lieu
vements
代替の検索エンジン
ハイパーテキストの検索と発見の使用に関する無関心な環境に応えて作成されました。代わりに、インターネットは検索可能にするものではなく、自分自身の近所を検索可能にするものです。言い換えれば、Lieu は近所の検索エンジンであり、個人のウェブリングが偶然のつながりを増やすための手段です。
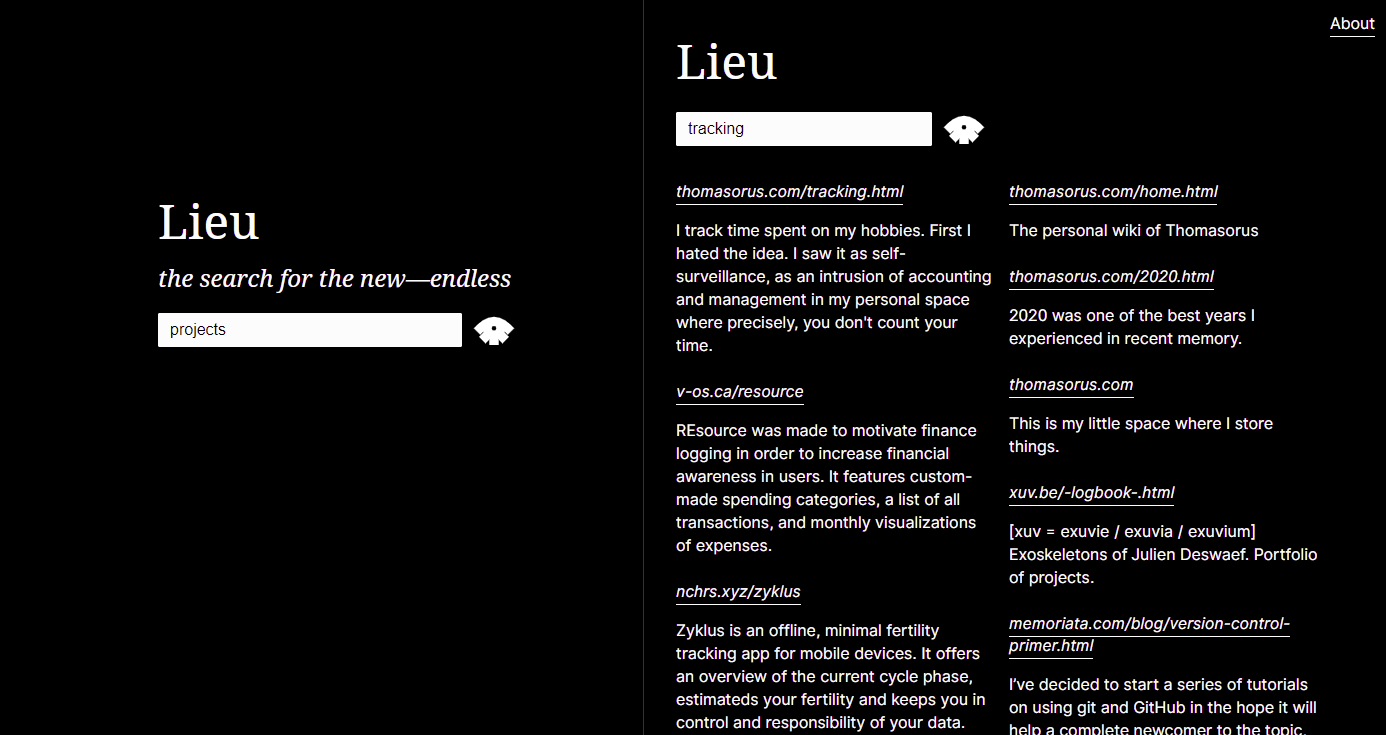
完全な検索構文 ( site:および-site:の使用方法を含む) については、検索構文と API ドキュメントを参照してください。さらに詳しいヒントについては、付録をお読みください。
$ lieu help
Lieu: neighbourhood search engine
Commands
- precrawl (scrapes config's general.url for a list of links: <li> elements containing an anchor <a> tag)
- crawl (start crawler, crawls all urls in config's crawler.webring file)
- ingest (ingest crawled data, generates database)
- search (interactive cli for searching the database)
- host (hosts search engine over http)
Example:
lieu precrawl > data/webring.txt
lieu crawl > data/crawled.txt
lieu ingest
lieu host
Lieu のクロールおよびプレクロール コマンドは、データを簡単に検査できるように標準出力に出力します。通常は、構成ファイルで定義されているように、Lieu が読み取るファイルに出力をリダイレクトします。一般的なワークフローについては、以下を参照してください。
config.crawler.webringにクロールするドメインを追加しますurlフィールドをそのページに設定しますprecrawlでクロールするドメインのリストを入力します: lieu precrawl > data/webring.txtlieu crawl > data/crawled.txtlieu ingestlieu host lieu ingestでデータを取り込んだ後、 lieu を使用して、 lieu searchで端末内のコーパスを検索することもできます。
以下に指定されている構成のtheme値を微調整します。
設定ファイルは TOML で書かれています。
[ general ]
name = " Merveilles Webring "
# used by the precrawl command and linked to in /about route
url = " https://webring.xxiivv.com "
# used by the precrawl command to populate the Crawler.Webring file;
# takes simple html selectors. might be a bit wonky :)
webringSelector = " li > a[href]:first-of-type "
port = 10001
[ theme ]
# colors specified in hex (or valid css names) which determine the theme of the lieu instance
# NOTE: If (and only if) all three values are set lieu uses those to generate the file html/assets/theme.css at startup.
# You can also write directly to that file istead of adding this section to your configuration file
foreground = " #ffffff "
background = " #000000 "
links = " #ffffff "
[ data ]
# the source file should contain the crawl command's output
source = " data/crawled.txt "
# location & name of the sqlite database
database = " data/searchengine.db "
# contains words and phrases disqualifying scraped paragraphs from being presented in search results
heuristics = " data/heuristics.txt "
# aka stopwords, in the search engine biz: https://en.wikipedia.org/wiki/Stop_word
wordlist = " data/wordlist.txt "
[ crawler ]
# manually curated list of domains, or the output of the precrawl command
webring = " data/webring.txt "
# domains that are banned from being crawled but might originally be part of the webring
bannedDomains = " data/banned-domains.txt "
# file suffixes that are banned from being crawled
bannedSuffixes = " data/banned-suffixes.txt "
# phrases and words which won't be scraped (e.g. if a contained in a link)
boringWords = " data/boring-words.txt "
# domains that won't be output as outgoing links
boringDomains = " data/boring-domains.txt "
# queries to search for finding preview text
previewQueryList = " data/preview-query-list.txt "自分で使用する場合は、次の設定フィールドをカスタマイズする必要があります。
nameurlportsourcewebringbannedDomains次の構成定義ファイルは、特別な要件がない限り、そのまま使用できます。
databaseheuristicswordlistbannedSuffixespreviewQueryListファイルとそのさまざまなジョブの完全な概要については、ファイルの説明を参照してください。
バイナリをビルドします。
# this project has an experimental fulltext-search feature, so we need to include sqlite's fts engine (fts5)
go build --tags fts5
# or using go run
go run --tags fts5 . 新しいリリースのバイナリを作成します。
./release.shソース コードAGPL-3.0-or-later 、Inter はSIL OPEN FONT LICENSE Version 1.1に基づいて利用可能であり、Noto Serif はApache License, Version 2.0としてライセンスされています。


