cassandra lucene index
2.1.20.0
Stratio の Cassandra Lucene Index は、Stratio Cassandra から派生した Apache Cassandra のプラグインで、インデックス機能を拡張して、全文検索機能や無料の多変数、地理空間、バイテンポラル検索など、ElasticSearch や Solr などのほぼリアルタイムの検索を提供します。これは、Apache Lucene ベースの Cassandra セカンダリ インデックスの実装を通じて実現され、クラスターの各ノードが独自のデータにインデックスを付けます。 Stratio の Cassandra インデックスは、Stratio の BigData プラットフォームの基盤となるコア モジュールの 1 つです。
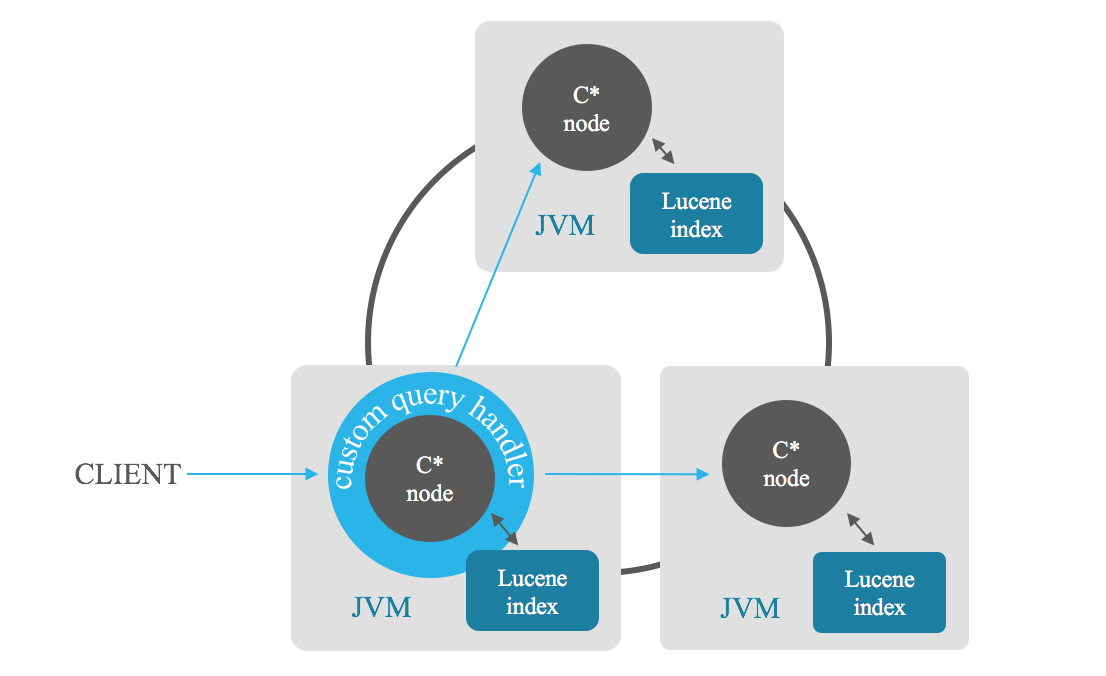
インデックス関連性検索を使用すると、検索を満たすn 個のより関連性の高い結果を取得できます。コーディネーター ノードはクラスター内の各ノードに検索を送信し、各ノードがn 個の最良の結果を返します。その後、コーディネーターがこれらの部分的な結果を組み合わせて、フル スキャンを回避して、そのうちのn個の最良の結果を提供します。フィールドの組み合わせに基づいて並べ替えを行うこともできます。
コレクションだけでなく主キー内のセルも含め、テーブル内の任意のセルにインデックスを付けることができます。幅の広い行もサポートされています。トークン/キー範囲をスキャンし、追加の CQL3 句を適用し、フィルター処理された結果をページングできます。
インデックス フィルター検索は、Apache Hadoop やさらに優れた Apache Spark などの MapReduce フレームワークを使用して Cassandra に保存されたデータを分析するときに強力に役立ちます。ジョブ入力に Lucene フィルターを追加すると、フル スキャンを回避して、処理するデータ量を大幅に削減できます。
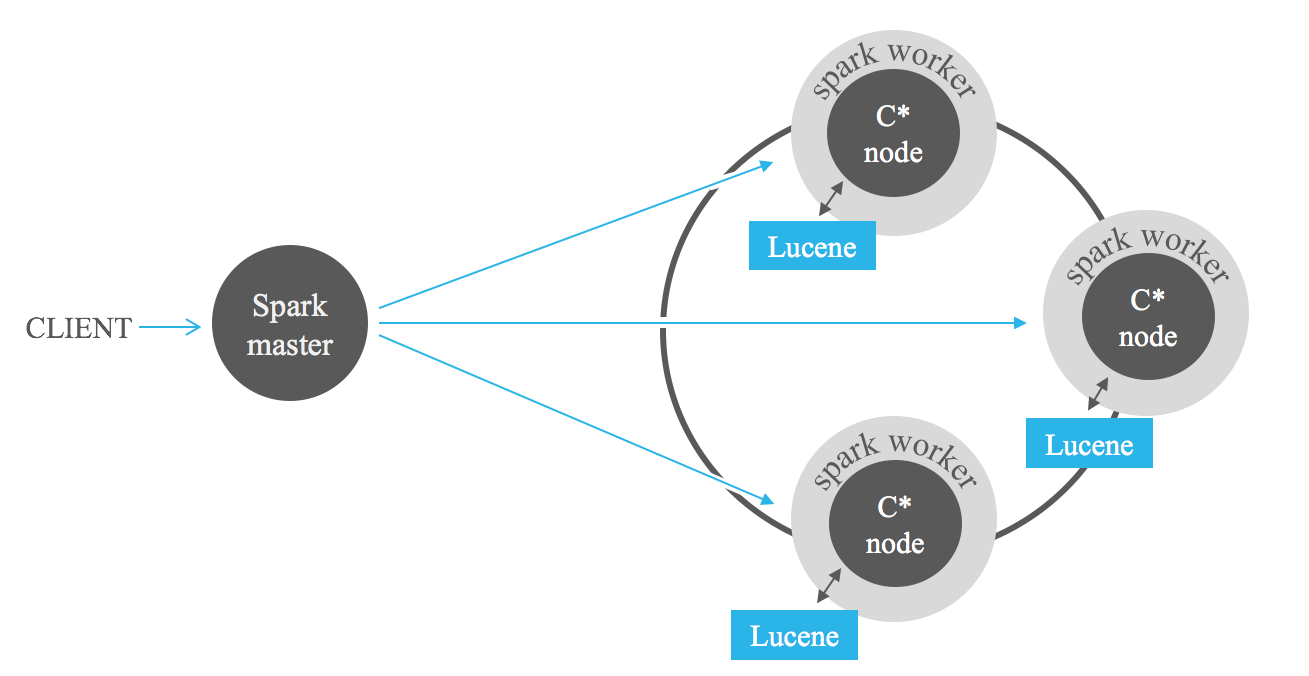
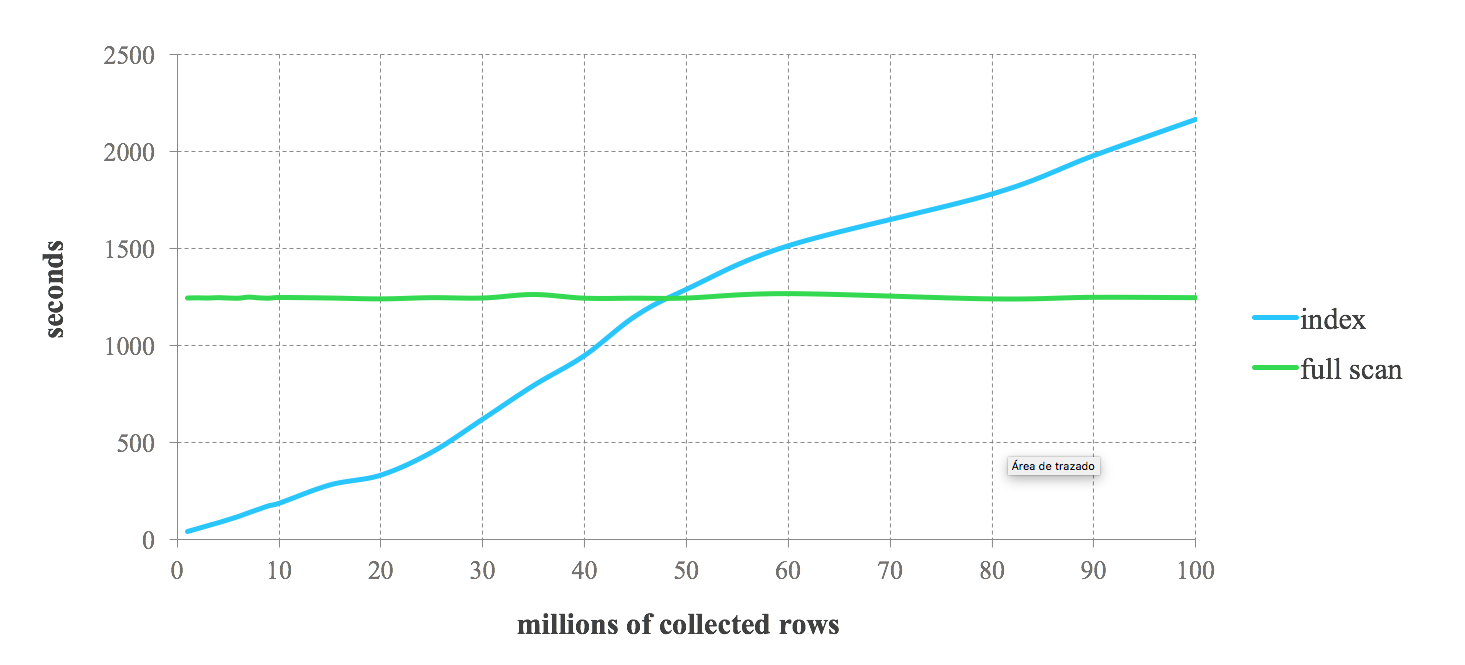
