SeekStorm
v0.11.0

SeekStorm は、 Rustで実装されたオープンソースのミリ秒未満の全文検索ライブラリおよびマルチテナント サーバーです。
開発は 2015 年に開始され、2020 年から運用開始、2023 年に Rust ポート、2024 年にオープンソース化され、作業が進行中です。
SeekStorm は、Apache License 2.0 に基づいてライセンス供与されたオープンソースです。
ブログ投稿: SeekStorm がオープンソースになり、SeekStorm にファセット検索、地理的近接検索、結果の並べ替えが追加されました
クエリの種類
結果の種類
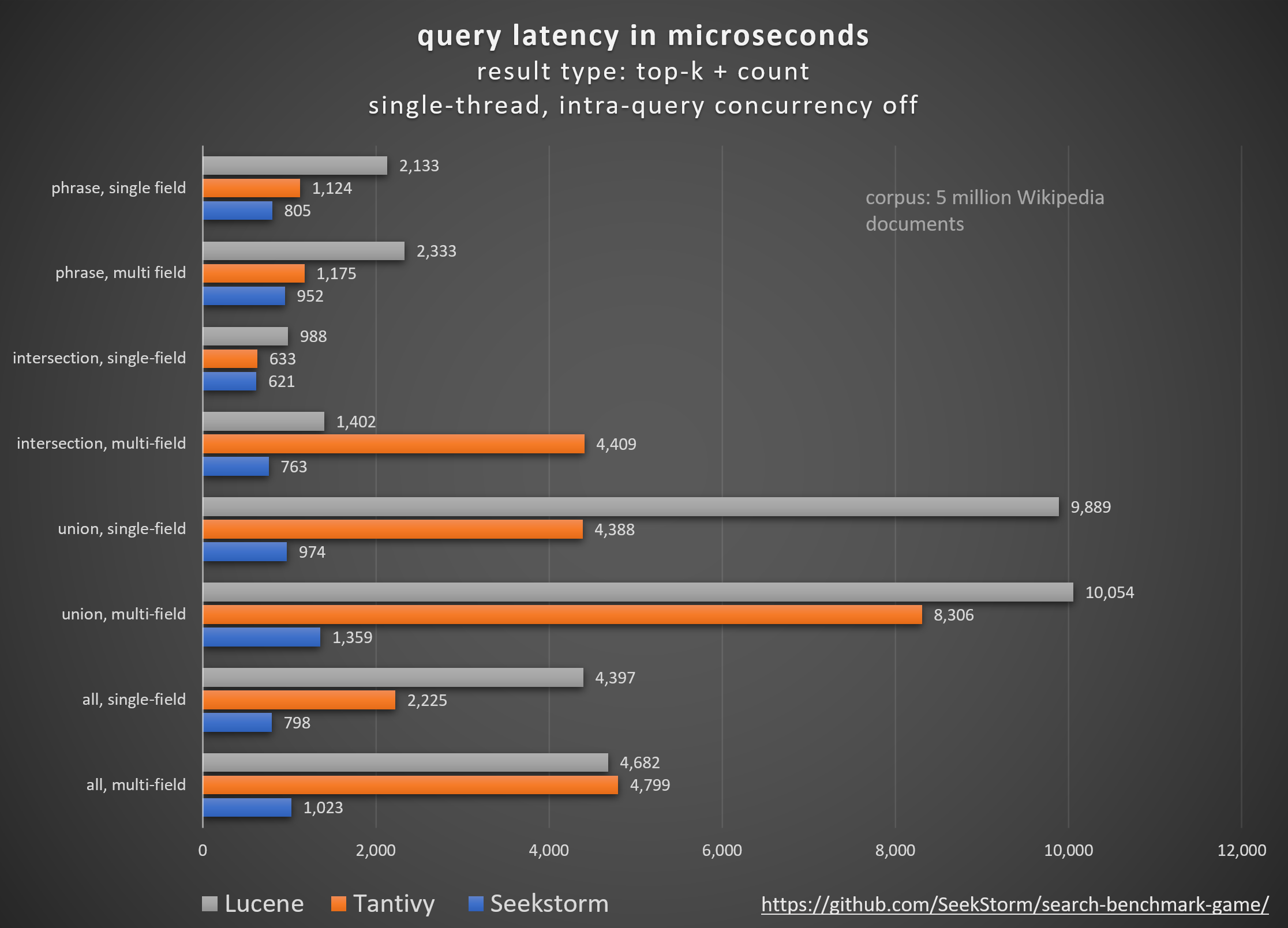
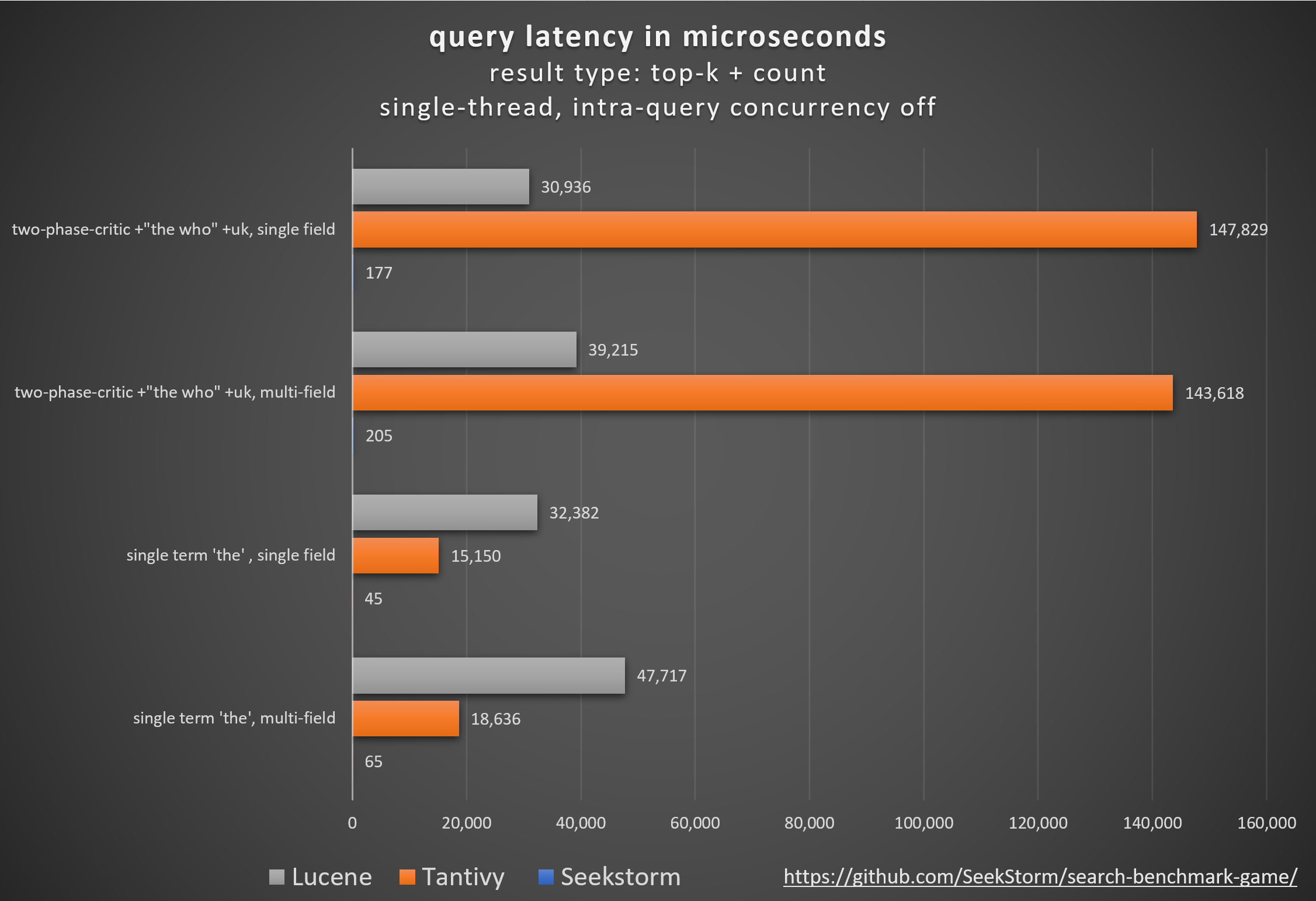
パフォーマンス
待ち時間の短縮、スループットの向上、コストとエネルギー消費の削減、特に。複数フィールドおよび同時クエリの場合。
テール レイテンシーが低いため、スムーズなユーザー エクスペリエンスが確保され、顧客と収益の損失が防止されます。
パフォーマンスを向上させるために独自のハードウェア アクセラレータ (FPGA/ASIC) やクラスターに依存するものもありますが、
SeekStorm は、単一の商品サーバー上でアルゴリズム的に同様のブーストを実現します。
一貫性
SeekStorm はリソースを大量に消費するセグメントのマージを必要としないため、大量のインデックス作成中および作成後に予測できないクエリ遅延が発生しません。
安定したレイテンシ - ジャストインタイム コンパイルによるコールド スタートのコストがなく、予測できないガベージ コレクションの遅延もありません。
スケーリング
10 億規模のインデックスであっても、低遅延、高スループット、低 RAM 消費量を維持します。
フィールド数、フィールド長、インデックス サイズは無制限です。
関連性
用語近接ランキングは、BM25 と比較して、より関連性の高い結果を提供します。
リアルタイム
NRT とは対照的な真のリアルタイム検索: インデックス付けされたすべてのドキュメントは、コミット前およびコミット中であっても即座に検索可能です。
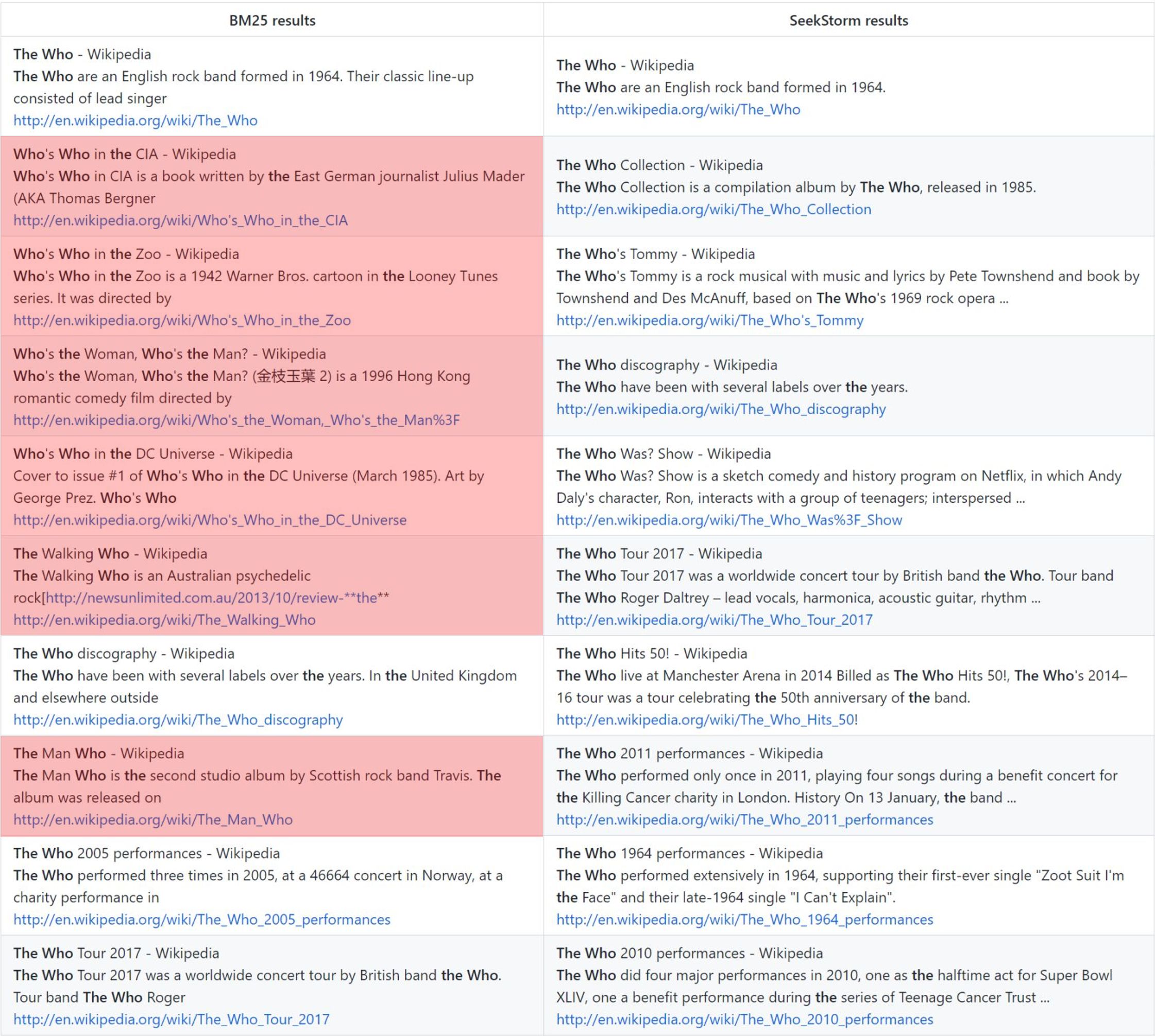
the who: バニラ BM25 ランキング vs. SeekStorm 近接ランキング
方法論
