Interactive RAG
1.0.0
エージェントは、意思決定とタスクのパフォーマンスに言語モデルを活用する方法に革命をもたらしています。エージェントは、言語モデルを使用して意思決定を行い、タスクを実行するシステムです。これらは、複雑なシナリオを処理し、従来のアプローチと比較してより高い柔軟性を提供するように設計されています。エージェントは、言語モデルを利用して情報を処理し、関連するデータを取得し、取り込み (チャンク/埋め込み)、応答を生成する推論エンジンと考えることができます。
将来的には、言語モデルの進歩に伴い、エージェントはテキストの処理、タスクの自動化、および人間とコンピューターの対話の改善において重要な役割を果たすようになるでしょう。
この例では、動的検索拡張生成 (RAG) でのエージェントの活用に特に焦点を当てます。 ActionWeaver と MongoDB Atlas を使用すると、会話型の対話を通じてリアルタイムで RAG 戦略を変更できるようになります。より多くのチャンクを選択するか、チャンク サイズを増やすか、他のパラメータを調整するかにかかわらず、RAG アプローチを微調整して、望ましい応答品質と精度を達成できます。自然言語を使用してベクトル データベースにソースを追加/削除することもできます。
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
テキストをチャンク化するのは素晴らしいことですが、どうやって保存するのでしょうか?
要約するとスペースが節約され、処理が高速化されますが、詳細が失われる可能性があります。
生データの保存は正確ですが、容量が大きく、速度が遅く、「ノイズ」が多くなります。
要約する利点:
要約することの短所:
あなたにとって何が正しいでしょうか?それはあなたのニーズ次第です!考慮する:
デモ1
新しい Python 環境を作成する
python3 -m venv env新しい Python 環境をアクティブ化する
