aiwhispr
version 0.941
AIWhispr は、セマンティック検索のためのベクトル埋め込みパイプラインを自動化するノー/ローコード ツールです。シンプルな構成により、ファイルの読み取り、テキストの抽出、ベクトル埋め込みの作成、およびそれらのベクトル データベースへの保存のためのパイプラインが駆動されます。
AIウィスパー

AIWhispr には次のベクトル データベース用のコネクタがあります。
1 クドラント
2 ミルバス
3ウィアビエイト
4 タイプセンス
5 モンゴDB
6 Postgres - PGVector
Vector データベースがインストールされ、起動されていることを確認してください。
AIWHISPR_HOME_DIR 環境変数は、aiwhispr ディレクトリへのフルパスである必要があります。
AIWHISPR_LOG_LEVEL 環境変数は DEBUG / INFO / WARNING / ERROR に設定できます
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
シェルログインスクリプトに環境変数を忘れずに追加してください。
以下のコマンドを実行します
$AIWHISPR_HOME/shell/install_python_packages.sh
uwsgi のインストールが失敗する場合は、 gcc、 python-dev 、 python3-dev がインストールされていることを確認してください。
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr には、使い始めるのに役立つストリームリット アプリが付属しています。
ストリームリットアプリを実行する
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
これにより、デフォルトのポート 8501 で streamlit アプリが起動し、Web ブラウザでセッションが開始されます。
セマンティック検索用にコンテンツのインデックスを作成するパイプラインを構成するには、3 つの手順があります。
1. 保存場所からファイルを読み取るように設定する
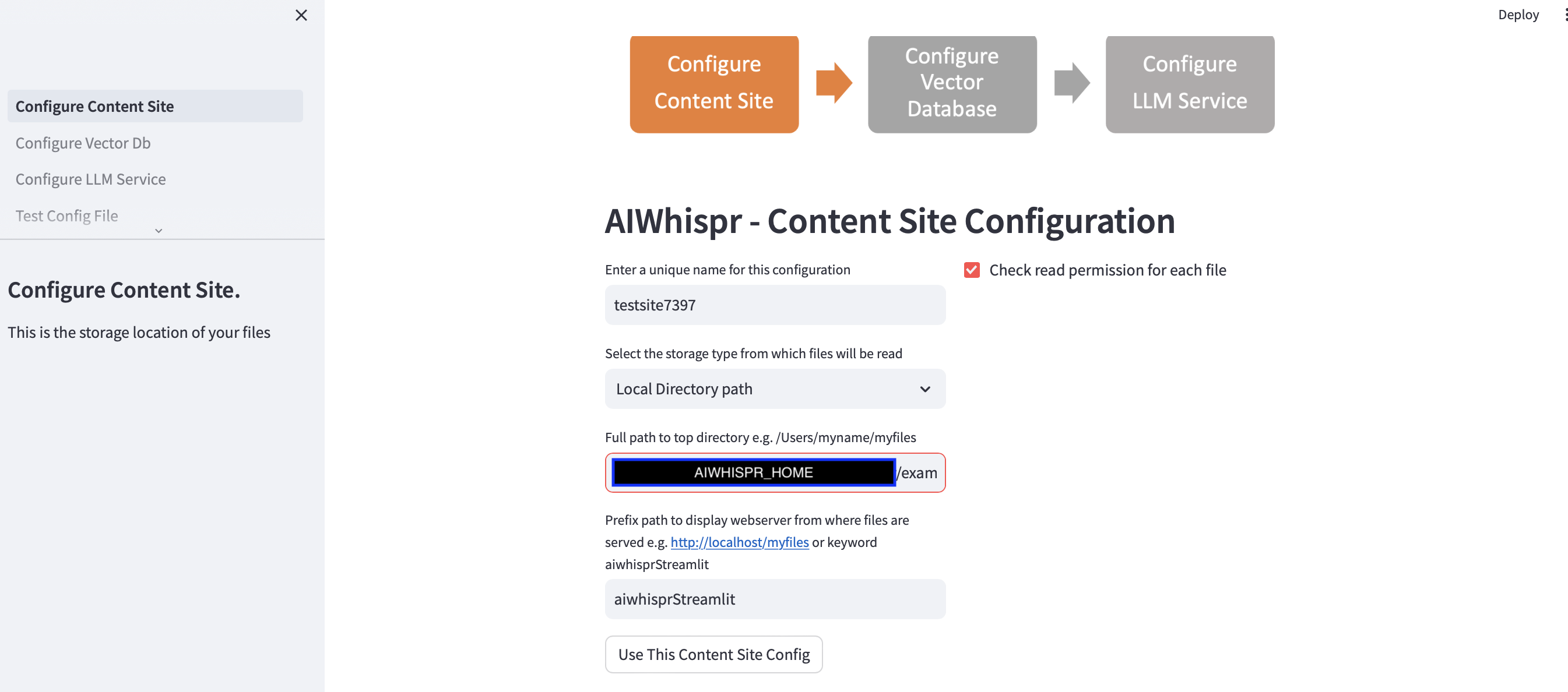
[このコンテンツ サイト構成を使用する] ボタンをクリックすると、デフォルト構成を続行できます。
次のステップに進み、ベクトル データベース接続を構成します。
デフォルトの例では、セマンティック検索のために BBC のニュース記事にインデックスを付けます。
streamlit アプリは、新しい構成を開始していると想定し、ランダムな構成名を割り当てます。これを上書きして、より意味のある名前を付けることができます。構成名は一意である必要があります。空白や特殊文字を含めることはできません。
デフォルト設定では、ローカル ディレクトリ パス $AIWHISPR_HOME/examples/http/bbc からコンテンツが読み取られます。
これには、セマンティック検索用にインデックス付けされた BBC の 2000 以上のニュース記事が含まれています。
AWS S3、Azure Blob、Google Cloud Storage に保存されているコンテンツを読み取ることを選択できます。
プレフィックス パス設定は、検索結果の href Web リンクを作成するために使用されます。デフォルトのキーワード「aiwhisprStreamlit」を使用して続行できます。
[このコンテンツ サイト構成を使用する] ボタンをクリックし、左側のサイドバーにある [Vector DB の構成] をクリックして次のステップに進み、ベクター データベース接続を構成します。