Tantivy と Jason Wolfe が開発したオープンソースのsearch_benchmark_gameを使用して、さまざまなオープンソースの検索エンジン ライブラリ (BM25 字句検索) を比較します。
利点
詳細なベンチマーク結果https://seekstorm.github.io/search-benchmark-game/
ベンチマークコードリポジトリhttps://github.com/SeekStorm/search-benchmark-game/
詳細については、ブログ投稿を参照してください: SeekStorm がオープンソースになり、SeekStorm にファセット検索、地理的近接検索、結果の並べ替えが追加されました
誇大広告 https://www.bitecode.dev/p/hype-cycles があなたに信じてほしいことにもかかわらず、NoSQL が SQL の死ではなかったように、キーワード検索は死んだわけではありません。
ツールボックスを維持し、目の前のタスクに最適なツールを選択する必要があります。 https://seekstorm.com/blog/vector-search-vs-keyword-search1/
キーワード検索は、ドキュメントのセットに対する単なるフィルターであり、特定のキーワードが出現するドキュメントを返します。通常は、BM25 などのランキング指標と組み合わせられます。非常に基本的かつ中核的な機能ですが、低遅延で大規模に実装するのは非常に困難です。機能が非常に基本的なため、応用分野は無限にあります。これは、他のコンポーネントと一緒に使用するコンポーネントです。現在、ベクトル検索と LLM を使用してより適切に解決できるユースケースがありますが、さらに多くの場合、キーワード検索が依然として最適なソリューションです。キーワード検索は正確かつロスレスで、非常に高速であり、スケーリング、遅延が改善され、コストとエネルギー消費が低くなります。ベクトル検索は意味的な類似性を利用して機能し、指定された近接性と確率で結果を返します。
固有名、番号、ナンバー プレート、ドメイン名、フレーズ (盗作検出など) などの正確な結果を検索する場合は、キーワード検索が役立ちます。一方、ベクトル検索では、意味的に何らかの関連があるだけの無数の結果の中に、探している正確な結果が埋もれてしまいます。同時に、正確な用語を知らない場合、またはより広範なトピック、意味、または同義語に興味がある場合は、正確な用語がどのように使用されているかに関係なく、キーワード検索は失敗します。
