sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
メンテナ: jcudit と lsgos
プロジェクトは少なくとも (YYYY-MM-DD) まで維持されます: 2023-03-14
これは、Cohere API を使用して単純なセマンティック検索エンジンを構築する方法の例です。これは、本番環境に対応したり、効率的に拡張したりすることを目的としたものではなく (ただし、これらの目的に適合させることはできます)、Cohere の大規模言語モデル (LLM) によって生成された表現を利用した検索エンジンの作成の容易さを示すのに役立ちます。
ここで使用される検索アルゴリズムは非常に単純です。co.embed co.embedポイントを使用して、質問の表現に最もよく一致する段落を見つけるだけです。これについては以下で詳しく説明しますが、何が起こっているかを簡単に図で示します。まず、入力テキストを一連の段落に分割し、入力内のアドレスをリストに保存し、 co.embed使用して各段落のベクトル埋め込みを生成します。
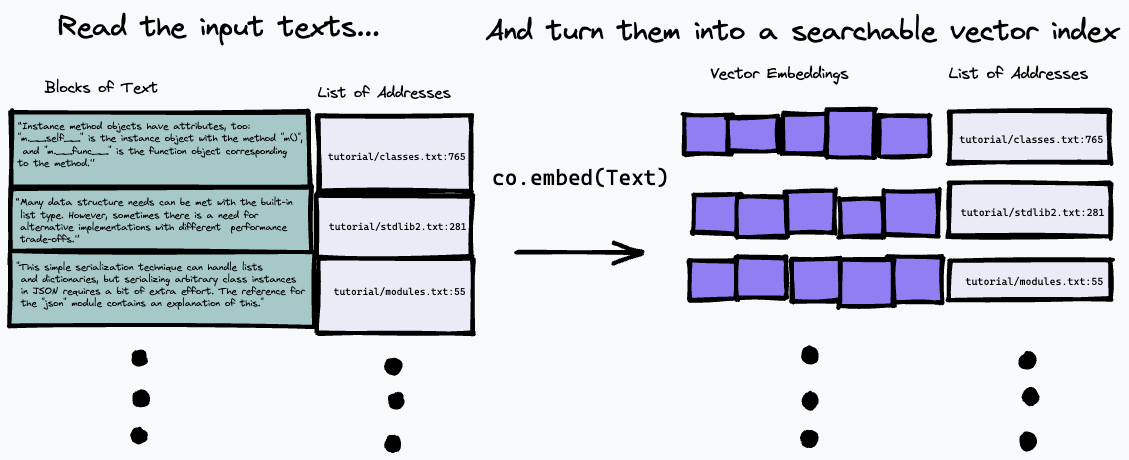
次に、テキスト クエリを埋め込み、ベクトル類似度 (コサイン類似度を使用しました) の尺度を使用して最も近い一致を持つソース テキスト内の段落を見つけることによって、インデックスをクエリできます。 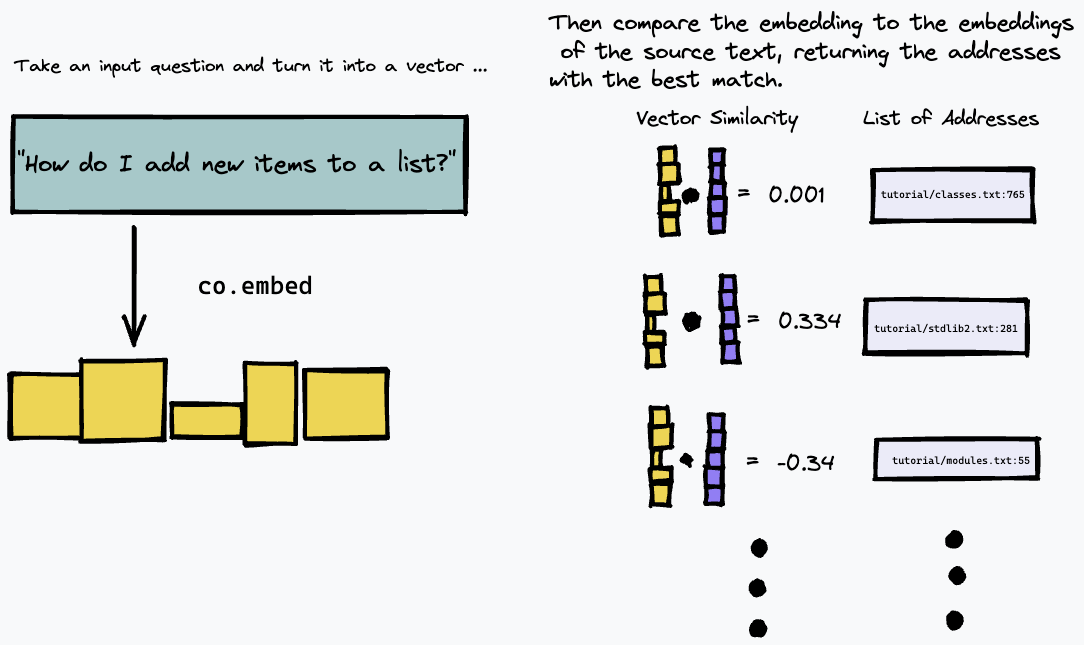
その結果、技術文書や具体的な指示や事実のリストとして構造化された内部 Wiki など、特定の質問に対する答えがテキスト内の具体的な段落によって提供される可能性が高いテキスト ソースで最もよく機能します。たとえば、情報が複数の段落にまたがる小説などの自由形式のテキストに関する質問に答える場合には、あまりうまく機能しません。これには、テキストのインデックスを作成する別の方法を使用する必要があります。
例として、このリポジトリは、最新の Python ドキュメントのテキスト バージョンに基づいて単純なセマンティック検索エンジンを構築します。
Python の要件をインストールするには、詩がインストールされていることを確認して、次を実行します。
# install python deps
poetry installdocker もインストールしておく必要があります。 OS X で homebrew を使用する場合は、次のコマンドを実行することをお勧めします。
brew install --cask dockerOS X で初めて docker を実行する (サーバーを実行するなど) 前に、Docker アプリを開いて、システム上で実行するために必要な権限を付与します。
COHERE_TOKENに Cohere API キーも必要です。 Cohere プラットフォームから取得し (必要に応じてアカウントを作成)、環境に書き込みます。
export COHERE_TOKEN= < MY_API_KEY > ( <MY_API_KEY>は、 <...>括弧を除いた、取得したキーです)。
あるいは、以下のmakeコマンドに追加の引数としてCOHERE_TOKEN=<MY_API_KEY>を渡すこともできます。
次の手順に従って、最初にドキュメント コレクションのセマンティック インデックスを構築します。これらの手順により、Python の公式ドキュメントのセマンティック インデックスが生成されますが、任意のデータ コレクションに適用できる可能性があります。
まず、次のコマンドのいずれかを実行して、Python ドキュメントをダウンロードします。
すぐに始めたい場合は、実行してください