source env/bin/activate要件をインストールする
pip3 install -r requirements.txtparams.py にパラメータを設定します。
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
次の定義を使用して検索インデックスを作成します
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}環境を設定する
export OPENAI_API_KEY=RAG アプリケーションを実行するには
env/bin/streamlit run rag/app.pyアプリケーションによって生成されたログ情報は app.log に追加されます。
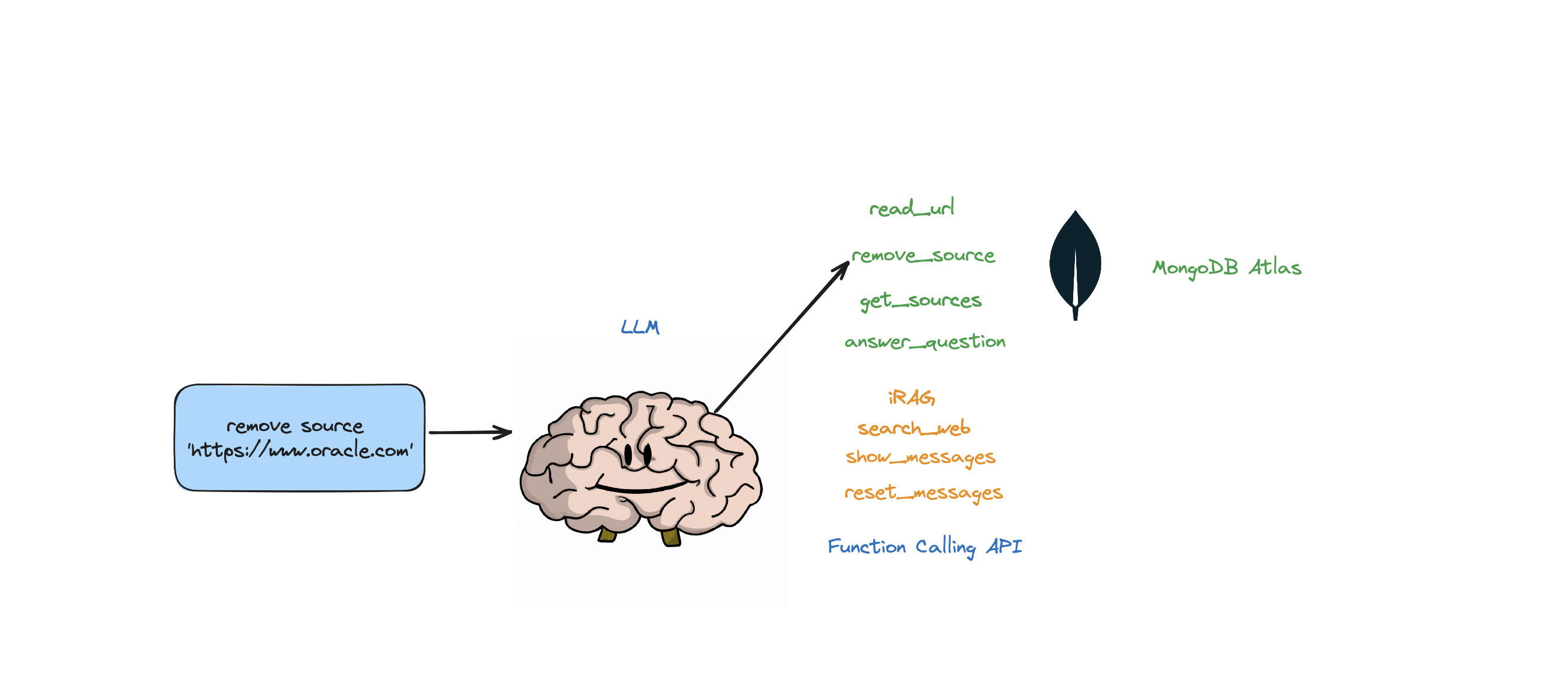
このボットは、質問に答える、Web を検索する、URL を読み取る、ソースを削除する、すべてのソースをリストする、メッセージをリセットするなどのアクションをサポートします。また、エージェントの RAG 戦略を動的に制御できる iRAG と呼ばれるアクションもサポートしています。
例: 「RAG 構成を 3 つのソースとチャンク サイズ 1250 に設定」 => 新しい RAG 構成:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}。
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
ボットが、Atlas Vector ストアに保存されているデータと RAG 戦略 (ソースの数、チャンク サイズ、min_rel_score など) から質問に対する回答を提供できない場合、Web 検索を開始して関連情報を見つけます。その後、それらの結果を読み取って学習するようにボットに指示できます。
