content dicovery platform gcp
1.0.0
このリポジトリには、VertexAI 基礎モデルを活用したシンプルなコンテンツ検出プラットフォームを構築するために必要なコードと自動化が含まれています。このプラットフォームは、ドキュメント コンテンツ (最初は Google ドキュメント) をキャプチャできる必要があり、そのコンテンツを使用して、VertexAI Matching Engine を利用したベクトル データベースに保存される埋め込みベクトルを生成します。後で、この埋め込みを利用して、外部の消費者向けの一般的な質問の文脈を説明したり、このコンテキストは、回答を取得するために VertexAI 基礎モデルへの回答を要求します。
プラットフォームは、アクセス サービス層、コンテンツ キャプチャ パイプライン、コンテンツ ストレージ、LLM の 4 つの主要コンポーネントに分離できます。サービス層により、外部消費者はドキュメント取り込みリクエストを送信し、その後、以前に取り込まれたドキュメントに含まれるコンテンツについての問い合わせを送信できるようになります。コンテンツ キャプチャ パイプラインは、NRT でドキュメントのコンテンツをキャプチャし、埋め込みを抽出し、それらの埋め込みを実際のコンテンツにマッピングする役割を果たします。これは、後で外部ユーザーの質問を LLM にコンテキスト化するために使用できます。コンテンツ ストレージは、LLM 微調整、オンライン エンベディング マッチング、チャンク コンテンツの 3 つの異なる目的に分かれており、それぞれが専用のストレージ システムによって処理され、取り込みとクエリを実装するためにプラットフォームのコンポーネントが必要とする情報を保存するという一般的な目的を持っています。ケースを使用します。最後になりましたが、プラットフォームは 2 つの特殊な LLM を利用して、取り込まれたドキュメント コンテンツからリアルタイムの埋め込みを作成し、もう 1 つはプラットフォームのユーザーが要求した回答の生成を担当します。
前に説明したすべてのコンポーネントは、公開されている GCP サービスを使用して実装されます。それらを列挙すると、Cloud Build、Cloud Run、Cloud Dataflow、Cloud Pubsub、Cloud Storage、Cloud Bigtable、Vertex AI Matching Engine、Vertex AI 基本モデル (埋め込みとテキストバイソン)、およびコンテンツ情報としての Google ドキュメントと Google ドライブが含まれます。ソース。
次の図は、アーキテクチャとテクノロジーのさまざまなコンポーネントが相互にどのように相互作用するかを示しています。
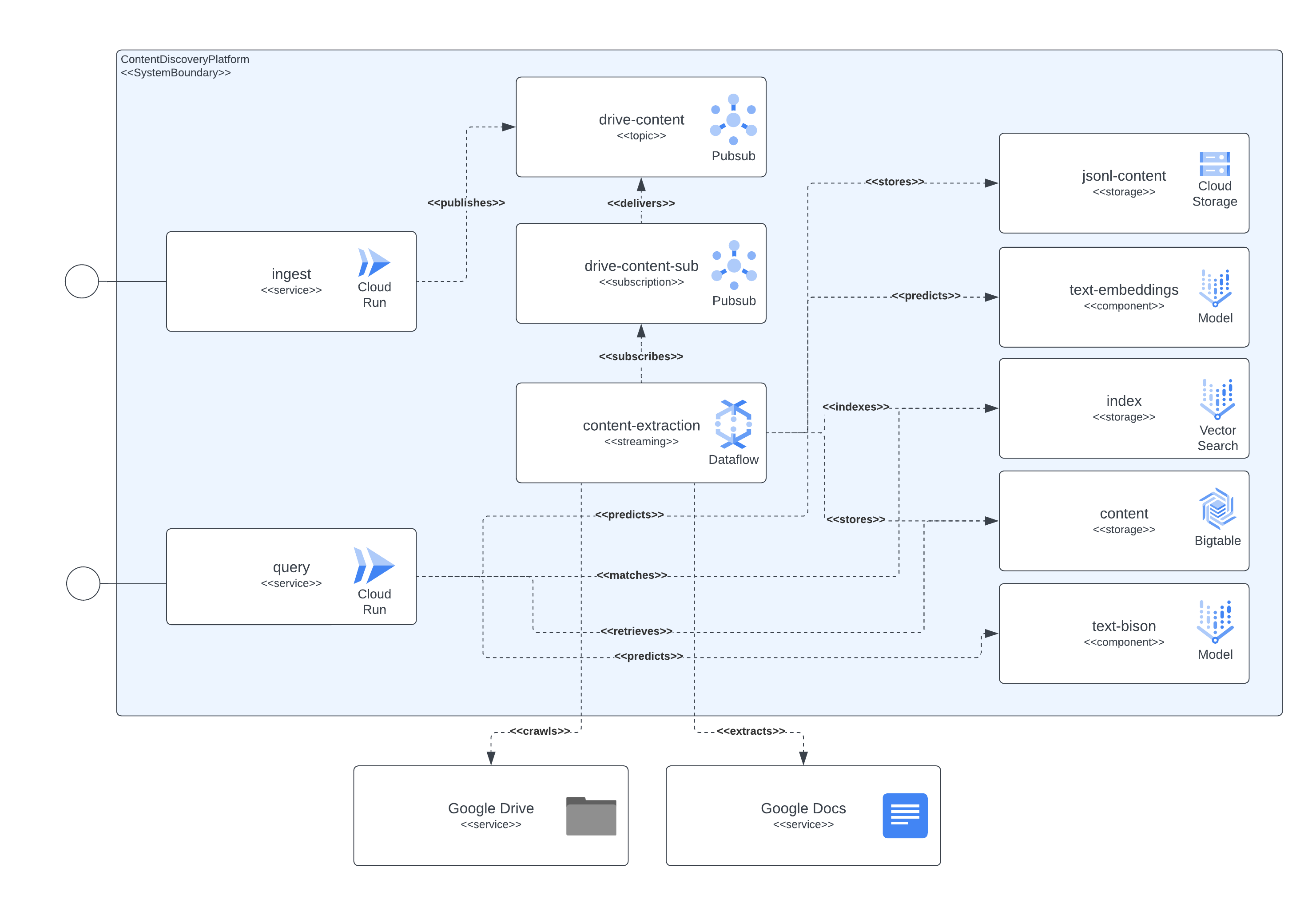
このプラットフォームは、すべてのコンポーネントのセットアップに Terraform を使用します。現在ネイティブ サポートがないものについては、null_resource ラッパーを作成しました。これは良い回避策ですが、非常に荒削りな傾向があるため、潜在的なエラーに注意してください。
