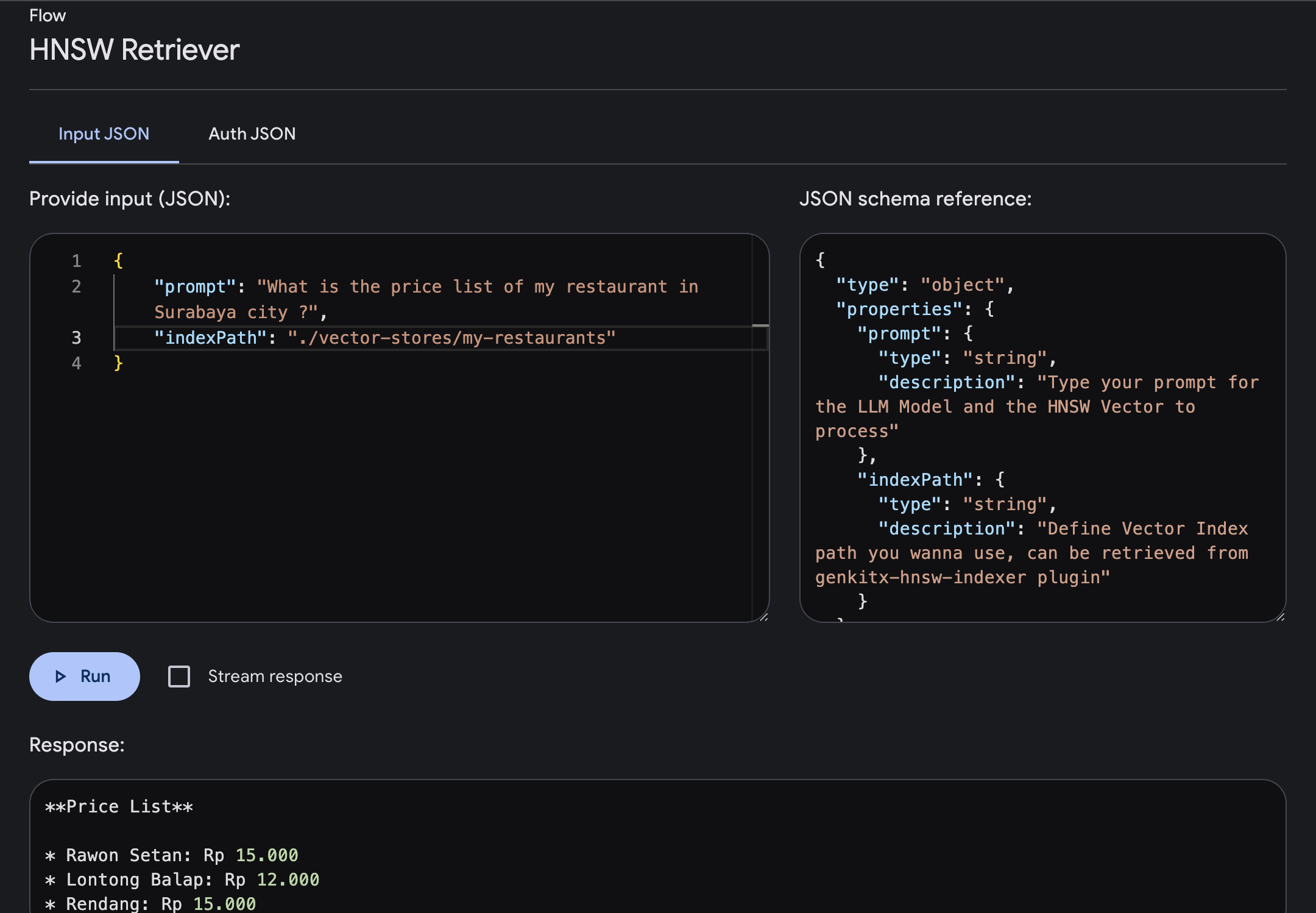
prompt : プロンプトを入力すると、指定したベクトルに基づいて、より充実したコンテキストを含む回答が得られます。indexPath : ナレッジ参照として使用するフォルダーのベクター インデックス パスを定義します。このファイル パスは HNSW Indexer プラグインから取得します。今回は、Vector Index内で提供されているスラバヤ市内のレストランの価格表情報を聞いてみます。
プロンプトを入力して実行すると、フローが完了すると、ベクトル インデックスに基づいた特定の知識が豊富に含まれた応答が得られます。
temperature: number温度は、生成される出力のランダム性を制御します。温度が低いほど、モデルが各ステップで最も可能性の高いトークンを選択するため、より決定的な出力が得られます。温度が高くなるとランダム性が増し、モデルが確率の低いトークンを探索できるようになり、より創造的ではあるが一貫性の低いテキストが生成される可能性があります。
default value : 0.1
maxOutputTokens: numberこのパラメーターは、モデルが 1 つの推論ステップで生成する必要があるトークン (ワードまたはサブワード) の最大数を指定します。生成されるテキストの長さを制御するのに役立ちます。
default value : 500
topK: number Top-K サンプリングでは、モデルの選択が各ステップで最も可能性の高い上位 K 個のトークンに制限されます。これにより、モデルが過度にまれなトークンや可能性の低いトークンを考慮するのを防ぎ、生成されるテキストの一貫性が向上します。
default value : 1
topP: number Top-P サンプリングは、ニュークリアス サンプリングとも呼ばれ、トークンの累積確率分布を考慮し、累積確率が事前に定義されたしきい値 (多くの場合 P と表されます) を超えるトークンの最小セットを選択します。これにより、トークンの可能性に応じて、各ステップで考慮されるトークンの数を動的に選択できます。
default value : 0
stopSequences: string[]これらは、生成時にモデルにテキストの生成を停止するよう信号を送るトークンのシーケンスです。これは、文や段落の終わりに達した後にモデルの生成を停止するなど、生成される出力の長さや内容を制御するのに役立ちます。
default value : []
ライセンス : Apache 2.0