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.ベクトル検索は、正確なクエリ用語がわからない場合、または使用されている正確なクエリ用語に関係なく、より広範なトピック、意味、または同義語に興味がある場合に最適です。ただし、固有名、番号、ナンバー プレート、ドメイン名、フレーズ (盗作検出など) などの正確な用語を探している場合は、常にキーワード検索を使用する必要があります。ベクトル検索では、何らかの関連性があるだけの無数の結果の中に、探している正確な結果が埋もれてしまいます。再現率は優れていますが、精度が低く、遅延が長くなります。正確な単語と語順が失われるため、盗作検出などで誤検知が発生する傾向があります。
ベクター検索を使用すると、類似したテキストだけでなく、ベクターに変換できるすべてのもの (テキスト、画像 (顔認識、指紋)、音声) を検索でき、女王 - 女性 + 男性 = 王などの魔法のようなことも可能になります。 。
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationベクトル検索はキーワード検索に代わるものではなく、それを補完するものであり、両方のアプローチの長所を組み合わせたハイブリッド ソリューション内で使用するのが最適です。キーワード検索は時代遅れではなく、長年の実績があります。
SeekStorm コードベースを C# から Rust に (部分的に) 移植しました。
Rust は、ビッグデータや多数の同時ユーザーを扱うパフォーマンスが重要なアプリケーションに最適です。高速アルゴリズムは、パフォーマンスを重視したプログラミング言語を使用するとさらに輝きます?
ARCHITECTURE.md を参照してください。
cargo build --release
警告: MASTER_KEY_SECRET 環境変数を必ずシークレットに設定してください。そうしないと、生成された API キーが危険にさらされます。
https://docs.rs/seekstorm
ビルドドキュメント
cargo doc --no-deps
ローカルでドキュメントにアクセスする
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
必要なクレートをプロジェクトに追加する
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;非同期Rustランタイムを使用する
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {インデックスを作成する
