wagtail_textract
1.0.0
このパッケージはメンテナンスされておらず、メンテナンスする予定もありません。
これを例として使用し、コードを独自のプロジェクトにコピーすることをお勧めしますが、パッケージはインストールしないでください。
このパッケージは、Wagtail の Document クラスを、texttract を使用して Document ファイルの内容を検索できるクラスに置き換えるためのものです。
Textract は、PDF、Excel、Word ファイルなどからテキストを抽出できます。
このパッケージは、Wagtail の「検索: 文書からテキストを抽出する」の問題からインスピレーションを得たものです。
ドキュメントは以前と同様に機能しますが、Wagtail の管理インターフェイスでのドキュメント検索ではファイルのコンテンツ内の検索語も検索される点が異なります。
いくつかのスクリーンショットを説明します。
wagtail_textractがインストールされた新しいセキレイ サイトに、手書きのテキストが含まれる te test_document.pdfというファイルをアップロードしました。これは、管理インターフェイスの「ドキュメント」の下にリストされます。
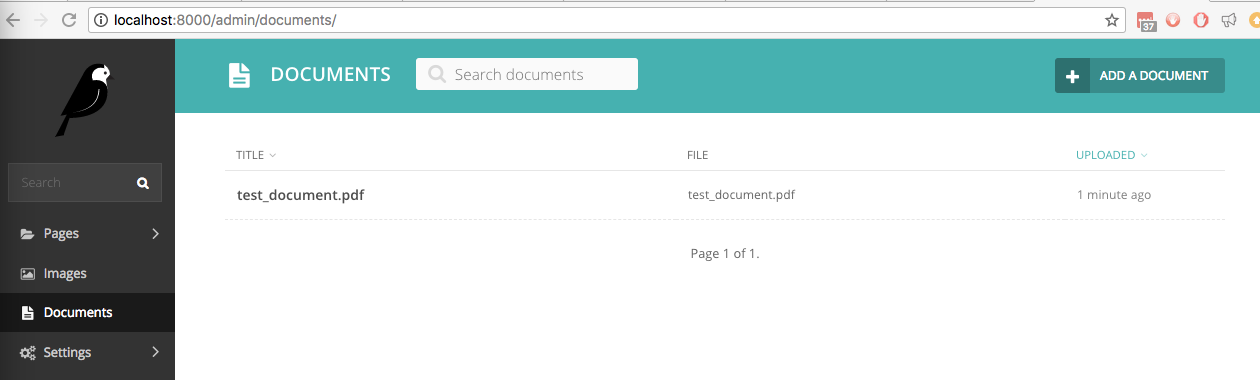
ここで、ドキュメント内で手書きの単語の 1 つである単語correct 」を検索すると、ライブ検索でそれが見つかります。
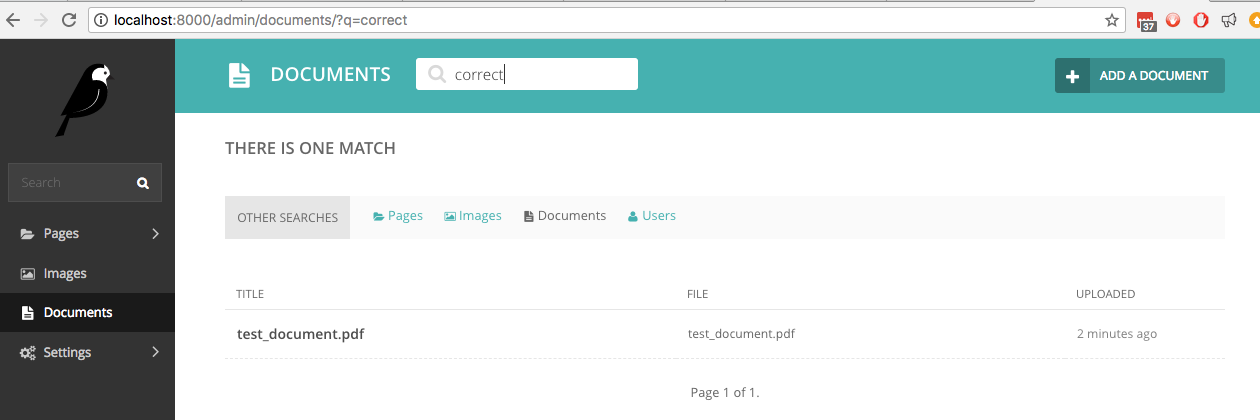
この検索は、Wagtail の管理インターフェイスだけでなく、一般向けの検索ビューでも利用できることが前提となっており、そのためのコード例が提供されています。
2018 年 8 月以来、https://nuffic.nl でこのパッケージを運用環境で使用しています。
wagtail_textract要件に追加するか、 pip install wagtail_textractINSTALLED_APPSに追加します。WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document"と入力します。注: wagtail_texttract のインストール中に、非互換性の警告が表示されます (Wagtail 2.0.1 がインストールされています)。
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
これが問題につながることは確認されていませんが、留意する必要があります。
textract Tesseract を使用できるようにするには (通常のtextractテキストが見つからなかった場合に発生します)、Tesseract が単語一致の基礎となるデータ ファイルを追加する必要があります。
プロジェクト ディレクトリにtessdataディレクトリを作成し、必要な言語をダウンロードします。
文書の保存後に、処理中に応答がブロックされるのを防ぐために、 asyncio executor で文字起こしが自動的に行われます。
既存のすべてのドキュメントを転記するには、次の管理コマンドを実行します。
./manage.py transcribe_documents
もちろん、これには長い時間がかかるかもしれません。
これは、ページとドキュメントの両方の結果を表示する検索ビュー (Wagtail の管理インターフェイスの外側) のコード例です。
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
})ドキュメントではpageurl resultを実行できないため、テンプレートではドキュメントをページとは異なる方法で処理できるようにする必要があります。
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} wagtail_textrac を使用するには、 CustomizedDocumentモデルが wagtail_textrac の Document と同じことを行う必要があります。
TranscriptionMixinsearch_fieldsを変更する from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
]サブクラス化する最初のクラスはTranscriptionMixinである必要があるため、そのsave()他の親クラスよりも優先されることに注意してください。
テストを実行するには、このリポジトリをチェックアウトし、次の操作を行います。
make test
カバレッジ レポートは./coverage_html_report/に生成されます。