RAG はクールですが、適切な「RAG 戦略」を考え出すのは難しいです。チャンク サイズと一意のソースの数は、LLM によって生成される応答に直接影響します。
効果的な RAG 戦略を開発するには、Web ソースの取り込みプロセス、チャンク化、埋め込み、チャンク サイズ、および使用されるソースの量が重要な役割を果たします。チャンク化は入力テキストを分解して理解を深め、埋め込みは意味を捉え、ソースの数は応答の多様性に影響を与えます。チャンク サイズとソースの数の間の適切なバランスを見つけることは、正確で適切な応答を行うために不可欠です。最適な設定を決定するには、実験と微調整が必要です。
「取得」に入る前に、まず「取り込みプロセス」について話しましょう。
コンテンツをベクター データベースに「取り込む」ための別のプロセスが必要なのはなぜでしょうか?エージェントの魔法を使用すると、新しいコンテンツをベクター データベースに簡単に追加できます。
これらの埋め込みを保存できるデータベースには多くの種類があり、それぞれに独自の特別な用途があります。ただし、GenAI アプリケーションが関係するタスクの場合は、MongoDB をお勧めします。
MongoDB は、持ったり食べたりできるケーキのようなものだと考えてください。これにより、クエリを作成するための言語である Mongo Query Language の機能が得られます。また、MongoDB の優れた機能もすべて含まれています。さらに、これらの構成要素 (ベクトル埋め込み) を 1 か所に保存し、それらに対して数学演算を行うことができます。これにより、MongoDB Atlas はベクター埋め込みのあらゆるニーズにワンストップで対応できるようになります。
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
関数呼び出し API の軽量ラッパーである ActionWeaver を使用すると、MongoDB Atlas を使用して関連情報を効率的に取得および取り込むユーザー プロキシ エージェントを構築できます。