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;インデックスを開く (またはインデックスを作成する)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; ドキュメントのインデックス付け
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; ドキュメントをコミットする
index_arc . commit ( ) . await ;検索インデックス
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;結果を表示する
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}マルチスレッド検索
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}JSON、改行区切り JSON、および連結 JSON 形式のインデックス JSON ファイル
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;ディレクトリおよびサブディレクトリ内のすべての PDF ファイルにインデックスを付ける
ingestコマンドによって自動的に作成されます)。 [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;インデックスPDFファイル
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;PDF ファイルのバイトのインデックス付け
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;PDF ファイルのバイトを取得する
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;クリアインデックス
index . clear_index ( ) ;インデックスの削除
index . delete_index ( ) ;インデックスを閉じる
index . close_index ( ) ;シークストーム ライブラリのバージョン文字列
let version= version ( ) ;
println ! ( "version {}" ,version ) ;ファセットは 3 つの異なる場所で定義されます。
ファセットインデックス作成と検索の最小限の動作例には、わずか 60 行のコードが必要です。しかし、ドキュメントだけからすべてを理解するのは退屈かもしれません。このため、ここでクイック スタートの例を提供します。
必要なクレートをプロジェクトに追加する
cargo add seekstorm
cargo add tokio
cargo add serde_json使用宣言を追加する
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;非同期Rustランタイムを使用する
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {インデックスを作成する
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;ドキュメントのインデックス付け
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; ドキュメントをコミットする
index_arc . commit ( ) . await ;検索インデックス
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;結果を表示する
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}ファセットを表示する
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;メイン関数の終わり
Ok ( ( ) )
} SeekStorm サーバーを使用して、Wikipedia コーパスから Wikipedia 検索エンジンを 5 つの簡単なステップで構築する方法についての簡単なステップバイステップのチュートリアルです。

ダウンロード
GitHub リポジトリから SeekStorm をダウンロードする
選択したディレクトリに解凍し、Visual Studio コードで開きます。
またはその代わりに
git clone https://github.com/SeekStorm/SeekStorm.git
SeekStormを構築する
Rust をインストールします (まだ存在しない場合): https://www.rust-lang.org/tools/install
Visual Studio Code のターミナルで次のように入力します。
cargo build --release