2. ベクターDBの設定
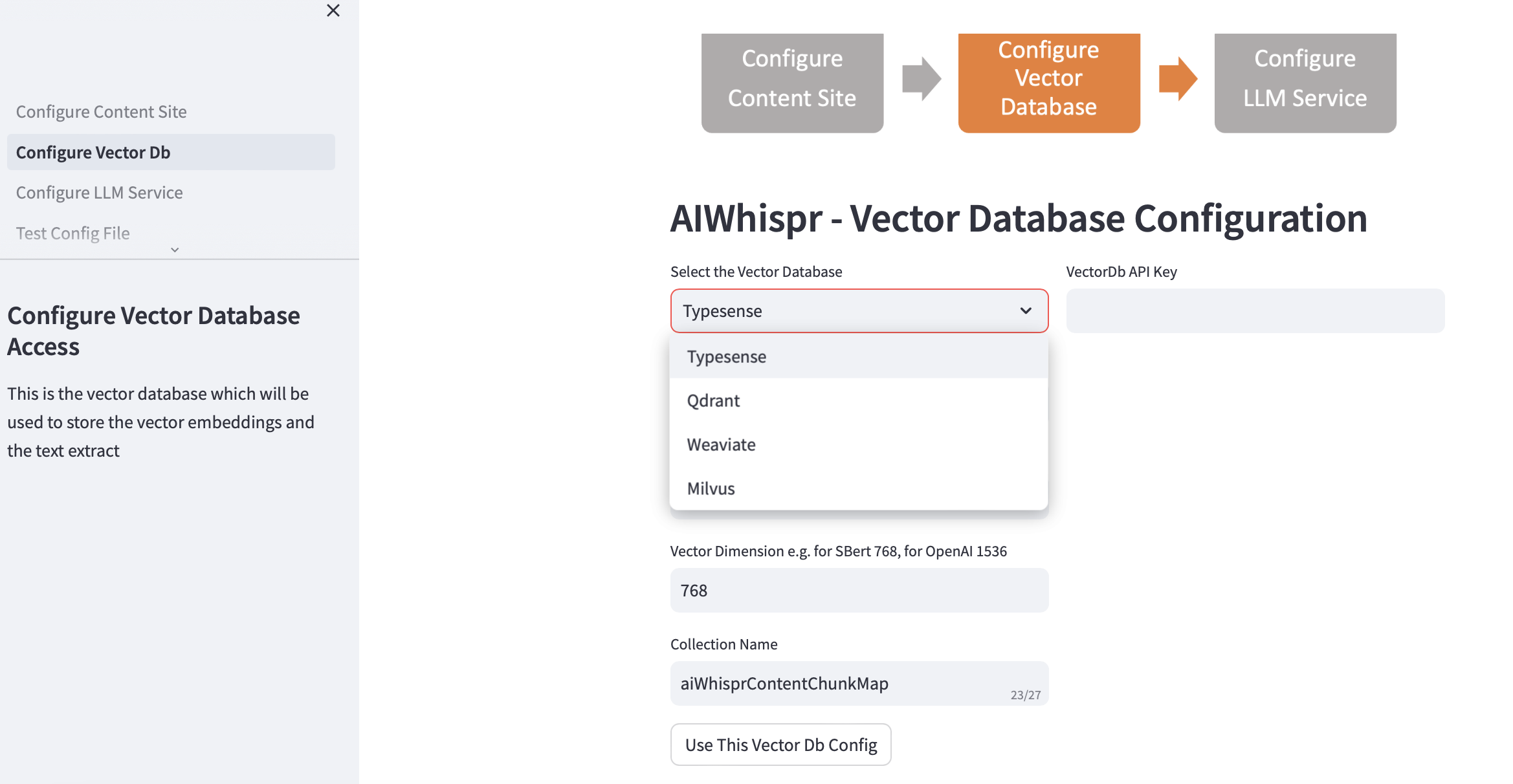
Vectordb を選択し、接続の詳細を指定します。
Vector データベースを選択すると、Vector Db の IP アドレスとポート番号がデフォルトのインストールに基づいて入力されます。これは設定に基づいて変更できます。
ベクトル データベースは認証用に構成されている必要があります。 Qdrant、Weaviate、Typesense の場合は API キーが必要です。 Milvus の場合は、 user-id とパスワードの組み合わせを設定する必要があります。
ベクトルの次元サイズは、テキストをベクトル埋め込みとしてエンコードするために使用する予定の LLM に基づいて指定する必要があります。例: Open AI「text-embedding-ada-002」の場合、これは OpenAI 埋め込みサービスによって返されるベクトルのサイズである 1536 として構成する必要があります。
Vector データベースに作成されるデフォルトのコレクション名は aiwhisprContentChunkMap です。独自のコレクション名を指定できます。
「Use This Vector Db Config」ボタンをクリックし、左側のサイドバーの「Configure LLM Service」をクリックして次のステップに進みます。
3.LLMサービスの構成
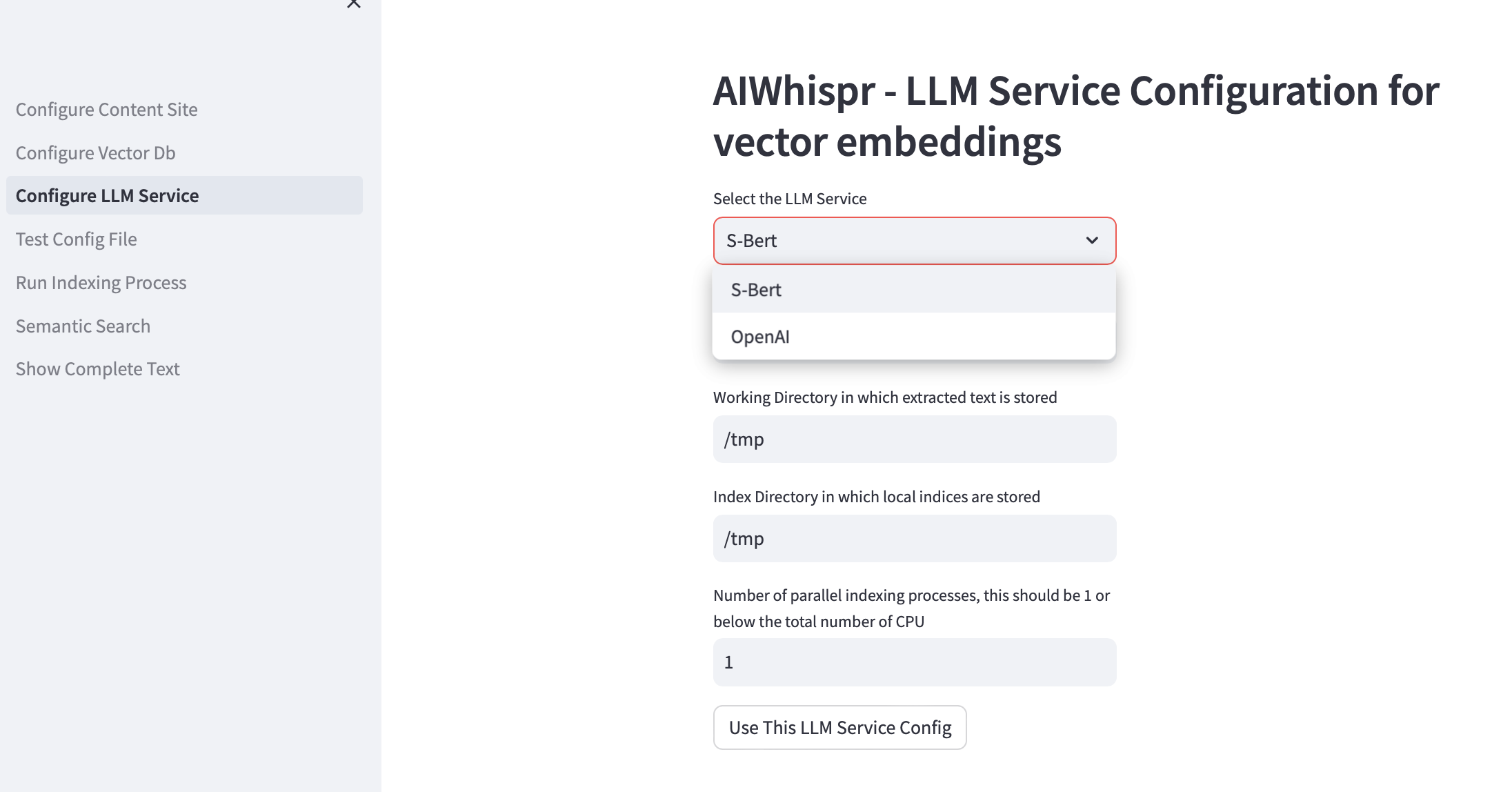
ローカルで実行される Sbert 事前トレーニング済みモデルを使用してベクトル埋め込みを作成するか、OpenAI API を使用するかを選択できます。