プロキシ エージェントは、クライアント要求を他のサーバーまたはリソースに送信し、応答を返す仲介者です。
このエージェントは、対話型でカスタマイズ可能な方法でユーザーにデータを提示し、全体的なユーザー エクスペリエンスを向上させます。
UserProxyAgentは、 chunk_size (例: 1000)、 num_sources (例: 2)、 unique (例: True)、 min_rel_score (例: 0.00) など、カスタマイズできるいくつかの RAG パラメータがあります。
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
ActionWeaver を選択するという決定に影響を与えた主な利点をいくつか示します。
エージェントは基本的に、環境を認識し、意思決定を行い、特定の目標を達成するように設計された単なるコンピューター プログラムまたはシステムです。
エージェントは、ある程度の自律性を示し、ユーザーまたは所有者に代わって環境内で比較的独立した方法でアクションを実行するソフトウェア エンティティと考えてください。目標を達成するための選択肢を検討し、自ら行動を起こすためのイニシアチブが取られます。エージェントの中心的な考え方は、言語モデルを使用して、実行する一連のアクションを選択することです。一連のアクションがコードにハードコーディングされているチェーンとは対照的に、エージェントは言語モデルを推論エンジンとして使用して、どのアクションをどの順序で実行するかを決定します。
アクションは、エージェントが呼び出すことができる機能です。アクションに関しては、設計上の重要な考慮事項が 2 つあります。
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