ウィキペディアのコーパスを取得する
前処理された英語版 Wikipedia コーパス (5,032,105 文書、解凍後 8,28 GB)。 wiki-articles.json には .JSON 拡張子が付いていますが、有効な JSON ファイルではありません。これはテキスト ファイルであり、各行に URL、タイトル、本文の属性を持つ JSON オブジェクトが含まれています。この形式は ndjson (「改行区切りの JSON」) と呼ばれます。
ウィキペディアのコーパスをダウンロードする
Wikipedia コーパスを解凍します。
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
解凍した wiki-articles.json をリリース ディレクトリに移動します。
SeekStormサーバーの起動
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
インデックス作成
実行中の SeekStorm サーバーのコマンド ラインに「ingest」と入力します。
ingest
これにより、デモのインデックスが作成され、ローカルの wikipedia ファイルにインデックスが付けられます。
埋め込み WebUI 内で検索を開始します
ブラウザで埋め込み Web UI を開きます: http://127.0.0.1
検索ボックスにクエリを入力します
REST API エンドポイントのテスト
VSC 拡張機能「Rest client」とともに VSC で src/seekstorm_server/test_api.rest を開き、API 呼び出しを実行し、応答を検査します。
インタラクティブ API エンドポイントの例
test_api.rest の「個別の API キー」を、上で「index」と入力したときにサーバー コンソールに表示される API キーに設定します。
デモインデックスを削除する
実行中の SeekStorm サーバーのコマンド ラインに「delete」と入力します。
delete
サーバーをシャットダウンする
実行中の SeekStorm サーバーのコマンドラインに「quit」と入力します。
quit
カスタマイズ中
自分のプロジェクトでも同様のものを使用したいですか?インジェストと Web UI のドキュメントを参照してください。
SeekStorm サーバーを使用して、PDF ファイルを含むディレクトリから PDF 検索エンジンを構築する方法に関する簡単なステップバイステップのチュートリアルです。