make download-python-docs-smallドキュメントセットをPythonチュートリアルに限定します。結果は非常に限定的になるため、これは簡単なテストの場合にのみ行うことをお勧めします。
Python ドキュメント全体に対して検索エンジンをテストしたい場合は、次を実行します。
make download-python-docsただし、埋め込みの作成には数時間かかることに注意してください (ただし、これは 1 回だけ行う必要があります)。
あるいは、独自のテキストを試したい場合は、それをこのリポジトリのtxt/というディレクトリに.txtファイルとしてダウンロードします。
テキストを取得したら、それを処理して埋め込みとアドレスの検索インデックスを作成する必要があります。
これは、次のコマンドを使用して行うことができます
make embeddingsターゲットテキストが./txt/ディレクトリの下にあると仮定します。
このコマンドは、 ./txt/ディレクトリで拡張子.txtを持つファイルを再帰的に検索し、各段落の埋め込み、ファイル名、行番号の単純なデータベースを構築します。
警告: 検索するテキストが多い場合は、完了までに少し時間がかかることがあります。
embeddings.npzファイルを構築したら、次のコマンドを使用して、作成したデータベースをクエリできるようにする単純な REST アプリを提供する Docker イメージを構築できます。
make buildその後、次を使用してサーバーを起動できます
make runこれは単純な例としてはやややりすぎですが、大規模なテキスト本文のインデックスの構築が比較的遅いという事実を反映し、エンジンへのクエリが高速になるように設計されています。
このプロジェクトを実際のアプリケーションの構成要素として使用したい場合は、テキスト埋め込みのデータベースをサーバー アーキテクチャで維持し、軽量クライアントでクエリを実行することになるでしょう。サーバーを Docker アプリケーションとしてパッケージ化すると、これをクラウド サービスにデプロイすることで「実際の」アプリケーションに変えるのが非常に簡単になります。
以下のオプションのいずれかを行うために新しいターミナル ウィンドウを開いた場合は、必ず次のコマンドを実行してください。
export COHERE_TOKEN= < MY_API_KEY > これまでのところ最も簡単なオプションは、ヘルパー スクリプトを実行することです。
scripts/ask.sh " My query here "データベースにクエリを実行します。スクリプトは、必要な結果の数を指定するオプションの 2 番目の引数を受け取ります。
スクリプトは、次のコマンドを使用して、変更された vim インターフェイスをポップアップ表示します。
q押してください。上部のペインには、結果が見つかった文書内の位置が表示されます。
サーバーが実行されたら、単純な REST API を使用してサーバーにクエリを実行できます。ここで/docs#/default/search_search_postにアクセスすると、API を直接探索できます。これは単純な JSON REST API です。ここでは、 curl使用してクエリを実行する方法を示します。
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
これにより、長さnum_resultsの JSON リストが返されます。それぞれには、クエリにセマンティックに最も近いブロックのファイル名と行番号 ( doc_urlおよびblock_url ) が含まれます。しかし、おそらく実際には、最良の答えとなるファイルの一部を読みたいだけでしょう。