両方をよく考えなければ、機能するエージェントを構築することはできません。エージェントに正しい一連のアクションへのアクセス権を与えないと、エージェントは与えられた目的を達成できなくなります。アクションをうまく説明しないと、エージェントはアクションを適切に使用する方法がわかりません。
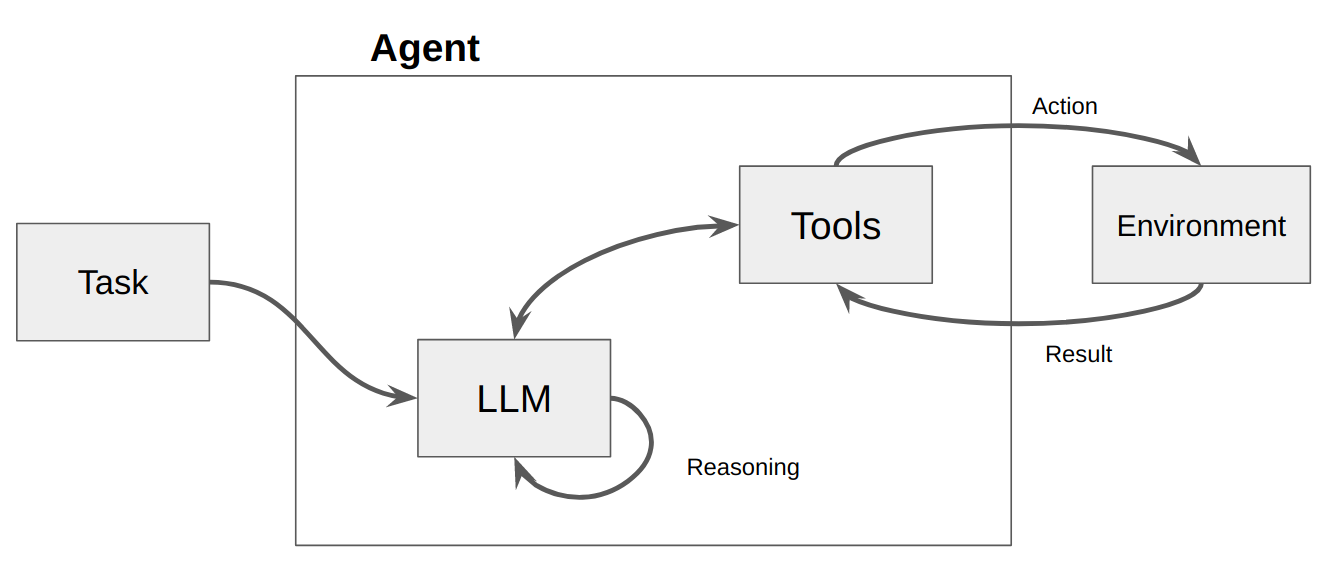
次に LLM が呼び出され、ユーザーへの応答またはアクションが実行されます。応答が必要であると判断された場合、応答はユーザーに渡され、そのサイクルは終了します。アクションが必要であると判断された場合、そのアクションが実行され、観察 (アクションの結果) が行われます。そのアクションと対応する観察がプロンプトに追加され (これを「エージェント スクラッチパッド」と呼びます)、ループがリセットされます。 LLM が再度呼び出されます (更新されたエージェント スクラッチパッドを使用)。
ActionWeaver では、アクションにstop=True|Falseを追加してループに影響を与えることができます。 stop=Trueの場合、LLM は関数の出力をすぐに返します。これにより、LLM が複数の関数呼び出しを行うことも制限されます。このデモではstop=Trueのみを使用します。
ActionWeaver はorch_expr(SelectOne[actions])およびorch_expr(RequireNext[actions])を使用したより複雑なループ制御もサポートしていますが、それについてはパート II に残しておきます。
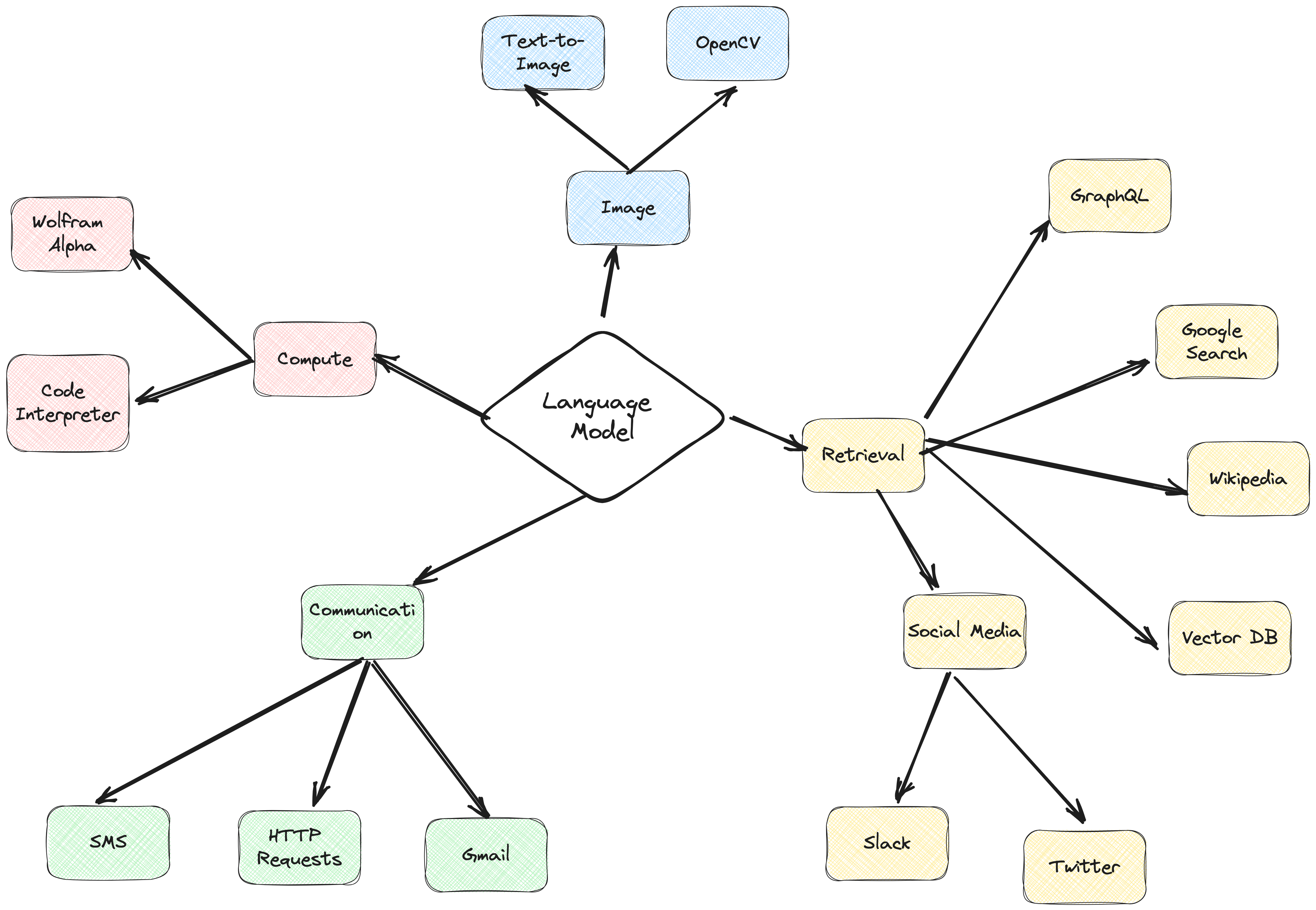
ActionWeaver エージェント フレームワークは、関数呼び出しを中核とする AI アプリケーション フレームワークです。従来のコンピューティング システムと言語モデル モデルの強力な推論機能をシームレスに統合できるように設計されています。 ActionWeaver は LLM 関数呼び出しの概念に基づいて構築されていますが、Langchain や Haystack などの一般的なフレームワークはパイプラインの概念に基づいて構築されています。