現在 (2023 年 6 月) の時点で、完全な展開が完了するまでに最大 90 分かかる場合があります。最大の原因は、作成してすぐに利用できるようになるまでにその時間の大部分を費やすマッチング エンジン関連のコンポーネントです。時間の経過とともに、この延長された実行時間は改善されるだけです。
セットアップは、リポジトリに含まれるスクリプトから実行できる必要があります。
このプラットフォームを展開するには、次のようないくつかの要件を満たす必要があります。
すべてのコンポーネントを GCP にデプロイするには、インフラストラクチャを構築して作成し、その後サービスとパイプラインをデプロイする必要があります。
これを達成するために、基本的に完全な展開目標を達成するために他の含まれるスクリプトを調整するスクリプトstart.shを組み込みました。
また、インフラストラクチャの破壊と収集されたデータのクリーンアップを担当するcleanup.shスクリプトも組み込まれています。
通常の場合、Google Workspace ドキュメントは、コンテンツ取り込みパイプラインが実行されるプロジェクトをホストする同じ組織上に作成されるため、これらのドキュメントに権限を付与するには、パイプラインを実行するサービス アカウントをドキュメントまたはドキュメントのフォルダに追加します。 、十分なはずです。
プロジェクトの組織外に存在するドキュメントまたはフォルダーにアクセスする必要がある場合は、追加の手順を完了する必要があります。インフラストラクチャが設定されると、デプロイ プロセスによって、コンテンツ抽出パイプラインを実行するサービス アカウントに、ドメイン全体の委任を通じて Google Workspace ドキュメント アクセス権限を偽装する権限を付与するための手順が出力されます。手順を完了するための情報は、https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account で確認できます。
このソリューションは、GCP CloudRun と API Gateway を通じていくつかのリソースを公開し、コンテンツの取り込みやコンテンツ検出のクエリのやり取りに使用できます。すべての例では、シンボリックな<service-address>文字列を使用しています。これは、サービスのデプロイメントが完了した後、CloudRun (Terraform 出力のbackend_service_url ) または API Gateway (Terraform 出力のsevice_url ) によって提供される URL に置き換える必要があります。
CORS インタラクションが必要な場合、プリフライト プロトコルを完了しようとするときに API ゲートウェイ エンドポイントを使用できます。 CloudRun は現在、認証されていないOPTIONSコマンドをサポートしていませんが、API Gateway を通じて公開されるこれらのパスはサポートしています。
このサービスは、Google ドライブでホストされているドキュメント、またはドキュメント識別子とバイナリとしてエンコードされたドキュメントのコンテンツを含む自己完結型のマルチパート リクエストからデータを取り込むことができます。