SBert モデル ファミリの場合、使用されるデフォルト モデルは all-mpnet-base-v2 です。別の SBert モデルを指定できます。
OpenAI の場合、デフォルトの埋め込みモデルは text-embedding-ada-002 です。
デフォルトの作業ディレクトリは /tmp です
作業ディレクトリは、保存場所から読み取られる/ダウンロードされるファイルを処理するための作業ディレクトリとして使用されるローカル マシン上の場所です。ドキュメントから抽出されたテキストは、より小さいサイズ (通常は 700 ワード) に分割され、ベクトル埋め込みとしてエンコードされます。 working-dir はテキスト チャンクを保存するために使用されます。
デフォルトのローカル インデックス作成ディレクトリは /tmp です。
作業ディレクトリとインデックス ディレクトリに永続的なローカル ディレクトリ パスを指定できます。
Index-dir は、読み取る必要があるコンテンツ ファイルのインデックス作成リストを保存するために使用されます。 AIWhispr はインデックス作成のための複数のプロセスをサポートしており、各プロセスは独自のインデックス作成リストを使用するため、マシン上の複数の CPU を活用できます。
インデックス作成 (コンテンツの読み取り、ベクター埋め込みの作成、ベクター データベースへの保存) に複数の CPU を活用する場合は、並列プロセスの数のテスト ボックスでこれを指定します。これを 1 または最大 (CPU の数/2) にすることをお勧めします。 8 CPU マシンの例では、これを 4 に設定する必要があります。AIWhispr はマルチプロセッシングを使用して Python GIL 制限を回避します。