詳細については、https://thinhdanggroup.github.io/function-calling-openai/ をご覧ください。
開発者は、シンプルなデコレータを備えたツールとして任意の Python 関数をアタッチできます。次の例では、OpenAI API によって呼び出されるアクション get_sources_list を紹介します。
ActionWeaver は、装飾されたメソッドのシグネチャと docstring を説明として利用し、OpenAI の関数 API に渡します。
ActionWeaver は、docstring/デコレータ情報を OpenAI API の正しい形式に変換する軽いラッパーを提供します。
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True をアクションに追加すると、LLM は関数の出力をすぐに返しますが、LLM が複数の関数呼び出しを行うことも制限されます。たとえば、ニューヨーク市とサンフランシスコの天気について尋ねられた場合、モデルは都市ごとに 2 つの別個の関数を順番に呼び出します。ただし、 stop=Trueを指定すると、最初の関数が最初にクエリを実行する都市に応じて、ニューヨーク市またはサンフランシスコのいずれかの気象情報を返すと、このプロセスは中断されます。
このボットが内部でどのように動作するかをより深く理解するには、bot.py ファイルを参照してください。さらに、ActionWeaver リポジトリで詳細を確認できます。
推論トレースを生成すると、モデルはアクション プランを誘導、追跡、更新し、例外を処理することもできます。この例では、ReAct と思考連鎖 (CoT) を組み合わせて使用します。
思考の連鎖
推理+行動
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