Google ドライブの取り込みは、次の例と同様の HTTP リクエストを送信することで行われます。
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} 'このリクエストは、提供されたurlからドキュメントを取得するプラットフォームを示します。取り込みを実行するサービス アカウントがドキュメントへのアクセス許可を持っている場合、サービス アカウントはドキュメントからコンテンツを抽出し、インデックス作成、後の検出と取得のために情報を保存します。
リクエストには、Google ドキュメントまたは Google ドライブ フォルダーの URL を含めることができます。最後の場合、取り込みによってフォルダーがクロールされ、ドキュメントが処理されます。また、 string値のJSONArray期待するプロパティurlsを使用することもできます。それぞれが有効な Google ドキュメント URL です。
取り込みクライアントがローカルにアクセスできる記事、ドキュメント、またはページのコンテンツを含めたい場合は、ドキュメントを取り込むにはマルチパート エンドポイントを使用するだけで十分です。例として次のcurlコマンドを参照してください。サービスは、 documentIdフォームフィールドがコンテンツを識別し、一意にインデックスを付けるように設定されていることを想定しています。
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartこのサービスは、サービスに自然テキスト クエリを送信することで、プラットフォームのユーザーにクエリ機能を公開します。また、プラットフォームへの取り込み後にコンテンツ インデックスがすでに存在すると、サービスは LLM モデルによって要約された情報を返します。
サービスとの対話は、次の例に示すように、取り込み部分の場合と同様の REST 交換を通じて実行できます。
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}ここには特別なケースがあり、特定のトピックに関する情報がまだ保存されていない場合、そのトピックが GCP ランドスケープに該当する場合、モデル リクエストに対してそのことを示すプロンプトを設定しているため、モデルはエキスパートとして機能します。
サービスとのよりコンテキスト認識型の交換を行いたい場合は、サービスが会話交換キーとして使用するセッション識別子 (JSON リクエストのsessionIdプロパティ) を提供する必要があります。この会話キーは、(以前の交換を要約することによって) モデルに適切なコンテキストを設定し、(少なくとも) 最後の 5 つの交換を追跡するために使用されます。また、交換履歴は 24 時間保持されることにも注意してください。これは、プラットフォーム内の BigTable ストレージの gc ポリシーの一部として変更できます。
次に、コンテキストを意識した会話の例を示します。
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