すべての科学論文、電子ブック、履歴書、レポート、契約書、文書、マニュアル、手紙、銀行取引明細書、請求書、納品書を自宅または組織内で検索できるようにします。
SeekStormを構築する
Rust をインストールします (まだ存在しない場合): https://www.rust-lang.org/tools/install
Visual Studio Code のターミナルで次のように入力します。
cargo build --release
PDFiumをダウンロード
Pdfium ライブラリをダウンロードして、seekstorm_server.exe と同じフォルダーにコピーします: https://github.com/bblanchon/pdfium-binaries
SeekStormサーバーの起動
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
インデックス作成
ドキュメントやダウンロード ディレクトリなど、インデックスを作成して検索する PDF ファイルが含まれるディレクトリを選択します。
実行中の SeekStorm サーバーのコマンド ラインに「ingest」と入力します。
ingest C:UsersJohnDoeDownloads
これにより、pdf_index が作成され、指定されたディレクトリにあるサブディレクトリを含むすべての PDF ファイルのインデックスが作成されます。
埋め込み WebUI 内で検索を開始します
ブラウザで埋め込み Web UI を開きます: http://127.0.0.1
検索ボックスにクエリを入力します
デモインデックスを削除する
実行中の SeekStorm サーバーのコマンド ラインに「delete」と入力します。
delete
サーバーをシャットダウンする
実行中の SeekStorm サーバーのコマンドラインに「quit」と入力します。
quit
全文検索 3,000 万件のハッカー ニュース投稿およびリンクされた Web ページ
DeepHN.org
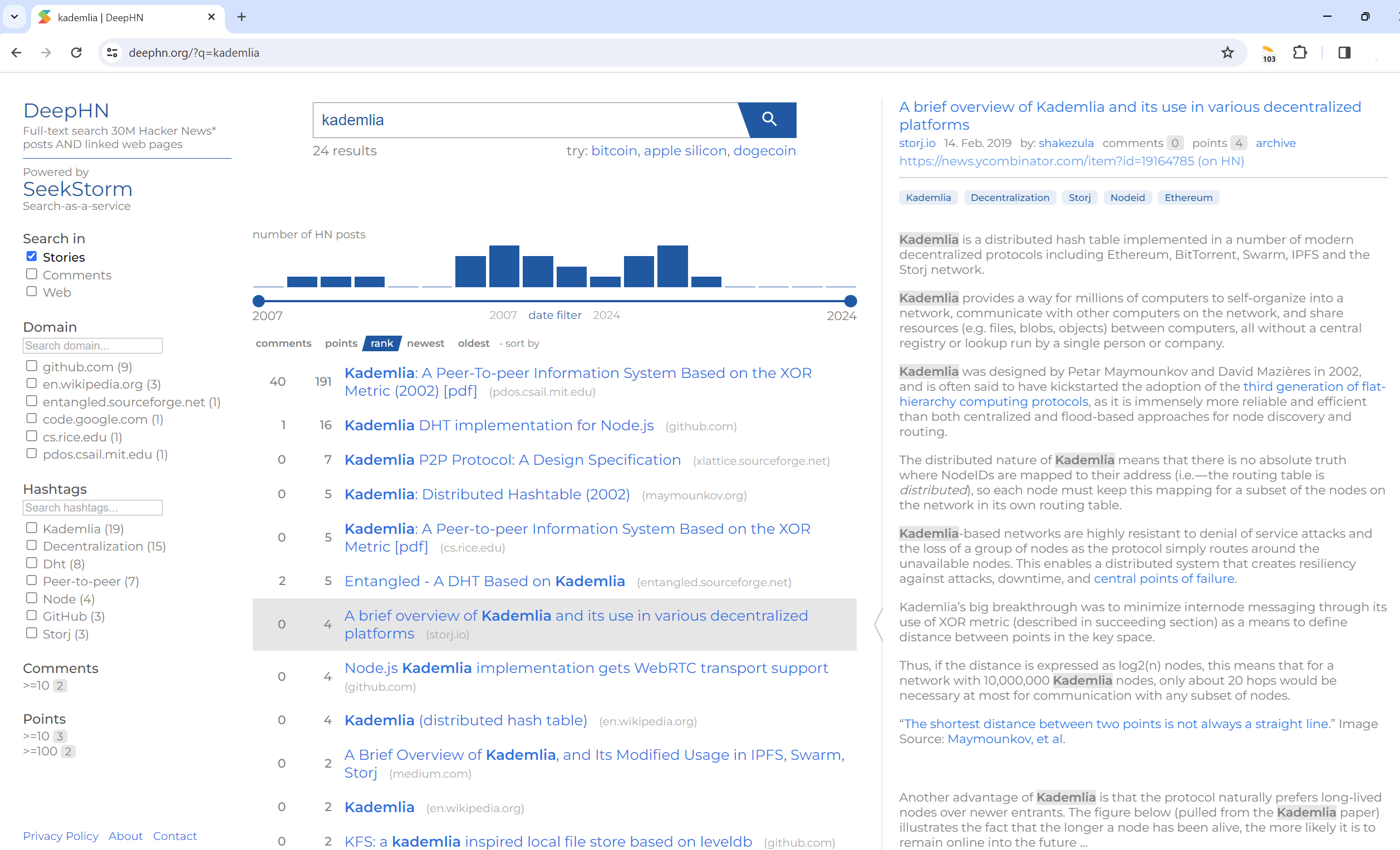
DeepHN デモは依然として SeekStorm C# コードベースに基づいています。
現在、不足している必要な機能をすべて移植中です。
以下のロードマップを参照してください。
Rust ポートはまだ機能が完成していません。現在、次の機能が移植されています。
移植
改善点
新機能