これらの例では、思考連鎖 (CoT) と ReAct プロンプト手法の両方が活用されています。その方法は次のとおりです。
思考連鎖 (CoT) のプロンプト:
プロンプトへの反応:
要約すると、これらの例では CoT と ReAct の両方が重要な役割を果たしています。 CoT を使用すると、モデルは段階的に推論して適切なアクションを選択できます。一方、ReAct は、モデルが環境と対話し、それに応じて計画を更新できるようにすることでこの機能を拡張します。この推論とアクションの組み合わせにより、大規模な言語モデルがより柔軟で多用途になり、より広範囲のタスクや状況を処理できるようになります。
まずはエージェントに質問してみましょう。この場合、 「マンゴーとは何ですか?」 。最初に行われるのは、ベクトル埋め込み類似性を使用して関連情報を「呼び出す」ことです。次に、「思い出した」内容を含む応答を作成するか、Web 検索を実行します。ナレッジベースは現在空であるため、応答を作成する前にいくつかのソースを追加する必要があります。
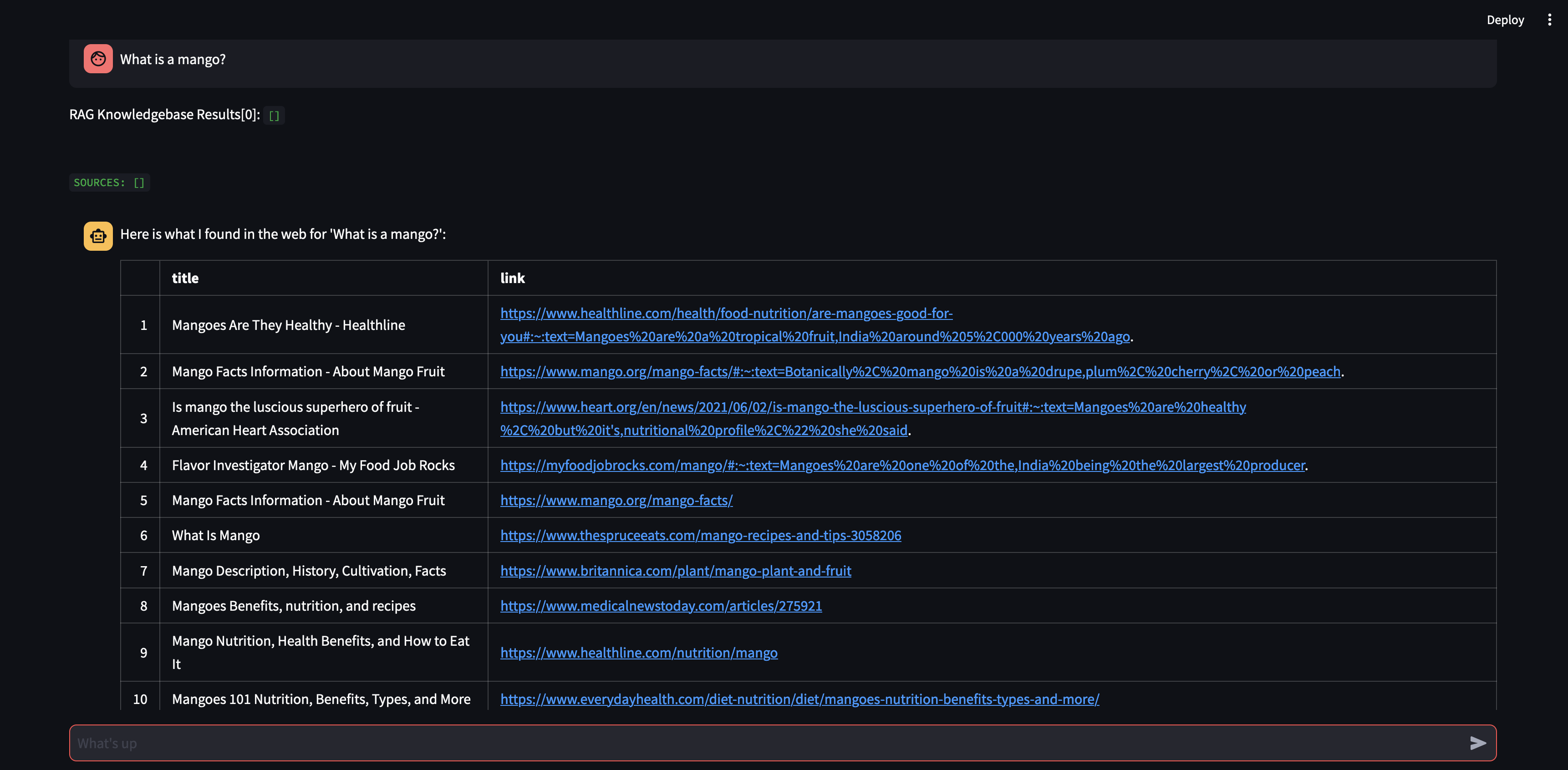
ボットはベクター データベースのコンテンツを使用して回答を提供できないため、関連情報を見つけるために Google 検索を開始しました。これで、どのソースを「学習」すべきかを伝えることができます。この場合、検索結果から最初の 2 つのソースを学習するように指示します。
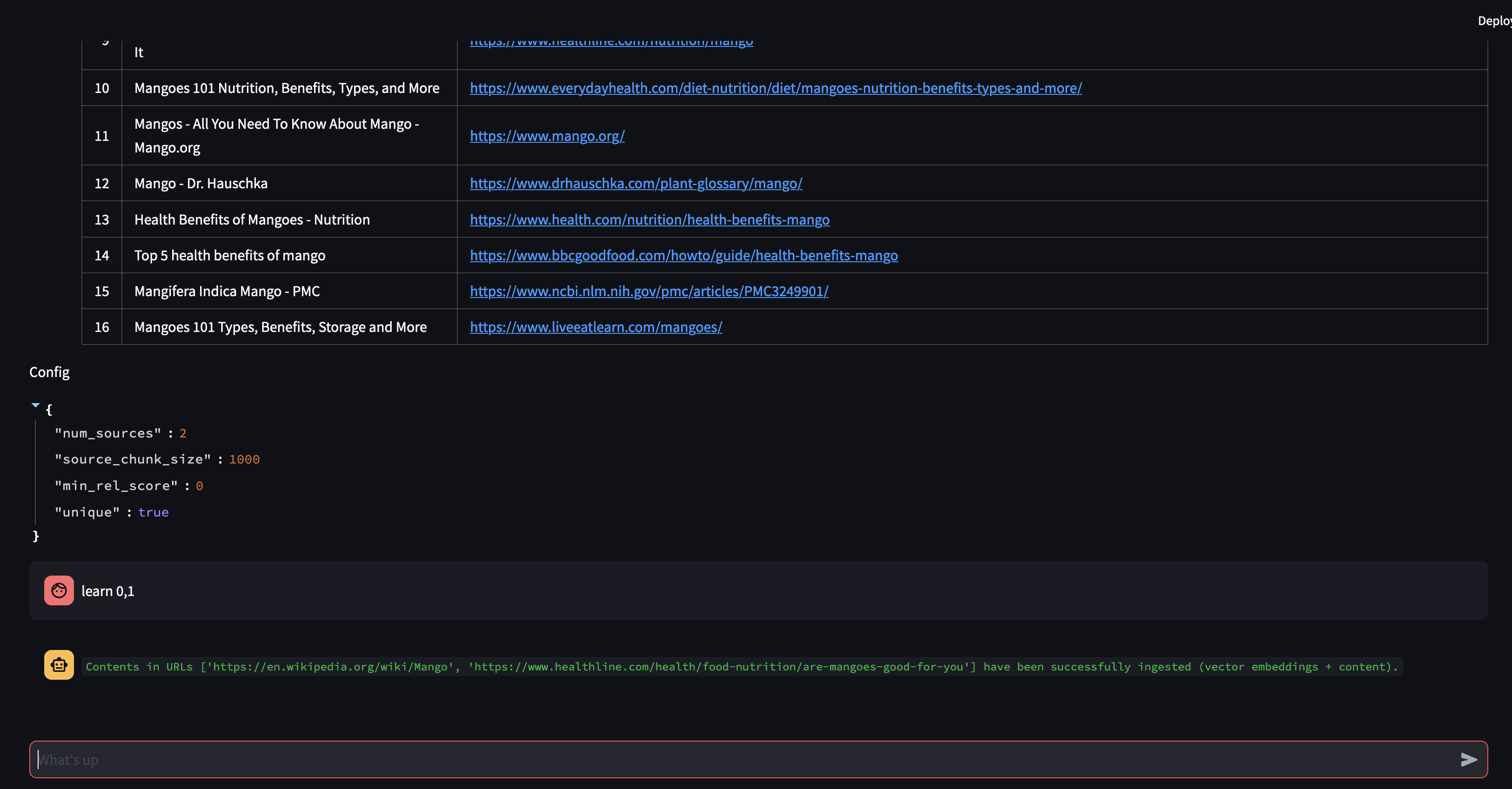
次に、RAG 戦略を変更しましょう。ソースを 1 つだけ使用し、500 文字の小さなチャンク サイズを使用するようにしましょう。
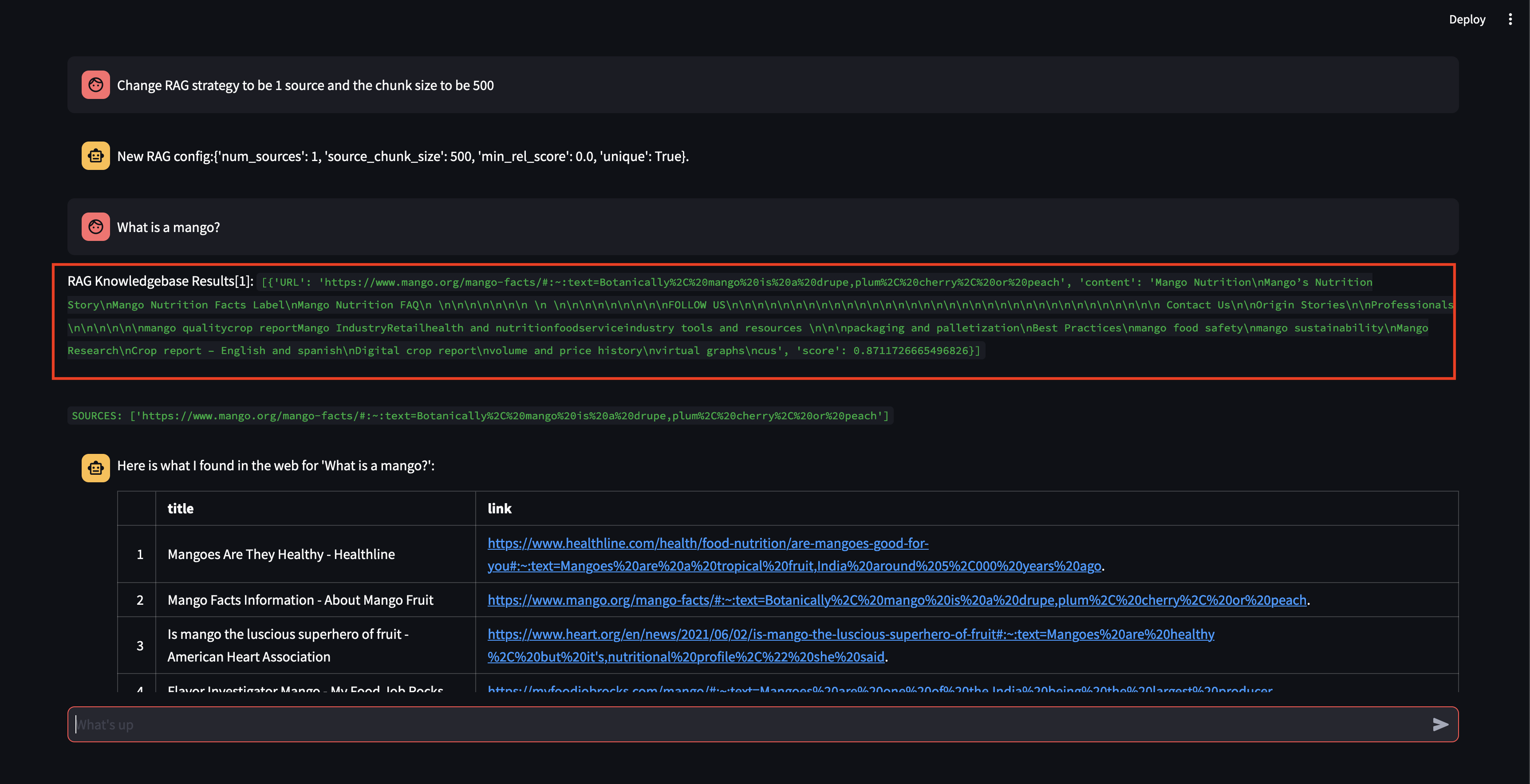
かなり高い関連性スコアを持つチャンクを取得できましたが、チャンクのサイズが小さすぎ、チャンクの内容が応答を作成できるほど関連性がなかったため、応答を生成できなかったことに注目してください。小さなチャンクでは応答を生成できなかったため、ユーザーに代わって Web 検索を実行しました。