ローカル テキスト ファイルを検索しているため、コマンド ライン ツールを使用して出力を解析する方が実際には少し簡単です。提供されている Python スクリプトutils/query_server.py使用して、コマンド ラインでクエリを実行します。 query_server.py結果を標準のfile_name:line_number:形式で出力するため、 vimのクイックフィックス モードを活用して実際の結果を適切な方法でページングすることができます。
マシン上に vim があると仮定すると、次のことができます。
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
vim に、検索アルゴリズムによって返された場所にあるインデックス付きテキスト ファイルを開かせるようにします。 (ウィンドウとクイックフィックスナビゲータの両方を閉じるには:qallを使用します)。 :cnおよび:cpを使用して、返された結果を循環できます。結果は完璧ではありません。これはセマンティック検索なので、一致が少しあいまいになることが予想されます。それにもかかわらず、最初のいくつかの結果で質問に対する答えが得られることがよくあります。Cohere の API を使用すると、質問を自然言語で表現でき、わずか数行のコードで驚くほど効果的な検索エンジンを構築できます。
Python ドキュメントの場合、一般的な自然言語の質問に対して検索がうまく機能することを示す、試してみる価値のあるクエリをいくつか示します。
How do I put new items in a list? (この質問はキーワード「追加」の使用を避けており、ドキュメントで追加について説明されている方法と正確に一致していないことに注意してください(追加はリストの最後に新しい項目を追加するために使用されると言われています)。しかし、セマンティック検索は、関連する段落が依然として最適です。)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (この質問について注意してください。私にとっての最初の結果は、基本的にこの正確なトピックに関する FAQ ですが、質問の表現が異なります。ただし、セマンティック検索であるため、アルゴリズムは、意味だけでなく、意味に一致する結果を正しく選択します。私たちの質問の文言)How do I remove an item from a set?How do list comprehensions work?このリポジトリでは、非常に単純な戦略を使用してドキュメントにインデックスを付け、最も一致するものを検索します。まず、すべての文書を段落、つまり「ブロック」に分割します。次に、Cohere の言語モデルを使用してベクトル埋め込みを生成するために、各段落でco.embed呼び出します。次に、各埋め込みベクトルを、対応するドキュメントと段落の行番号とともに、単純な配列に「データベース」として保存します。
実際に検索を行うには、FAISS 類似検索ライブラリを使用します。クエリを取得すると、同じ Cohere API 呼び出しを使用してクエリを埋め込みます。次に、FAISS を使用してトップを見つけます
ご質問やコメントがある場合は、問題を報告するか、Discord でご連絡ください。
このプロジェクトに貢献したい場合は、プル リクエストを送信する前に、このリポジトリのCONTRIBUTORS.md読み、コントリビューター ライセンス契約に署名してください。 Cohereリポジトリに初めてプル・リクエストを行うと、Cohere CLAに署名するためのリンクが生成されます。
Toy Semantic Search には、LICENSE ファイルにあるように MIT ライセンスがあります。