次のベンチマーク結果は、Lucene インデックスと Spark を組み合わせたときに予想されるパフォーマンスについてのアイデアを提供します。保存されたデータの 1% から 100% をリクエストする連続クエリを実行します。強力にフィルターされたデータを要求するクエリのインデックスのパフォーマンスが高いことがわかります。ただし、制限の少ないクエリではパフォーマンスが低下します。クエリによって返されるレコードの数が増加すると、インデックスの速度がフル スキャンよりも遅くなる点に達します。したがって、Spark ジョブでインデックスを使用するかどうかは、クエリの選択性に依存します。両方のアプローチ間のトレードオフは、特定の使用例によって異なります。一般に、保存されたデータの 25% 以下を取得するジョブには、Lucene インデックスと Spark を組み合わせることが推奨されます。
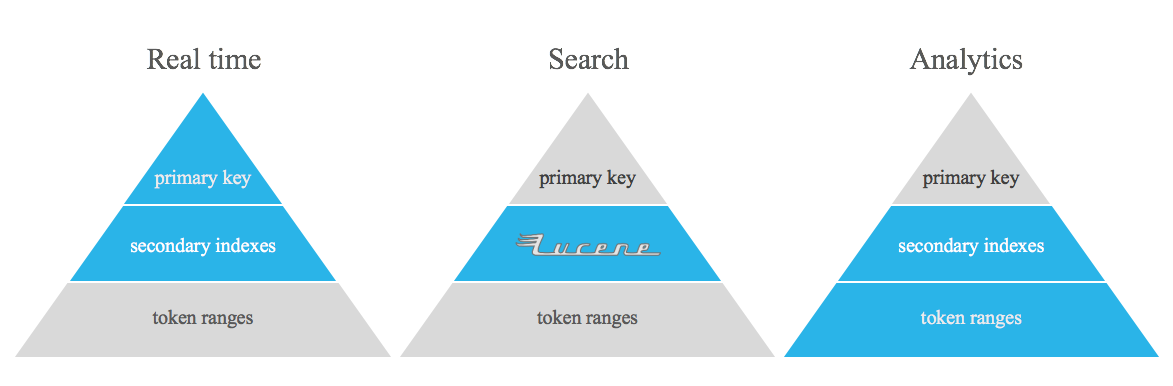
このプロジェクトは、Apache Cassandra の非正規化テーブル、逆インデックス、セカンダリ インデックスを置き換えることを目的としたものではありません。これは、Apache Cassandra のすぐに使用できる機能を使用して対処するのが非常に難しい、ある種のクエリを実行するための単なるツールであり、リアルタイムと分析の間のギャップを埋めます。
詳細については、Stratio の Cassandra Lucene Index ドキュメントを参照してください。
Lucene 検索テクノロジーを Cassandra に統合すると、次のことが可能になります。
Stratio の Cassandra Lucene Index と Lucene 検索テクノロジーとの統合により、次のことが可能になります。
まだサポートされていません:
counter列のインデックス付けStratio の Cassandra Lucene Index は、Apache Cassandra のプラグインとして配布されています。したがって、プラグインを含む JAR を構築し、それを Cassandra のクラスパスに追加するだけです。
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/特定の Cassandra Lucene インデックス バージョンは、特定の Apache Cassandra バージョンを対象としています。したがって、cassandra-lucene-index ABCX は、Apache Cassandra ABC で使用することを目的としています。たとえば、cassandra:3.0.7 の場合は、cassandra-lucene-index:3.0.7.1 です。本番対応リリースはバージョン タグ (例: 3.0.6.3) であり、本番環境ではブランチ X もマスター ブランチも使用しないことに注意してください。