チャンク サイズを 500 文字ではなく 3000 文字に増やした場合に何が起こるかを見てみましょう。
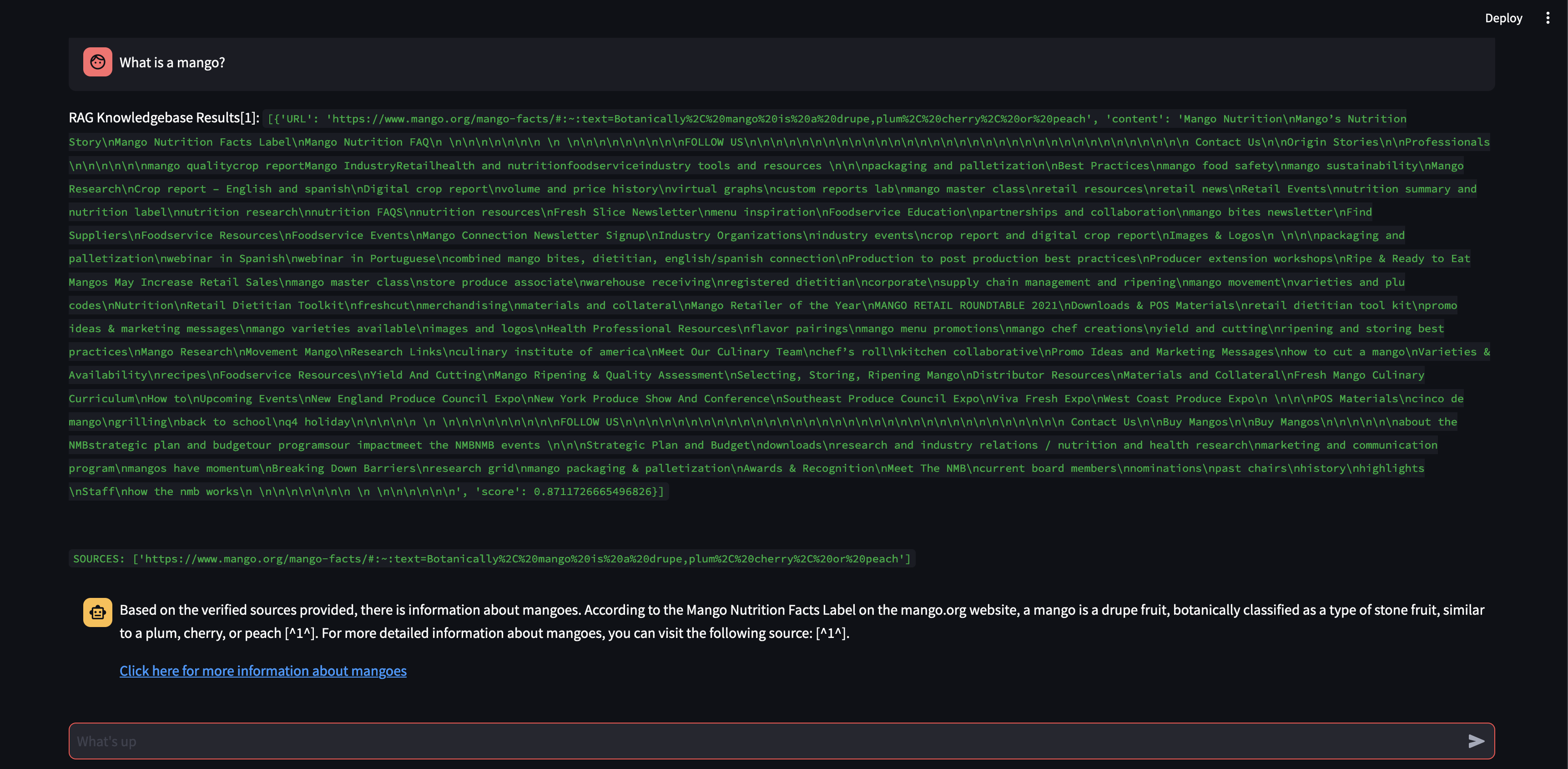
チャンク サイズが大きくなったことで、ベクトル データベースからの知識を使用して応答を正確に定式化できるようになりました。
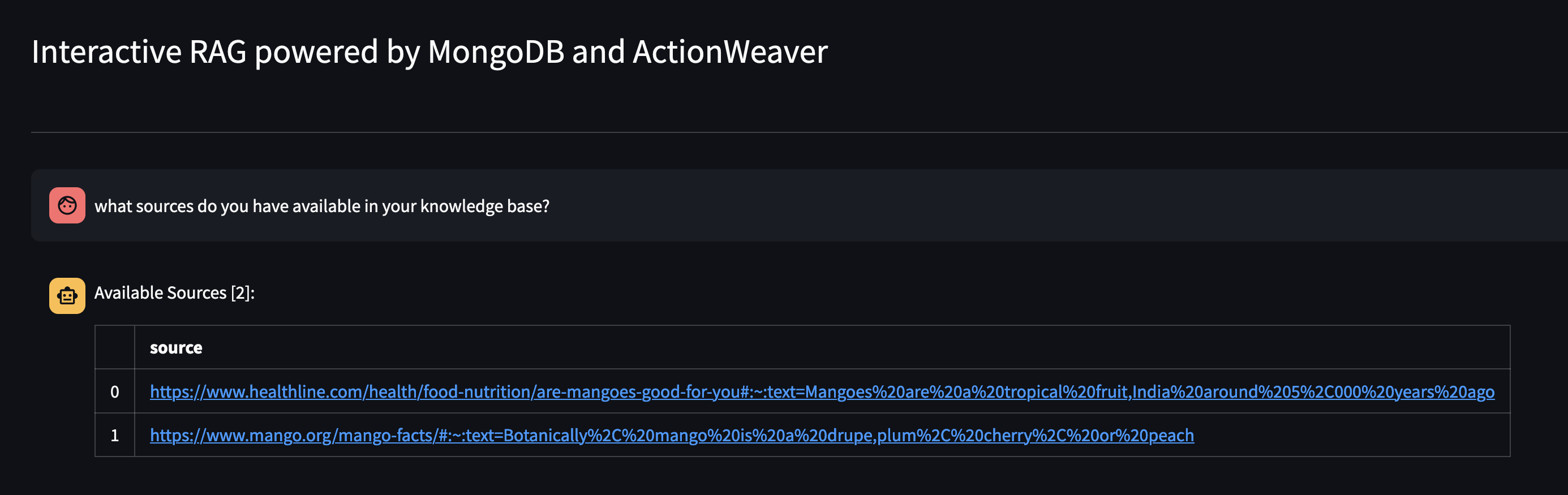
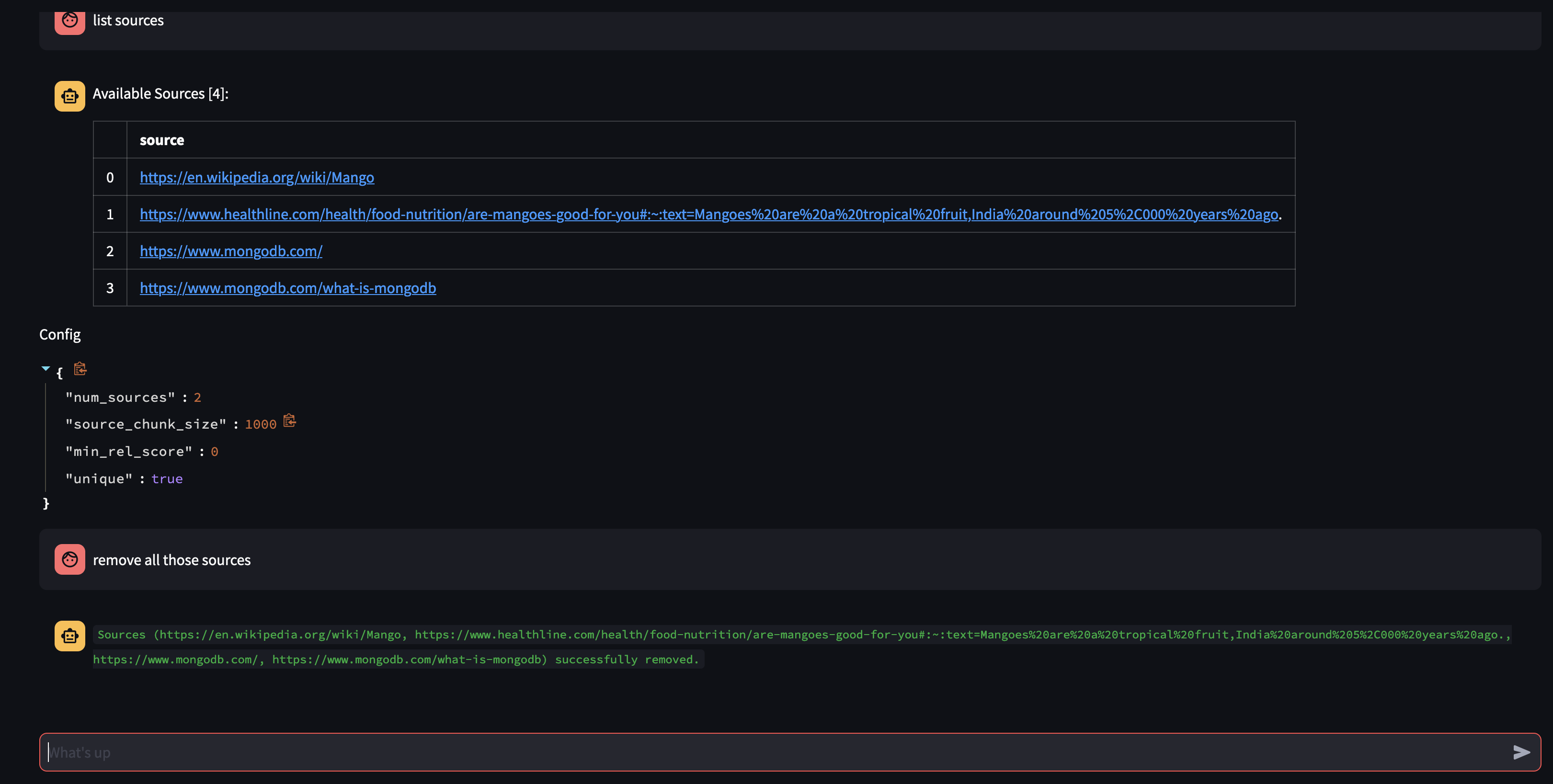
エージェントに質問して、エージェントのナレッジ ベースで利用可能なものを見てみましょう。 「ナレッジ ベースにはどのようなソースがありますか?」
特定のリソースを削除したい場合は、次のようなことができます。
USER: remove source 'https://www.oracle.com' from the knowledge base
コレクション内のすべてのソースを削除するには、次のようなことができます。
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
このデモでは、AI エージェントの内部動作を垣間見ることができ、インタラクティブな方法でユーザーのクエリを学習して応答する能力を示しました。私たちは、社内の知識ベースとリアルタイムの Web 検索をシームレスに組み合わせて、包括的で正確な情報を提供する様子を目撃してきました。このテクノロジーの可能性は膨大で、単純な質問応答をはるかに超えています。これらはいずれも、関数呼び出し APIの魔法なしでは不可能です。
これは https://github.com/TengHu/Interactive-RAG からインスピレーションを得たものです
オープンソース コミュニティからの貢献を歓迎します。
Apache ライセンス 2.0