[この LLM サービス構成を使用する] をクリックして、ベクター埋め込みパイプライン構成ファイルの最終バージョンを作成します。
構成ファイルの内容とマシン上のその場所が表示されます。
左側のサイドバーにある「構成ファイルのテスト」をクリックすると、この構成をテストできます。
4. テスト構成
ベクター埋め込みパイプライン構成ファイルの場所を示すメッセージと「Test Configfile」ボタンが表示されます。
ボタンをクリックすると、パイプライン構成をテストするプロセスが開始されます。
ログの最後に「NO ERRORS」というメッセージが表示され、このパイプライン構成が使用できることが示されます。
左側のサイドバーで「インデックス作成プロセスの実行」をクリックしてパイプラインを開始します。
5. インデックス作成プロセスの実行
[インデックス作成の開始] ボタンが表示されるはずです。
このボタンをクリックしてパイプラインを開始します。ログは 15 秒ごとに更新されます。
デフォルトの例では、2000 を超える BBC ニュース記事のインデックス作成に約 20 分かかります。
インデックス作成プロセスの実行中、つまり、右上に Streamlit の「実行中」ステータスが表示されている間は、このページから移動しないでください。
マシン上で grep を使用して、インデックス作成プロセスが実行されているかどうかを確認することもできます。
ps -ef | grep python3 | grep index_content_site.py
6. セマンティック検索
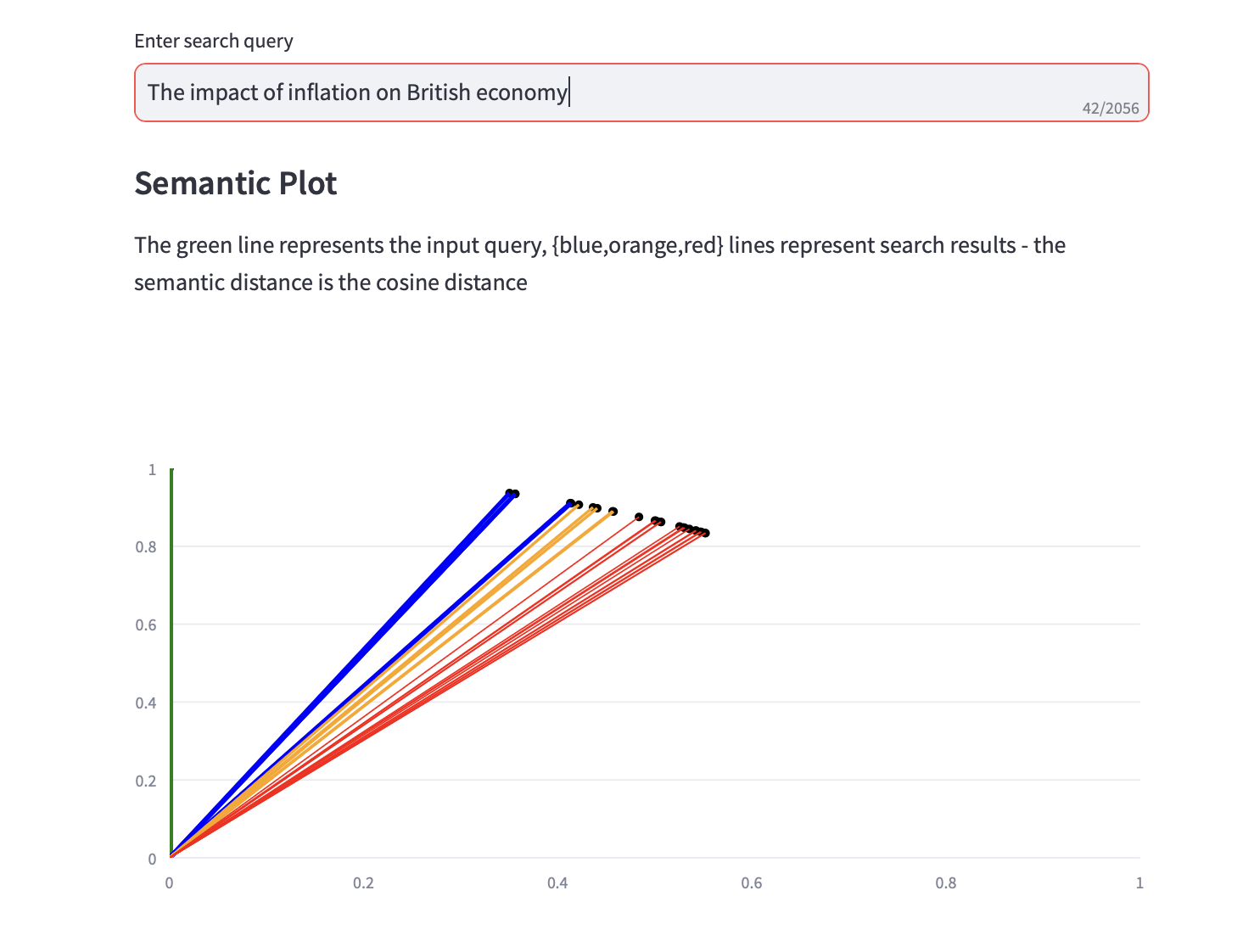
セマンティック検索クエリを実行できるようになりました。
検索結果のコサイン距離と上位 3 件の PCA 分析を表示するセマンティック プロットも、テキスト検索結果とともに表示されます。