elastic_transformers
1.0.0
センテンストランスフォーマーを使用したセマンティックエラスティックサーチ。 Elastic の力と BERT の魔法を使用して、100 万件の記事にインデックスを付け、それらに対して語彙検索と意味検索を実行します。
その目的は、NLP トランスフォーマーを使用したコンテキスト埋め込み/セマンティック検索のほぼ最先端の機能を備えた独自の Elasticsearch をセットアップする使いやすい方法を提供することです。
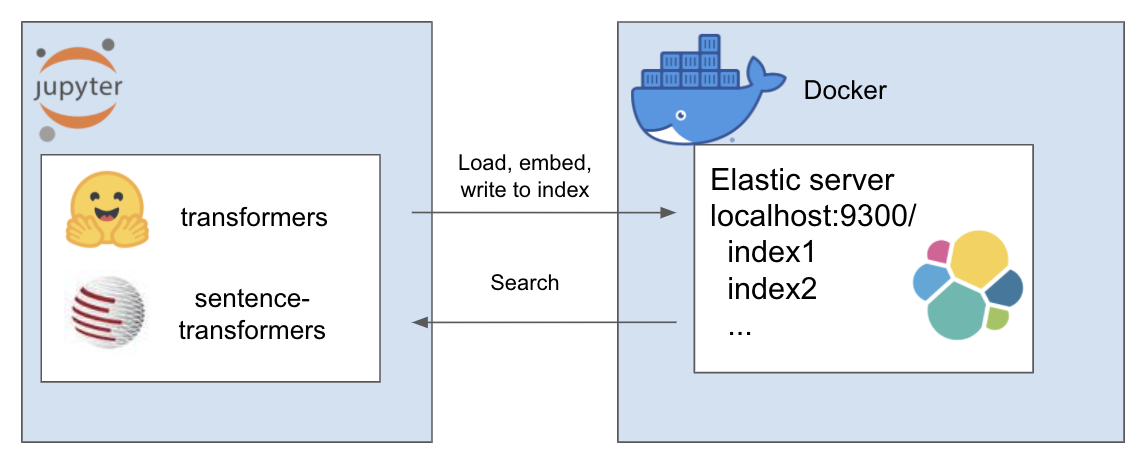
上記の設定は次のように機能します
私の環境はetと呼ばれており、これには conda を使用します。プロジェクト ディレクトリ内に移動する
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtこのチュートリアルでは、Rohk の A Million News Headlines を使用し、プロジェクト ディレクトリ内のデータ フォルダーに配置します。
elastic_transformers/
├── data/
それ以外の場合、ステップはかなり抽象化されているため、選択したデータセットでこれを実行することもできることがわかります。
こちらの Elastic のページから、Docker を使用して Elastic をセットアップする手順に従ってください。このチュートリアルでは、次の 2 つの手順を実行するだけで済みます。
このリポジトリでは、ElasiticTransformers クラスが導入されています。埋め込みを含む Elasticsearch インデックスの作成、インデックス作成、クエリを支援するユーティリティ
接続リンクと (オプションで) 操作するインデックスの名前を開始します。
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_specインデックスのマッピングを定義します。関連フィールドのリストは、キーワード検索またはセマンティック (密ベクトル) 検索に提供できます。また、密ベクトルのサイズを変更できるパラメーターもあります。 create_index - 前に作成した仕様を使用して、検索可能なインデックスを作成します。
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - 大きな CSV ファイルをチャンクに分割し、事前定義された埋め込みユーティリティを繰り返し使用して各チャンクの埋め込みリストを作成し、結果をインデックスにフィードします。
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )検索- キーワード (Elastic では「一致」) またはセマンティック (Elastic では密) 検索のいずれかを選択できます。特に、write_large_csv で使用されるのと同じ埋め込み関数が必要です。
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )セットアップが成功したら、次のノートブックを使用してこれをすべて機能させます。
このリポジトリは、優秀な人々による以下の素晴らしい作品を組み合わせたものです。まだ作品を見ていない方はぜひチェックしてみてください...


