lnx
v0.9.0 Master

豊富な機能 | ⚡ めちゃくちゃ速い
REST を介した Tantivy 検索エンジンの超高速で適応性のある展開。
lnx は車輪の再発明を行わないように構築されており、仕事を盗むランタイム、 tantivy 検索エンジンの生の計算能力と組み合わせたハイパーWeb フレームワークであるtokio-rsの上に立っています。
これにより、lnx は一度に何万もの文書挿入に対するミリ秒単位のインデックス作成 (インデックスが作成されるまで待つ必要がなくなります!)、インデックスごとのトランザクション、およびハッシュテーブルの別の検索のように検索を処理する機能を提供できるようになります。
lnx は非常に新しいものですが、基盤となるエコシステムのおかげで幅広い機能を提供します。
ここでは、2,700 万件のドキュメント データセットを入力しながら検索を実行している lnx が表示されます。インデックス付けされると妥当な 18 GB になります。高速ファジー システムで最大 3 GB の RAM を使用して i7-8700k で実行されました。試してみるより大きなデータセットはありますか?問題を開いてください!
lnx は、特定の使用例に合わせてシステムを微調整する機能を提供します。非同期ランタイム スレッドをカスタマイズできます。同時実行スレッド プール、リーダーおよびライター スレッドごとのスレッド、すべてインデックスごと。
これにより、コンピューティング リソースの使用先を詳細に制御できるようになります。大規模なデータセットがあるものの、同時読み取りの量は少ないですか?最大同時実行性を下げる代わりに、リーダー スレッドをバンプします。
以下の数値は、小さなmovies.jsonデータセットに対してlnx-cliによって取得されたものです。新しい Meilisearch エンジンはこれをいくらか改善しましたが、Meilisearch は何百万ものドキュメントのインデックスを作成するのに信じられないほど長い時間がかかるため、これ以上の値は試行しませんでした。
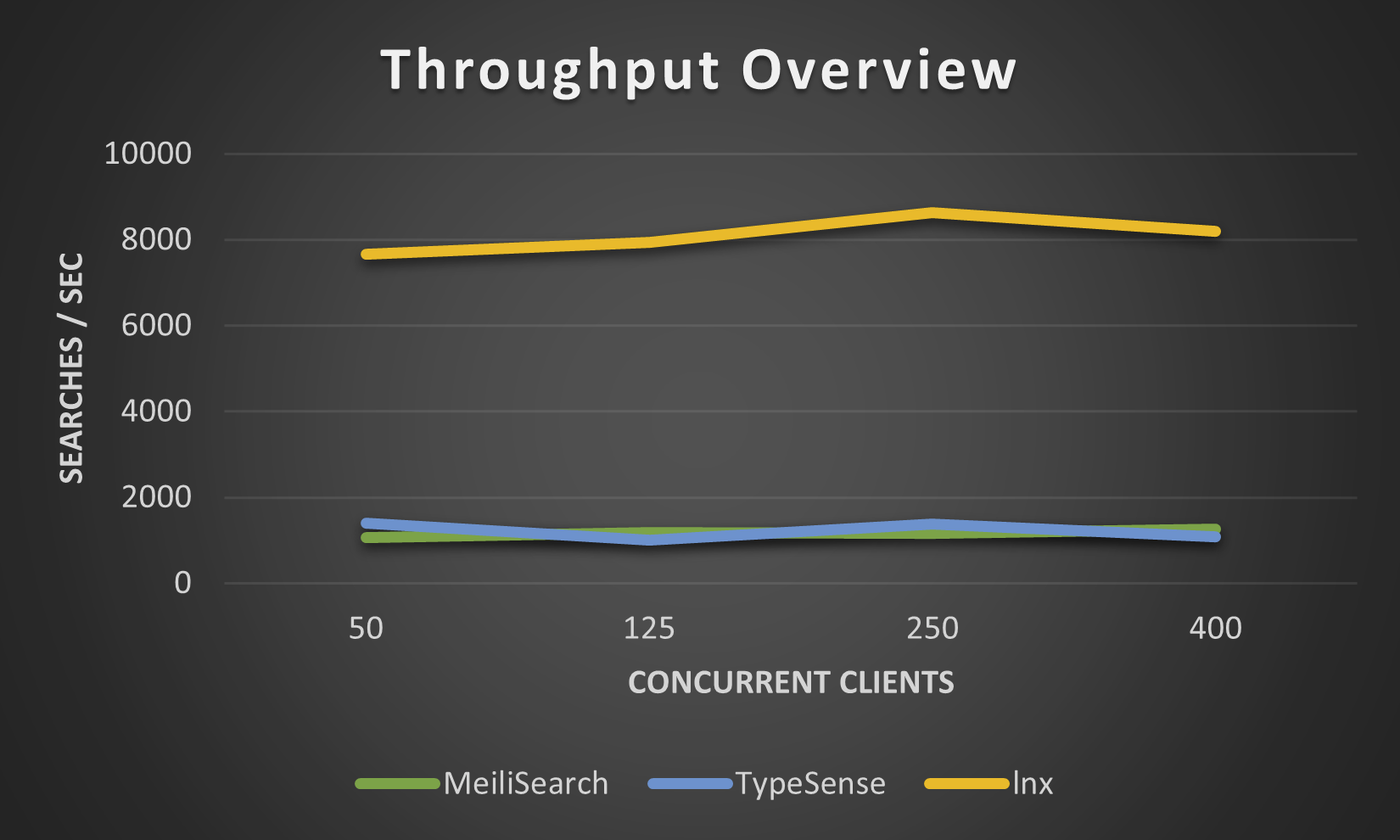
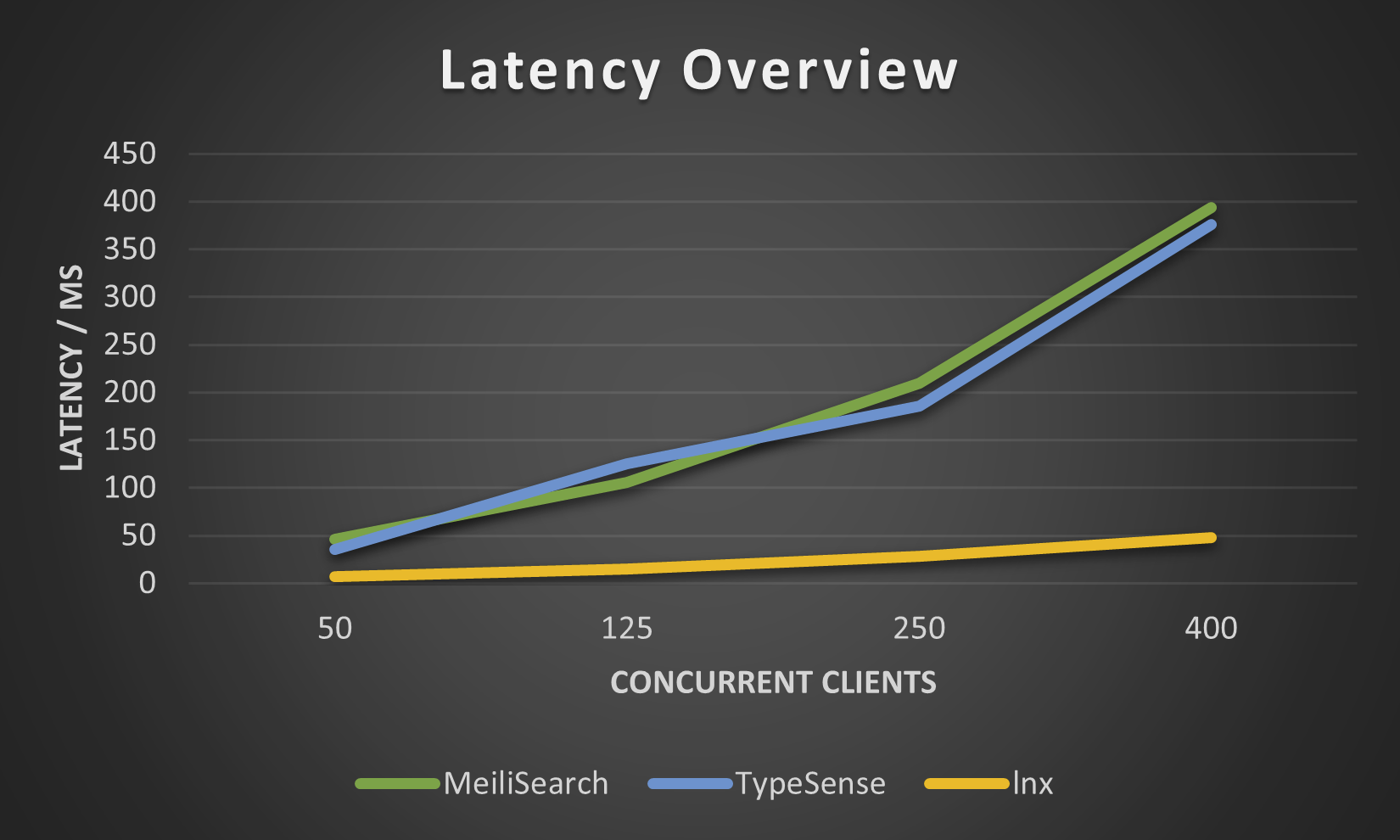
lnx は幅広い機能を提供しますが、これほど新しいシステムであるため、すべてを行うことはできません。当然のことながら、いくつかの制限があります。


