cape webservices
1.0.0
すべてのバックエンド Cape Web サービスのエントリポイント。
フロントエンドのデモはここにあります (バックエンドをすでに起動している場合にのみ機能します)。
Cape は、ドキュメントを自動的に「読み取る」ことで質問に答える質問応答モデルを管理するためのオープンソース ライブラリのスイートです。これは、大規模なデータセットでトレーニングされた最先端の機械読み取りモデルに基づいており、使いやすくし、ユーザーのフィードバックに基づいて改善するためのいくつかのメカニズムが含まれています。ポータブルであるように設計されており、1 台のラップトップまたは並列マシンのクラスターで動作して計算を高速化し、オープンソースであらゆる専門知識レベルで使用できるように設計されています。
これにより、ユーザーは次のことが可能になります
Cape を使用するにはいくつかの方法があります。
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/cape少なくとも 3 GB の RAM と少なくとも 2 つの最新の CPU コア (仮想の場合は 4 つ) をお勧めします。 Docker を使用している場合は、Docker の設定でメモリ リソースの制限を増やしてください。
管理ダッシュボードを含むスタンドアロン バージョンの Web アプリを実行できます。 docker をインストールした後、Cape イメージを更新して実行します。
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
これにより、バックエンドとフロントエンドの両方の Web サービスが起動され、デフォルトでは両方のトンネルも作成され、パブリック URL が出力されます。
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","タイムアウト":"15000"}}最新バージョンの Docker イメージをプルします (すべての依存関係と機械読み取りモデルをダウンロードするには少し時間がかかります): docker pull bloomsburyai/cape
Docker コンテナを実行し、次のコマンドを使用してその中で IPython コンソールを起動します: docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
レスポンダーのインポート: from cape_responder.responder_core import Responder
質問し、応答 (回答のリスト) を保存し、次のようにして最初の回答を表示します。responder response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
応答がどのようなものであるかをもう少し詳しく知りたい場合は、 print(response)使用して完全な応答を表示します。
Linux システムに Cape をネイティブにインストールするには、deployment/Dockerfile を確認してください。
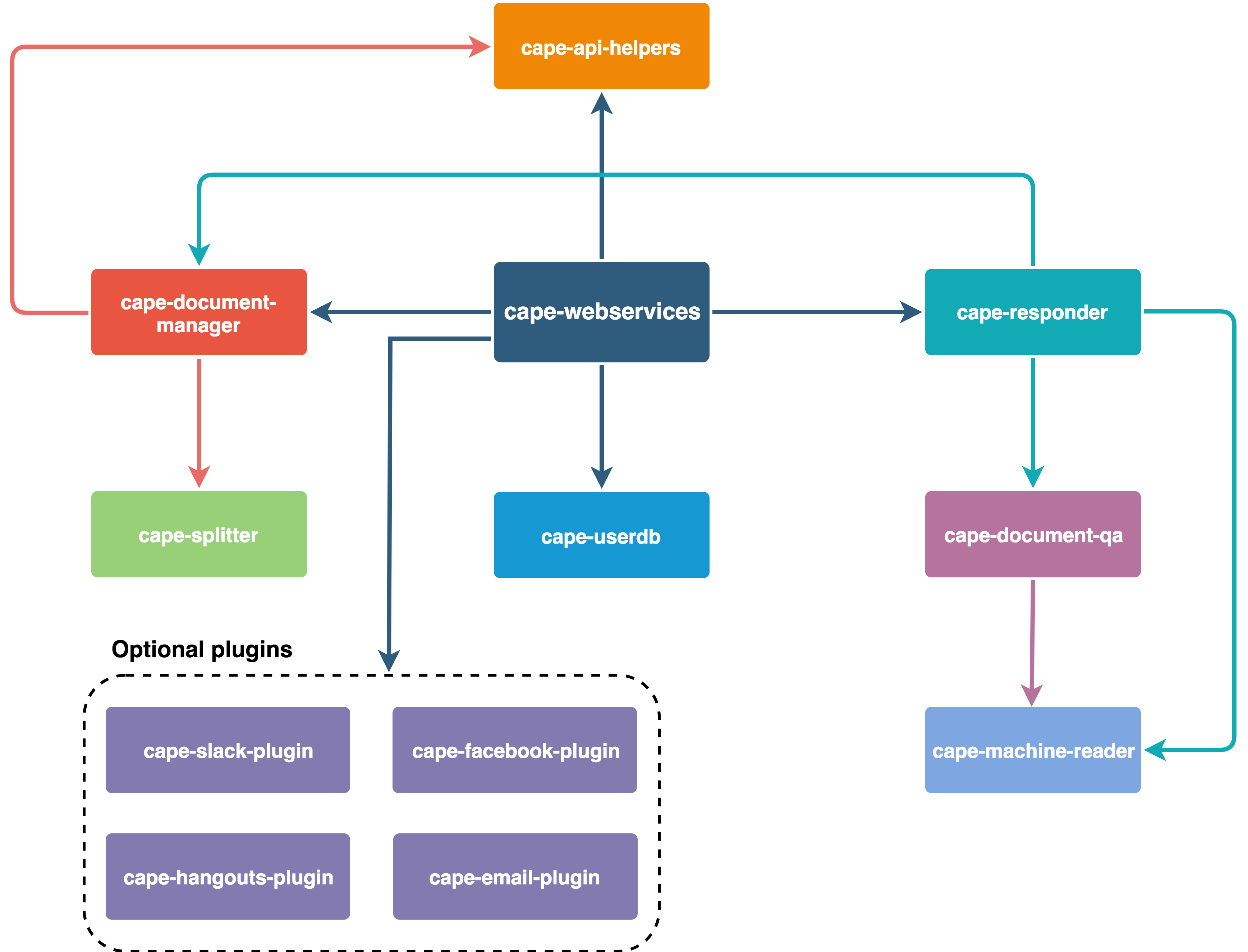
要約すると、Cape は次のように構成されています。