あるいは、Cassandra インストールのパスを指定して、この Maven プロファイルを使用してパッチ適用を行うこともできます。このタスクでは、CASSANDRA_HOME/lib/ ディレクトリ内の以前のプラグインの JAR バージョンも削除します。
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Cassandra のバージョンがインストールされていない場合は、Maven が適切なバージョンの Apache Cassandra をダウンロードしてパッチを適用できるようにする代替プロファイルもあります。
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >これで、Cassandra を実行し、Cassandra クエリ言語を使用していくつかのテストを実行できるようになりました。
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Lucene のインデックス ファイルは、Cassandra のインデックス ファイルと同じディレクトリに保存されます。デフォルトのデータディレクトリは/var/lib/cassandra/dataで、各インデックスはインデックス付き列ファミリーの SSTable の隣に配置されます。
地理形状検索を使用する場合は、JTS jar を含める必要があることに注意してください。
Apache Cassandra の詳細については、そのドキュメントを参照してください。
ツイートを保存するために次のテーブルを作成します。
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);これで、次のステートメントを使用してカスタム Lucene インデックスを作成できるようになります。
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
};これにより、テーブル内のすべての列が指定されたタイプでインデックス付けされ、1 秒に 1 回更新されます。あるいは、一貫性ALLを使用して空の検索を使用して、すべてのインデックス シャードを明示的に更新することもできます。
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUM次に、特定の日付範囲内のツイートを検索するには:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );同じ検索を実行して、関連するインデックス シャードの明示的な更新を強制することもできます。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;ここで、前述の日付範囲内で本文フィールドに「ビッグデータは組織に与える」というフレーズが含まれる、より関連性の高いツイートの上位 100 件を検索するには、次のようにします。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;名前が「a」で始まるユーザーによって書かれたツイートのみを取得するように検索を絞り込むには、次の手順を実行します。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;フィルタリングされた最新の 100 件の結果を取得するには、並べ替えオプションを使用します。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;以前の検索は、地理的位置に近い場所で作成されたツイートに制限できます。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;地理的位置までの距離によって結果を並べ替えることもできます。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;最後に重要なことですが、クラスター ノードのサブセットのみがヒットするように、検索を特定のトークン範囲またはパーティションにルーティングして、貴重なリソースを節約できます。
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;最後の部分は、Hadoop、Spark、およびその他の MapReduce フレームワークのサポートの基礎です。
包括的な Stratio の Cassandra Lucene Index ドキュメントを参照してください。


